1、修改默认逻辑关系q.op=OR
(q.op=OR)为OR后,分此后的检索式加号没了,是逻辑或关系,因此能够成功检索出来。这里OR一定要大写。

2、常用查询参数
- 参数q(必须)
patient_name:华梓程
- 排序参数 sort
默认按相关性(score)降序
单个条件:sort = score desc|asc 排序字段 降序|升序
多个条件:sort = doctor_order asc, time_asc_order asc, time_desc_order desc 先按doctor_order进行升序排,在按time_asc_order升序排,在按time_desc_order desc 降序排,排序方式
- 分页查询参数 start
在查询结果中的偏移记录,0开始,一般分页使用 - 分页查询参数 rows
指定返回结果的数据,配合start使用
- 结果类型查询参数 wt
类型:xml,json,python,ruby,php,csv
- 过滤查询参数 fq
在q查询结果中过滤出满足fq条件的数据,过滤的结果由solr进行缓存,对提高复杂查询速度非常有用。 例如:q=id:1&fq=sort:[1 TO 5]&fq=section:0,找关键字id为1 的,并且sort是1到5之间,section=0的。还能写成fq=+sort[1 TO 5] +section:0]。性能方面的考虑:每个fq下面的记录都会单独缓存。可以考虑把经常在一起的fq条件用+方式写。
- 过滤查询参数 fl
指定返回结果中的返回的字段field,默认*所有字段,score返回得分,
多个字段用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort或者fl=id title sort或者fl=id title,sort或者(4.0以后的版本支持)fl=id&fl=title&fl=sort。支持通配符如fl=tag*返回所有tag开头的字段。支持方法如fl=sum(x,y),所有支持的方法及对应的版本号见
- 默认查询参数 df
指定那个类型的处理器处理数据,例:/select,可以自定义搜索器,在通过df指定
- 缩进参数 indent
返回结果是否缩进,参数可以设置indent=true|false,控制台通过勾选
一般只有在返回结果为php,json,ruby中才使用
- debugQuery 参数
设置返回结果是否显示Debug信息
- 高亮参数hight
hl.fl:需要高亮的字段 多个可以通过逗号分隔,并且字段必须stored
hl.simple.pre
hl.simple.post
高亮的一些参数: - 统计参数facet
facet就像sql语句中的group一样,是对某一个字段进行group并count,即能够按照Facet的字段进行分组并统计
facet.query :true 开启分面
facet.field : 需要统计的字段
facet.prefix : 表示字段值的前缀.比如”facet.field=cpu&facet.prefix=Intel”,那么对cpu字段进行Facet查询,返回的cpu都是以”Intel”开头的,”AMD”开头的cpu型号将不会被统计在内
未展示的一些参数
facet.limit: 限制facet结果的数量,默认100,如果未负数,则不限制
facet.sort:表示facet结果已那种顺序返回
facet.mincount:Facet字段值的最小count,默认为0
date_facet
可以对某个时间段内的结果进行统计
facet.date:字段名
facet.date.start:开始时间
facet.date.end:结束时间
facet.date.gap:时间间隔
使用Date Facet时,字段名,起始时间,结束时间,时间间隔这4个参数都必须提供
- dismax查询解析器
查询解析器旨在处理用户输入的简单短语),并根据每个字段的重要性使用不同的加权。能够根据特定于每个用例的规则影响分数 - edismax查询解析器
- Raw query parameters
- The query API supports a lot more parameters than are shown on the admin
- UI. For instance, If you are doing a faceted search, there are only
- boxes for facet.query, facet.field, and facet.prefix ... but faceted
- search supports a lot more parameters (like facet.method, facet.limit,
- facet.mincount, facet.sort, etc). Raw Query Parameters gives you a way
- to use the entire query API, not just the few things that have UI input
- boxes.
