论文名称: Character Region Awareness for Text Detection
开源代码: https://github.com/clovaai/CRAFT-pytorch
一、CRAFT 思路
-
图像分割的思想, 采用
u-net结构, 先下采样再上采样;利用分割的方法,与图像分割有些不同的是,CRAFT 不是对整个图像进行像素级分类,而是做了回归,它有两个分支,一个是目标是字符的中心的概率(这里用概率可能不是很准确,或许说是距离字符中心的距离更好一些),另一个是字符之间的连接关系,然后经过一步后处理,得到文本的边界框。
-
非像素级分割, 将一个 character 视为一个检测目标对象,而不是一个 word(所有的 word 都由 character 构成),即不把文本框当做目标。这点有点类似 ctpn, 先检测很小的 bbox, 再利用 bbox 之间的关系进行 concat. 这样的好处是 只需要关注字符级别的内容而不需要关注整个文本实例, 从而使用小感受野也能预测长文本。 ctpn 检测算法也是对于长文本的检测效果会比较好. 与之相对应的就是 east 检测算法, 受限于感受野, 所以长文本的两端往往检测不准确。
该方法是通过精确地定位每一个字符,然后再把检测到的字符连接成一个文本达到检测的目的。由于该方法只需要关注字符以及字符之间的距离,不需要关注整行文本,所以不需要很大的感受野,对于弯曲、变形或者极长的文本都适用。由于要精确的检测到每一个字符,所以对粘连字符(比如孟加拉语和阿拉伯语)的检测效果并不是很好。
-
对于公开数据集大部分都是文本框级别的标注, 而非字符级别的标注, 本文提出了一种弱监督学习思路, 先利用合成样本进行预训练, 再将预训练模型对真实数据集进行检测, 得到预测结果, 经过处理后得到高斯热度图作为真实数据集的字符级标签。
二、CRAFT 网络结构
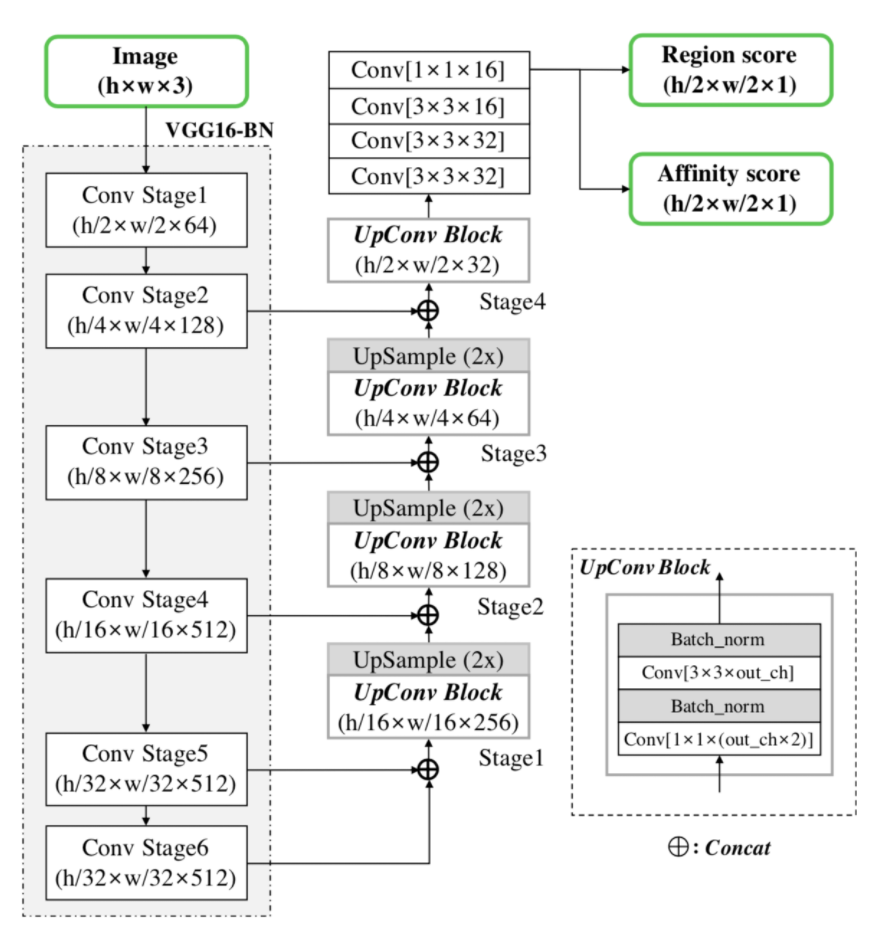
2.1 backbone
VGG16-BN, 上采样部分设计了一个 UpConv Block 结构,采用 VGG-16 进行下采样,总共进行了 5 次下采样, 所以在预测阶段的输入图片的预处理上, 会将输入图片的长和宽 padding 到距离长和宽的值最近的 32 的倍数。 比如输入图片为 500x400, 则会将图片 padding 到 512x416, 可以有效的避免分割中的像素漂移现象。利用 Unet 的思想, 对下采样的特征图再进行上采样和特征图 concat 操作, 最终输出 1/2 大小的顺序图,包含两个通道 score map:
- Region score :字符级的高斯热图,表示该点是字符中心的概率 (单字符中心区域的概率)
- Affinity score :字符间连接的高斯热图,可以认为是该点是两个字之间的中心的概率,相邻字符间空格的中心概率(相邻字符区域中心的概率)

(待会来写。。。)