大数据基础学习入门
前言:
Java工程师并不一定要学习大数据, 这更像是一种 "锦上添花" 的技术。
可以说前景是比普通Java工程师大滴~ 针对大型企业实用性高, 中小企业并不是很需要!!
因为:
大数据,大数据首先要建立在数据量大的基础上!普通中小型项目数据量不大, 并体现不出大数据的强大!所以并不是很建议!
如阿里巴巴每天所处理的交易数据达到20PB ( 即20971520GB)。
传统数据处理技术为何不能胜任?
主要原因是关系型数据库是针对表、字段、行这种可使用二维表格表示的结构化数据而设计的,而大数据通常是针对文本这种非结构化数据而设计的。
大数据前提需要掌握:JAVASE Linux... 等技术。
本人并不是专业做大数据滴~, 有点失误错误的地方. 还请多多指教, 这里也只是基础入门,方便后期了解学习;
如果 Java(暂时笔记没有搬过来~) Linux 需要补课同学可以借鉴这里…
大数据的概念:
大数据( BigData) :
指 无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合。
简而言之就是数据量非常大! ! 大到无法用常规的工具处理:关系型数据库,数据仓库等...
需要新处理模式: 才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
主要解决:
海量数据的存储和海量数据的分析计算问题。
按顺序给出数据存储单位:
bit、Byte、KB、MB、GB、 TB、 PB、 EB、ZB、YB、BB、NB、DB.
1Byte= 8bit 1K = 1024Byte 1MB = 1024K1G= 1024M 1T = 1024G1P= 1024T …以此类推;
大数据特点 (4个V)
-
Volume(大量)
体量巨大, 按目前的发展趋势来看, 大数据的体量已经达到PB级 甚至是EB级!!!
举例 截至目前 :人类生产的所有印刷材料的数据量是200PB, 而历史上全人类总共说过的话的数据量大约是5EB -
Velcocity(高速)
产生和要求处理, 大量数据的速度快, 这是大数据
最显著的特征;
举例:天猫双十一: 2017年 3 分01秒,交易额超过100亿!! -
Variety(多样)
大数据的数据类型多样:
数据被分为结构化数据和非结构化数据。
相对于以往便于存储的以数据库/文本为主的结构化数据。
非结构化数据 越来越多,包括网络日志、音频视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求。 -
Value(低价值密度)
价值密度低:一百条数据记录中也许, 只有那一条是你需要的~
举例: 两小时的监控, 你想看的只是那三秒!
大数据也是一种方法论。
原则是:“一切都被记录,一切都被数字化、从数字里寻找需求、寻找知识、发掘价值” 这是一种
新的思维方式,不同于此前的专家方式
而是通过数据分析来得到结论:
这是大数据时代的一个显著特征, 这也就要求技术人员拥有能够从各种类型的数据中快速获得有价值的信息;
目前有很多大数据处理系统,可以处理大数据:
Hadoop,Spark,MongoDB,Storm,SAP Hana…等, 本次我们学习 Hadoop
大数据应用场景:
1、物流仓储:大数据分析系统助力商家精细化运营、提升销量、节约成本。
2、零售:分析用户消费习惯,为用户购买商品提供方便,从而提升商品销量。经典案例:纸尿布+啤酒案例
3、旅游:深度结合大数据能力与旅游行业需求,共建旅游产业智慧管理、智慧服务和智慧营销的未来。
…
Hadoop 体系结构:
Hadoop是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
主要解决: 海量数据的存储和海量数据的分析计算问题。
广义上来说, Hadop通常是指一个更广泛的概念————Hadoop生态圈

