FastDFS 分布式文件系统
为什么我们需要它?
众所周知,在微服务架构中,从网关进来的请求会通过Ribbon进行负载均衡,可能造成你每次请求都有可能是不同的服务器处理的,因为,为了提高系统的吞吐量,某些服务被集群化,在这种情况下,当用户需要进行文件存储的时候,如果说把文件存储在当前处理请求的服务器中,那么下次当你想要获得这个文件的时候可能就获取不到了,因为你的这次请求可能交由另一个服务器处理了。为了解决在分布式系统中文的件存储这一问题,FastDFS应运而生
FastDFS是什么?
这是一款开源的分布式文件系统,负责对文件进行存储,主要功能包括:文件存储、文件同步、文件访问等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等、并且注重高可用、高性能,使用FastDFS可以很容易的搭建一套高性能的文件服务器集群提供上传、下载文件等服务
FastDFS的结构图:

FastDFS服务端有两个角色**:跟踪器(tracker)和存储节点(storage)。在Storage集群中,每一个Volume也称作一个组(group)**
FastDFS是怎么存储文件的?
存储过程
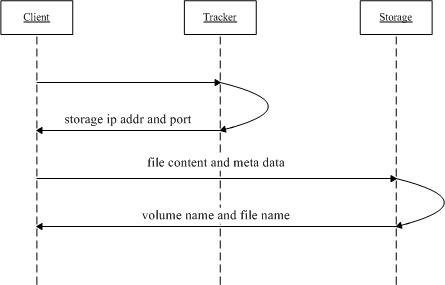
Tracker主要负责对请求进行调度,起到负载均衡的作用,类似于微服务中的注册中心(有心跳机制等等),它有每一个存储点的信息,在收到客户端发来的存储文件的请求时,会通过负载均衡算法来选择某一个Storage来存储该文件。
为什么是都是集群?
之前提到过高可用、负载均衡等名词,都是通过跟踪器(tracker)的集群化来保证的。当某一个Tracker宕机后,其他的Tracker可以继续对存储请求进行处理,这就保证了高可用。在决定文件要存到哪一个Storage的时候会使用随机或轮询等负载均衡的算法,来保证每个Storage所存储的数据比较均匀
之前也提到过冗余备份、线性扩容,是通过组(group)来保证的。首先,**想想为什么会出现组这个概念呢?**因为,当我们进行文件存储的时候,不是说把文件存储到某个Storage后就万事大吉了,**万一某台机器故障了怎么办?**那里面的数据可能就都要丢失了,这是一件非常严重的情况,为了解决这种情况,FastDFS中可以采用多个Storage来存储相同的文件,这样做的目的是进行数据备份,即冗余备份,解决了某个Storage出现故障时文件丢失的问题。这些存储相同文件的Storage就属于同一个组(group)。还有一种情况,**当存储的文件逐渐增多时,如何进行扩容呢?**根据FastDFS的结构,我们可以通过增加组(group)的方式来扩容