-
在Raw Query Parameters参数里面输入时间段即可
facet.query=publishTime:[2017-06-05T00:00:00Z TO 2017-06-07T00:00:00Z]
&facet.query=publishTime:[2017-06-07T00:00:00Z TO 2017-06-09T00:00:00Z]
&facet.query=publishTime:[2017-06-09T00:00:00Z TO 2017-06-12T00:00:00Z]
&facet.query=publishTime:[2017-06-12T00:00:00Z TO 2017-06-15T00:00:00Z]

-
在Raw Query Parameters参数里面输入(按照20170605-20170615每隔三天进行一次统计的情况)
facet.range=publishTime&facet=true&facet.range.start=2017-06-05T00:00:00Z&facet.range.end=2017-06-15T00:00:00Z&facet.range.gap=+3DAY

3、solr的运算符
3.1不包含符号 -
例如不包含患者姓名: -patient_name:华梓程
3.2通配符号 *
表示任意字符的通配
[],{} 范围查询符号,前者包含,后者不包含
field:[ TO 15] 值小于等于15
field:[15 TO ] 值大于等于15
field:[ TO ] 所有
field:{1 TO 15] 大于1小于等于15
field:[1 TO 15} 大于等于1小于15
3.3指定字段符号 :
用户指定字段的值
name:wy,time:'2019-02-17T00:00:00Z'
:表示任意字段的任意数据,即所有值
3.4布尔符号 :
AND && 表示交集
OR || 表示并集
3.5符号 () :
用于构成子查询
fq:business_type:1 AND (id:38 OR id:40)
4、带score查询

5、edismax的mm查询
我们分析下在全文检索中两个重要的概念
查准率 召全率
在Lucene,Solr和ElasticSearch里面一般的分词的查询结果都会对这两个率做一个最好效果的调配,而这个默认的相关性评分规则就是:
-
相关性评分最高的排在前面,也就是查准的体现
-
相关性低的排在后面,也就是查全的体现
当然上面的结论,并不是百分百正确的,因为由于Lucene底层的设计,可能会导致一些奇怪的效果,就是最精确的没有排在最前面,这种问题大概只有10%的概率,我们可以索引两个字段,来避免这种问题,一个分词,一个不分词,查询时候,可以一起查询两个字段.:
北京车道沟北里小庄十里香饭店,分词后的情况如下:
车道
沟
北里
小庄
十里
香
饭店
注意,在整个索引库里面大部分要搜索的数据都含有北京和饭店两个词,所以这一下几乎会索引里面的所有数据都查询出来了,虽然查询排名还可以,但命中量太大了,超过4页之后几乎都是北京xxxx饭店了,跟主题的搜索没啥关系,所以我们可以采取一些策略来避免这种情况:
solr默认的搜索策略,是分词后的term的or的关系,最后结果集全部返回,如果我们改成and,那就是精确匹配了,但是有一点就是,如果是精确的匹配,某些时候用户输入的不完整的词就失去了全文检索的含义了,所以我们要采取一种综合的策略,既保证查准,又能保证召回,这样才能实现?
这个东西直接用我们的全文检索框架是没法实现的,有个思路不错,就是我们对要搜索的词,提取出句子的主干,然后主干部分在检索时,是必须要命中的,如果不命中,就算该条数据与查询的词,相关性不大,这个方法不错,但前提是你如何在大规模的数据里面精准的提出这些精确的主干词呢? 使用机器学习或者是文本挖掘? 答案是肯定能做,只是需要另外设计了,这是最好的解决搜索的命中数量太多的办法。 还有一个办法,是一种治标不治本的办法,比较容易实现,就是限制每次分词后最大匹配term的个数,也就是像
车道
沟
北里
小庄
十里
香
饭店
必须命中3个或更多的term,我才认为相关性更大,或者有一个百分比来限制80%以上的命中,就算此条记录不错。这个使用solr的edismax可以解决。
两种解决方法,如下
一: 使用edismax,在q里写完
name:北京xxxxx饭店后
在Raw Query Paramters参数里面写
defType=edismax&mm=80%25
然后查询即可,mm是最小匹配的数量,可以是个固定的值,也可也是个百分比。

各参数设置

查询:
在使用多个条件进行查询的时候,或者对查询内容进行分词的时候,Solr可能返回满足所有条件的结果或者满足部分条件的结果。solrQueryParser控制这一行为,这个属性是配置在schema.xml文件里的:
<solrQueryParser defaultOperator="AND"/>
- 属性值只可以是"AND"和"OR"。
AND将返回所有条件(分词)的结果
OR将返回满足任一条件的结果
这里使用OR操作,edismax的mm参数可以控制匹配度
不过这个配置项需要删掉,不知道是为什么,加上这个配置后,就算是"OR",也达不到想要的效果
查询的时候会自动对要查询的关键字进行分词,分词后它们的关系是OR
另外可以再在要查询的关键字前后加上"*"
OK查询完了,下面说说排序,妈的,最难的就是这个
##排序
最简单的排序就是设置sort参数,一般是sort一个时间,不过这里光一个sort参数是不能满足需求的,怎么办呢?