我凑, 图片里技术一个不认识!!
Hadoop生态圈
HDFS分布式文件系统整个Hadoop体系的基石。
MapReduce/YARN: 并行编程模型,
- YARN 是第二代的MapReduce框架,通常YARN也称为MapReduce V2
Hadoop.0 23.01版本MapReduce 重构- 老MapReduce称为MapReduce V1
Hive: 建立在Hadoop上的
数据仓库,提供 类似SQL语言 的查询方式查询Hadoop中的数据。
Pig: 一个对大型数据集进行分析、评估的平台主 要作用类似于数据库里的 存储过程。
HBase:全称Hadoop Database
- Hadoop 的分布式的、面向列的数据库,来源于Google 的关于BigTable的论文。
- 主要用于需要随机访问、实时读写的大数据。在后面章节还会详细介绍。
ZooKeeper: 是一个为分布式应用所设计的协调服务,主要为用户提供同步、配置管理、分组和命名等服务,减轻分布式应用程序所承担的协调任务。
————————————————————————————————————————————————
当然还有大量其他项目加入到Hadoop生态圈,如:Sqoop: 主要用于Hadoop与传统数据库(MySQL 等)间的数据传递。
Flume: 日志采集系统。
Spak: 前面提过,是一个相对独立于Hado的大数据处理系统,可单独进行分布式处理。它可以和HDFS很好地结合
.…对于初学者了解即可…

Hadoop发展历史
Hadoop创始人Doug Cutting 道格.卡丁

2003-2004年. Google公开了部分GFS和MapRebuce BigTable 的三篇论文思想和细节。
创始人是Doug Cutting Hadop现在是Apache 基金会顶级项目;
Hadoop是一个虚构的名字, 道格.卡丁孩子为其黄色玩具 ”大象“ 的名字;
Hadoop的核心
前面提过HDFS和MapReduce是Hadop两大核心
通过HDFS来实现: 对分布存储的底层支持,达到高速并行读写与大容量的存储扩展。
通过MapReduce实现: 对分布式并行任务处理程序支持,保证高速分析处理数据。
HDFS在MapReduce任务处理过程中: 提供了对文件操作和存储的支持。
MapReduce在HDFS的基础上实现了: 任务的分发、跟踪、执行等工作,并收集结果。
二者相互作用完成了:Hadoop分布式集群的主要任务
Hadoop的优势(4高)
1 )可靠性:
- Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素
- 或存储出现故障,也不会导致数据的丢失。
2)高扩展性:
- 在集群间分配任务数据,可方便的扩展数以千计的节点。
3 )高效性:
- 在MapReduce的思想下, Hadop是并行工作的,以加快任务处理速度。
4)高容错性: 能够自动将失败的任务重新分配。
Hadoop发现版本:
Hadoop发现版本比较混乱, 总的来说Hadoop分为两代

安装Hadoop
针对初学者来说、Hadoop运行环境的安装是个门槛。
很大程度上是由于大家对于Iiunx系统柜对不熟悉,而实际上Hadop本身的安装并不复杂。
前言:
Hadoop 大多运行在Linux服务器, 上滴所以在这之前你要先安装Linunx:(可以去看本人的笔记 或其它途径)
Hadoop运行是需要Java环境的, Linux上安装JDK当然是必不可少的了...
JDK Linux请参照:https://blog.csdn.net/qq_45542380/article/details/111173802
Hadoop目录结构:
安装前, 当然要了解目录结构低啦~
bin: 执行文件目录,包含hadoop dfs yarn 等命令,所有用户均可执行。
etc: Hadoop配置文件都在此目录(etc/hadoop/配置文件..)
include: 包含C语言接口开发所需头文件。
lib: 包含C语言接口开发所需链接库文件。通相当于,Java Jar库;
libexec: 运行sbin目录中的脚本会调用该目录下的脚本
logs: 日志目录,在运行过Hadoop后会生成该目录
sbin: 仅超级用户能够执行的脚本,包括启动和停止dfs yarn等 。
share: 包括doc和hadoop两个目录,
- doc目录包含了大量的Hadoo帮助文档:
- hadoop目录包含Hadoop所需所有的Jar 文件;
安装:
1. 使用工具WinSCP xftp 等工具,将Hadoop文件上传至:Linux中 urs/local中
2. 解压 改名方便操作:
解压
tar -zxvf hadoop-2.7.2.tar.gz
改名: hadoop
mv hadoop-2.7.2 hadoop (mv 旧文件名 新文件名字)

