目录
一、StreamSets简介
Streamsets是一款大数据实时采集和ETL工具,可以实现不写一行代码完成数据的采集和流转。通过拖拽式的可视化界面,实现数据管道(Pipelines)的设计和定时任务调度,Kettle缺点是通过定时运行,实时性相对较差。
需求:定时的开启一个管道流,此处希望也可以定时的关闭。目前找到的方式就是下面的这个组件,以下的案例也是基于此组件展开。

Cron Scheduler 使用的官方文档:点击前面
二、定时调度的案例
2.1总体管道流设计
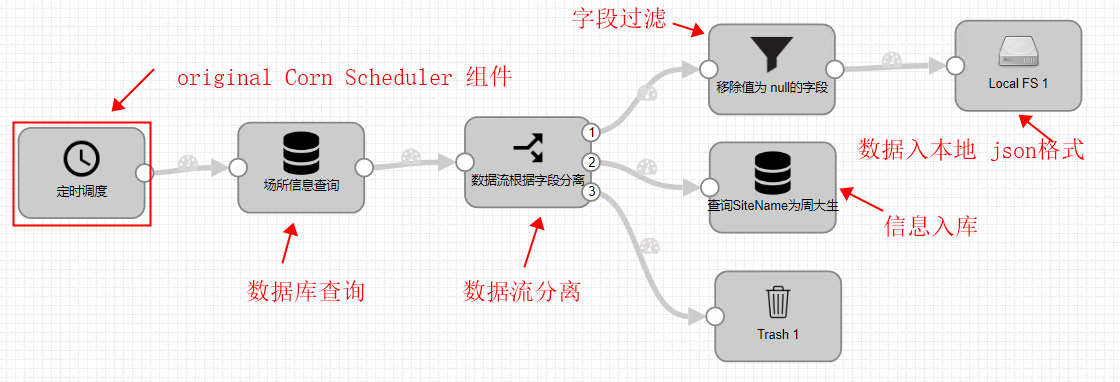
2.2具体步骤
1.origins- corn scheduler
选择定时的组件 ,origins 在一个管道流中只能有一个,其他的组件可以在 process,destination和executor 中选取。

说明:此处选择每小时的执行是方便演示,这个可以随意的调整,expression表达式是使用 Java开发的调度框架Quartz中定义。
expression表达式的使用可以见http://www.quartz-scheduler.org/documentation/quartz-2.3.0/tutorials/crontrigger.html
2.process- JDBC Look Up
(1)JDBC 连接地址

(2)数据库用户和密码

(3)MySQL驱动,此处事先要将mysql驱动上传上来

3.Stream Selector

4.管道流分支一------数据落入本地磁盘
(1)Output Fies 选择文件输出类型、文件的前后缀、输入文件夹,输入文件的大小,文件形成的时间间隔,此处我认为应该跟 Flume 差不多吧,可以配置文件形成的滚动时间间隔和大小两个因素来控制。

(2)Data Format 数据类型此处选择JSON

5.管道流过滤分支二-----过滤出的数据入库
(1)选择 destinations中的 JDBC Producer,JDBC 连接,指定数据库名,选择插入数据

(2)数据库的用户名和密码,还有就是驱动
6.管道流过滤分支三--垃圾桶
没什么好说的,就是其他的数据不要了呗。
2.3 运行
1.点击Start 启动 管道流

2.到达定时的时间点
没有到达管道流数据的流入时间,管道流静静的等待,时间一到数据涌入。

3.数据落入本地磁盘
管道流数据流入形成的是一个 tmp 的临时文件,文件的最终生成应该可以有文件大小和时间间隔控制。

数据流形成的文件,这个时候没有 tmp 标记

4.过滤出的数据写入新的表

我们可以看到Output2 中有7条数据流出二数据库中的数据记录条数也是 7条。

以上就是对 StreamSets 调度的简单示例,还在学习当中,不足之处肯定存在,仅供学习参考吧。
存在的问题:
- 网上看到数据库数据同步 数据重复问题,这个使用 Executors 中的 Pipeline Finisher 执行一次,我也没有验证
- 管道流开启时间调度器也启动了,怎么结束,让每天这个时间点去执行呢?这个 Core Scheduler 的 expression 表达式应该可以解决