有三种实现方式:
-
定制Lucene的boost算法,加入自己希望的业务规则;
-
使用Solr的edismax实现的方法,通过bf查询配置来影响boost打分。
-
在建索引的schema时设置一个字段做排序字段,通过它来影响文档的总体boost打分。
具体怎么用的,可以去网上查,这里仅提供实现思路及解决方案
这三种实现方式归根到底其实就是就是Solr打分方式
这是采用第二种方案,使用edismax可以控制Solr的评分排序规则,
使用mm,来控制模糊查询的匹配程度
使用bq,来控制不同数据类型的重要性
使用qf,来控制不同的字段的重要性
使用bf,来控制日期的重要性
使用pf,来控制要查询的文本片段之间的关系
mm参数:
用来控制模糊查询的匹配程序如要搜索以下文本片段:我要买绝地武士星空仪
查询的时候会进行分词分成以下几个词:我,要,买,绝地,武士,星空,仪
一个文本片段分词分成了7个,mm配置为80%那么,7个词至少得匹配6个
###bq参数:
bq是boost query的简写,给符合查询条件的添加添加权重,
比如说bq设置为title:“shanghai”^10.0,它的意思就是给所有查询结果中条件字段名为title字段值为shanhai的条件添加权重为10.0,
多个条件的话用空格隔开
###qf参数:
这个参数用于指定q参数的条件要查哪个些字段,并给这些字段添加不同的权重
如:title^10.0意思为查询title字段,并给这个字段添加权重为10.0
多个字段用空格隔开
bf参数:
意思是通过数学公式来影响评分,不局限在qf中的字段
如:recip(div(ms(NOW+8HOUR,capture_time),86400000),1,1,1)
recpi函数:recip(x,m,a,b)转换为数据公式为:a/(m*x + b),a,b,m为常数,x为变量
div函数:除法div(a,b)表示:a/b
ms函数:表示两个日期相减
NOW+8HOUR表示当前时间加上8个小时,Solr使用的是UTC时区与比东8区少了8个小时
capture_time:Solr中一个数字类型的字段
86400000:一天时间的毫秒数
通过这个函数就可以根据capture_time生成不同的权重,capture_time离当时时间越近权重越大,越远权重越小,如果是未来则为负
###pf参数:
可以配置pf参数与qf参数一样
pf和qf参数的格式是一样的,不同的是pf会更加注重短语匹配
比如说:搜索"绝地武士星空仪"
绝地武士星空仪的权重就比星空绝地武士仪的权重大
6、suggest查询
全文检索搜索引擎都会有这样一个功能:输入一个字符便自动提示出可选的短语:
1、配置自己core文件夹conf下的managed-schema文件
这个是自己的字段:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="username" type="text_ik" indexed="true" stored="true"/>
2、新建一个suggest_username字段,并将username的值拷贝到suggest_username字段:
<field name="suggest_username" type="text_suggest" indexed="true" stored="true"/>
<copyField source="username" dest="suggest_username"/>
copyField的source表示源,dest表示目标。
3、新建一个fieldType专门用于搜索建议:
<fieldType name="text_suggest" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
</analyzer>
</fieldType>
4、 配置solrconfig.xml文件
solrconfig.xml文件也在新建核心core的conf文件夹下
找到 searchComponent 替换掉
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">xxxSuggester</str>
<str name="lookupImpl">AnalyzingLookupFactory</str>
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<str name="field">suggest_username</str>
<str name="weightField">suggest_username</str>
<str name="payloadField">id</str>
<str name="suggestAnalyzerFieldType">text_suggest</str>
<str name="buildOnStartup">false</str>
</lst>
</searchComponent>
在searchComponent中的suggester需要配置一些参数解释。
name ;suggest名字
lookupImpl;查找不同算法实现,根据需要选择。
dictionaryImpl;dictionaryImpl。
field;建议的字段,如果是对多个字段做建议,就把多个字段拷贝到一个字段里面。即在定义filed的时候,定义为允许多值。
weightField;表示权重。
payloadField ;用于返回某一个值。
suggestAnalyzerFieldType;field字段的类型。
buildOnStartup;启动的时候构建建议索引。
找到 requestHandler 替换掉 (一般都在searchComponent下面)
<requestHandler name="/suggest" class="solr.SearchHandler" startup="lazy" >
<lst name="defaults">
<str name="suggest">true</str>
<str name="suggest.count">10</str>
</lst>
<arr name="components">
<!-- 上面配置的searchComponent名字suggest -->
<str>suggest</str>
</arr>
</requestHandler>
这里 suggest就是上面配置的searchComponent名字suggest。
部分参数说明
suggest.build=true ;表示构建suggest的索引,全部构建会耗时。可优化。
suggest.dictionary=AnalyzingSuggester ;指明使用上面加入的suggester字典组件名字
suggest.q=a ;suggest查询内容
http://127.0.0.1:8983/solr/testCore/suggest?