3. 配置 Linux 系统变量:
Linux 系统变量都在:
/etc/profile中配置
JDK就是在这里配置的, 首先cd hadoop进入hadoop文件中,pwd获取文件的绝对路径;
vi /etc/profile编辑Linux系统变量
往下拉↓↓
输入:
JDK是以前配置的必须要有的…(Hadoop是下面的)


export HADOOP_HOME=Hadoop安装路径..
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
4. 保存关闭, 使配置生效:
source /etc/profile 刷新资源配置
此时Hadoop在Linux 就配置好了可以:Hadoop version测试是否可以…不行关机重启!或继续下面配置Hadoop集群;
使用:本地运行模式,官方WordCount案例
1.创建在hadoop-2.7.2 解压根目录文件下面创建一个wcinput文件夹
mkdir wcinput
2.在wcinput文件下创建一个wc.input文件
cd wcinput
touch wc.input
3.编辑wc.input文件
vi wc.input在文件中输入如下内容:
hadoop yarn
hadoop mapreduce
atguigu
atguigu
保存退出::wq4.回到Hadoop 根目录下:
5.执行程序:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
bin/hadoop jar:执行一个jar文件
share/hadoop/mapred…文件所在的目录 examples因为加s了肯定是多个案例
wordcount :因为examples是多个案例我们这里执行的是wordcount 案例; Hadoop中的一种~
wcinput :输入文件夹,检测的文件夹
wcoutput:输出文件夹,名字可以随意取,一般会以执行的文件名字+output命名
注意:这里的woutput文件夹不能存在,如果存在将会报错,在执行命令时会自动创建wcoutput 文件夹
之后就是一阵的编译输出…6. 查看结果:
cat wcoutput/part-r-00000
注意单击模式 和伪分布模式, 操作不同配置了伪分布模式,这种方式就不行了…
这里是直接使用 Hadoop 命令来: 分析文件,只实用与单击模式~
分布式模式, 首先上传在文件系统上Hadoop命令解析文件系统上的文件…
配置Hadoop运行环境:
Hadoop分布式安装:
Hadoop有三种运行方式:
单机模式:
- 无须配置。Hadoop被视为一个非分布式模式运行的独立Java进程。
伪分布式:
一台设备,自己和自己玩(本次安装)
- 只有一个节点的集群,这个节点既是Master (主节点、主服务器)也是Slave (从节点、从服务器)。
- 可在此单节点上以不同的Java进程模拟分布式中的各类节点
完全分布式:
多台设备Hadoop集群
- 对于Hadoop, 不同的系统会有不同的节点划分方式。
- 在HDFS看来节点分为
NameNode (管理者)和DataNode (工作者),
其中NameNode只有一个,DataNode 可有多个:- 在MapReduce看来节点又分为JobTracker (作业调度者)和TaskTracker (任务执行者),
其中JobTracker只有一个,TaskTracker 可以有多个。- NameNode 和JobTracker可以部署在不同的机器上,也可以部署在同一机器上。
部署 NameNode和JobTracker 的机器是Master(主)
其它都是 Slave (从)
单机模式和伪分布式均不能体现云计算的优势,通常用于程序测试与调试。
本人并没有搞过集群,这里有可能会出错…
所以用了简单的伪分布式:
ok! 本人研究了好半天终于搞好了感谢大佬:借鉴大佬
首先勒,为了方便
伪分布式以及后面的集群容易分别 设备可以给设备改个名字(也可以不改随意)
修改主机名:
编辑:Linux系统设备名配置:
vi /etc/sysconfig/network
编辑修改主机名:
NETWORKING=yes
HOSTNAME=要修改的名字
编辑:主机映射
vi /etc/hosts
最后重启, 即可~ 主机名就会发生变化的拉~


开始伪分布式配置
hadoop/etc/hadoop目录下:
核心配置文件
Linux编辑文件:vi 文件
1. 配置:hadoop-env.sh 配置Hadoop JDK环境
修改25行,不一定准:export JAVA_HOME=/usr/local/jdk1.8.0 (填写自己JDK的路径)
2. 配置:core-site.xml 配置HDFS默认是空的
第一次打开
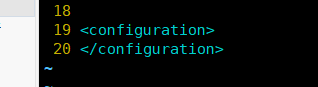
在 < configuration > </ configuration> 之间, 添加:
<!-- 指定HDFS中NameNode的地址 -->
<property>
<!-- fs.defaultFS:默认文件系统的名称,uri的权威是用来确定主机、端口等对于一个文件系统 -->
<name>fs.defaultFS</name>
<value>hdfs://Hadoop1:9000</value> <!-- Hadoop1:是我的主机名! -->
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value> <!-- hadoop.tmp.dir:临时存放路径! -->
</property>
3.配置:hdfs-site.xml
与上面类似:
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4. 启动集群:NameNode,DataNode
注意:Hadoop根目录下