suggest.build=true&suggest.dictionary=xxxSuggester&suggest.q=张

在solrconfig.xml文件中去掉或注释如图所示一行

功能说明
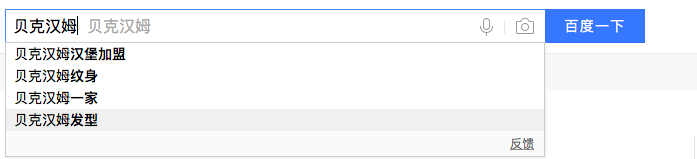
- 输入联想(搜索智能提示)是一个提高用户体验度的功能,用户在使用检索功能时输入一个字母或者汉字时系统会自动给用户推荐相关词汇。此功能减少了用户输入时的敲击次数,同时加快了输入速度,还可以给用户提供更多的检索选择。
- Solr是一个高集成、独立的企业级检索服务器。Solr配置简单而且性能强大。本文使用了Solr自带的Suggest组件来实现输入联想。Suggest是在Solr4之后才加入的,所以低于4的无法使用。本文使用的版本是4.3。
项目配置
- 在此默认已经配置好了solr环境。在solrhome下的solrcong.xml文件中加入如下配置:
<searchComponent name="suggest" class="solr.SpellCheckComponent">
<str name="queryAnalyzerFieldType">string</str>
<lst name="spellchecker">
<str name="name">suggest</str>
<str name="classname">org.apache.solr.spelling.suggest.Suggester</str>
<str name="lookupImpl">org.apache.solr.spelling.suggest.tst.TSTLookup</str>
<str name="field">GOODSNAME</str>
<float name="threshold">0.0001</float>
<str name="sourceLocation">suggest.txt</str>
<str name="spellcheckIndexDir">spellchecker</str>
<str name="comparatorClass">freq</str>
<str name="buildOnOptimize">true</str>
<str name="buildOnCommit">true</str>
</lst>
</searchComponent>
<!-- <requestHandler name="/suggest" class="solr.SearchHandler"> -->
<requestHandler name="/suggest" class="org.apache.solr.handler.component.SearchHandler">
<lst name="defaults">
<str name="spellcheck">true</str>
<str name="spellcheck.dictionary">suggest</str>
<str name="spellcheck.count">11</str>
<str name="spellcheck.onlyMorePopular">true</str>
<str name="spellcheck.extendedResults">false</str>
<str name="spellcheck.collate">true</str>
<!--<str name="spellcheck.build">true</str> -->
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>
配置名称解释:
- queryAnalyzerFieldType : schema.xml中的fieldType类型,如果加了这个选项,拼写检查时会调用这个fieldType的分词器,如果没有加,solr会取field属性上面filetype的分词器,这个时候还找不到,solr会创建一个按空格进行分词(SpellCheckComponent需要一个分词器才能运行),在这们项目中,我们现希望Analyzer不对查询做任何的改变,因此选择string。(网上也建议不要对他定义复杂的分词,如果指定的Analyzer很复杂的话,会导致suggest返回的结果不符合预期)
- name:就是取个名字,江湖中的人士都是让他等于suggest
- classname :org.apache.solr.spelling.suggest.Suggester(不要改动)
- lookupImpl :org.apache.solr.spelling.suggest.Suggester(不要改动)
- field : 说明只在这个字段上面做拼写检查
- threshold :限制一些不常用的词出现,值越大过滤词就越多,取值范围【0~1】官网默认是0.005
- comparatorClass : ellchecker组件中的comparatorClass参数可配置Suggest返回结果的排序,目前有如下几种可选方案:a .Empty – in which case the default is used. 默认就是这个、b.score – explicitly choose the default case 、c.freq – Sort by frequency first, then score. 通过频率的第一排序,然后得分 (开发时用这个)、d.A fully qualified class name – Provide a custom comparator that implements Comparato
- buildOnCommit : 取值true或者flase,当commit的时候,对拼写检查索引进行构建。(只有构建后,拼写检查才有效果)
- buildOnOptimize :当optimize的时候,对拼写检查索引进行构建。(只有构建后,拼写检查才有效果)
<str name="spellcheck">true</str>: 开启检查建议<str name="spellcheck.dictionary">suggest</str>:必须与searchComponent中spellchecker标签下suggest配置对应<str name="spellcheck.count">8</str>:配置拼写检查提示结果的个数(可以根据需要适当加大)<str name="spellcheck.onlyMorePopular">true</str>:等于true,可以根据权重排序,开发时我一般让他等于true<arr name="components"> <str>suggest</str> </arr>: handler拥有的 components,first-components,last-components这三个属性的剖,Solr的handler都是同过这三个属性来取他所依赖的components(组件)- 备注:handler在运行时,会加载5个默认的组件 ,a如果配置了components,则SOlr不会运行默认的5个组件。 而且你配置的first-components,last-components两个都是无效的。b.如果配置了first-components,SOlr会给handler添加5个默认的组件时,同时会添加first-components配置的组件,而且这个组件最先工作。c.同上,只不过放在最后工作