结果出现这个成功:
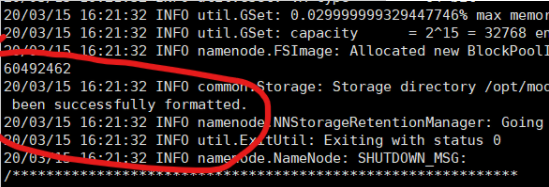
最后:
格式化NameNode(第一次启动时格式化,以后就不要总格式化)
bin/hdfs namenode -format
启动NameNode
sbin/hadoop-daemon.sh start namenode
启动DataNode
sbin/hadoop-daemon.sh start datanode
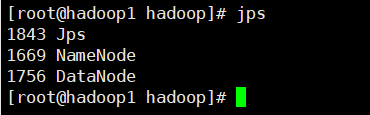
5. 查看启动结果
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
JPS
这就表示启动成功!
web端查看HDFS文件系统
查看前必须保证NameNode和DataNode已经启动
如果是本机访问可以使用:localhost / 127.0.0.1
而我使用的是 虚拟机外的主设备:windows系统 指定设备IP: 50070 访问;

ok 这样就表示成功了!
使用, 伪分布式操作集群:
在HDFS文件系统上创建一个input文件夹: 在文件系统上创建的文件, 不是你根目录哦! 你是看不见滴!
文件系统上递归创建一组文件:使用Hadoop bin目录下的命令,一般建议在Hadoop根目录下操作:
bin/hdfs dfs -mkdir -p /user/0817/input
在根目录下, 创建一个 abc.txt 文件并输入:…
vi abc.txt这是在根目录上创建存在的, 不过后面要上传文件系统上进行操作…
hadoop yarn
hadoop mapreduce
atguigu
atguigu
保存退出::wq
将本地 linux中的文件, 上传至文件系统上!!
bin/hdfs dfs -put ./abc.txt /user/0817input
此时可以查看:↓↓↓
运行MapReduce程序 同上面类似…
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/0817/input /user/0817/out
查看输出结果



配置集群 YARN
主要用于, 后面学习 MapReduce 后面讲解, 这里可以先把基本, 环境装好;
需要配置四个配置文件:
Hadoop 的核心配置文件有七个上面三 这里四个, 都是在 Hadoop/etc 目录下存放的核心配置文件!
1. 配置yarn-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0 (填写自己JDK的路径)
2. 配置yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<!-- 配置MapReduce的shuffle !!-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
3. 配置:mapred-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8.0 (填写自己JDK的路径)
4. 配置:mapred-site.xml
Hadoop/etc 中提供了: mapred-site.xml.template
template 模板: 用于方便操作…使用只需要 复制/修改 名为:mapred-site.xml 并进行配置
修改模板文件名
mv mapred-site.xml.template mapred-site.xml
并编辑 配置
vi mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
启动集群
启动前必须保证NameNode和DataNode已经启动:
启动ResourceManager
sbin/yarn-daemon.sh start resourcemanager
启动NodeManager
sbin/yarn-daemon.sh start nodemanager
Hadoop 警告 :
WARN hdfs.DFSClient: DataStreamer Exception org.apache.hadoop.ipc.RemoteException 解决办法:
1.看自己是否关闭防火墙了,防火墙没关可能导致这个原因:
2.在core-site.xml中没有配置hadoop运行时产生的文件的存储目录
如果上述都没问题的话,有可能是使用hadoop namenode -format格式化时格式化了多次造成那么spaceID不一致造成的:
这时候就需要停止集群stop-all.sh
然后删除在hdfs中配置的data目录(就是在core-site.xml中配置的hadoop.tmp.dir对应的文件)
重新格式化namenode(需要切换到Hadoop bin目录下执行:./hadoop namenode -format
最后重新启动hadoop集群再操作就可以啦!!
常用命令: Hadoop的sbin 服务命令目录下
启动Hadoop所有服务:./start-dfs.sh
关闭Hadoop所有服务:./stop-dfs.shlinux./执行命令;
这个解决了我的问题~