名称解释部分摘自solr suggest检查建议
注意* 按照上述配置后需要在solrcong.xml同级目录下放置一个suggest.txt文件。 suggest.txt文件内容必须是utf-8的字符格式,不能用windows的记事本编辑。可以用notepad一类工具编辑转UTF-8。方法如下:

Suggest.txt文本内容即为人工维护的热搜词,示例如下:
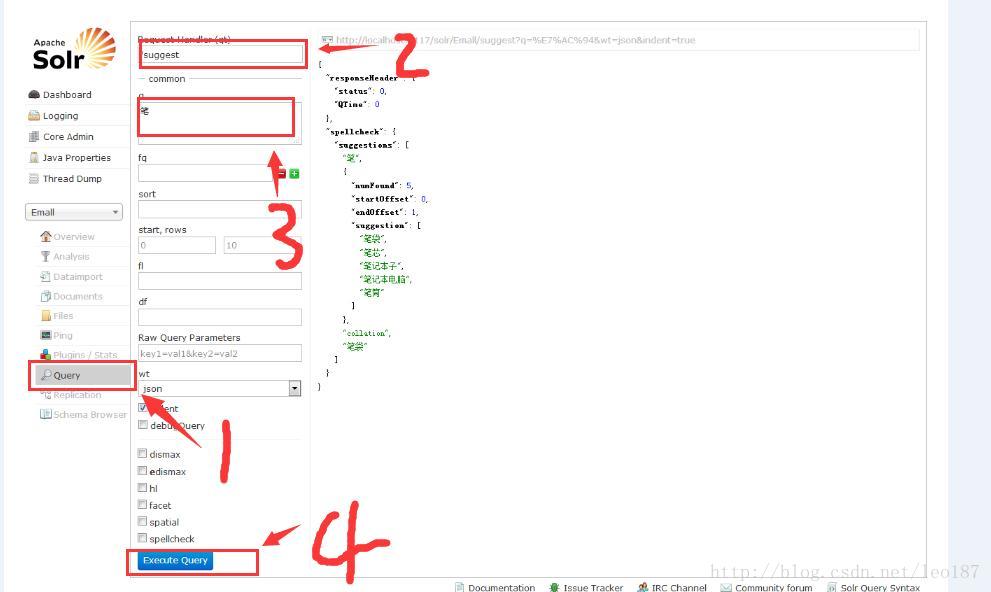
配置完成后重启solr服务器,访问solrAdmin。选择对应的库,点击Query、qt输入"/suggest"、q输入"笔"(搜索词)、点击Execute query查看效果。右侧输出框为结果数据。
代码调用
测试无误后即可将这一模块运用到项目中了。实现思想是用户在输入框输入内容后异步访问后天,后台调用solr后封装反回数据传到前台进行展示。java代码如下:
public List<String> searchSuggest(String word) throws SolrServerException {
SolrQuery params = new SolrQuery();
params.set("qt", "/suggest");
params.setQuery("GOODSNAME:"+word);//word为搜索词
QueryResponse queryResponse = getSolrServer(ResourceUtil.getConfigValueByName("solr.url"))
.query(params);
SpellCheckResponse suggest = queryResponse.getSpellCheckResponse();
List<Suggestion> suggestionList = suggest.getSuggestions();
List<String> suggestedWordList = new ArrayList<String>();
for (Suggestion suggestion : suggestionList) {
System.out.println("Suggestions NumFound: " + suggestion.getNumFound());
System.out.println("Token: " + suggestion.getToken());
suggestedWordList = suggestion.getAlternatives();
}
System.out.print("Suggested: "+queryResponse);
return suggestedWordList;
}
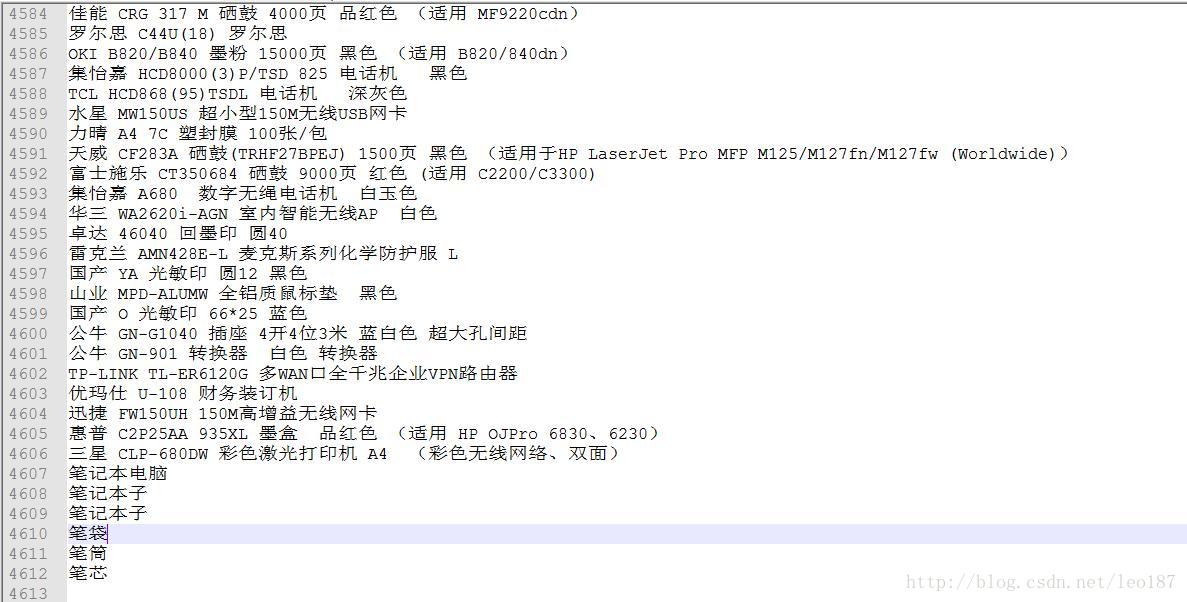
solr返回的结果如下:
{responseHeader={status=0,QTime=1},spellcheck={suggestions={笔{numFound=5,startOffset=10,endOffset=11,suggestion=[笔袋, 笔芯, 笔记本子, 笔记本电脑, 笔筒]},collation=GOODSNAME:笔袋}}}
- 后台将‘[笔袋, 笔芯, 笔记本子, 笔记本电脑, 笔筒]’做分割,将结果集合传到前台进行展示即可。