
一、HBase表创建示例
如下创建了一张称为‘ win_kangll_day’的表,表中只有一个列族’d’,‘t’,紧接着的属性都是对此列族进行的设置。这些属性基本都会或多或少地影响该表的读写性能,创建‘win_kangll_day’使用了数据压缩、数据编码、预分区等属性设置。
create 'win_kangll_day',{NAME=>'d',VERSIONS => 1,COMPRESSION=>'SNAPPY',DATA_BLOCK_ENCODING => 'FAST_DIFF'},{SPLITS=> ['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f']}
alter 'win_kangll_day', {NAME => 't',VERSIONS => 1,COMPRESSION=>'SNAPPY',DATA_BLOCK_ENCODING => 'FAST_DIFF'},{SPLITS=> ['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f']}二、表创建中所用属性介绍
2.1.数据压缩
数据压缩是HBase提供的另一个特性,HBase在写入数据块到HDFS之前会首先对数据块进行压缩,再落盘,从而可以减少磁盘空间使用量。而在读数据的时候首先从HDFS中加载出block块之后进行解压缩,然后再缓存到BlockCache,最后返回给用户。写路径和读路径分别如下:
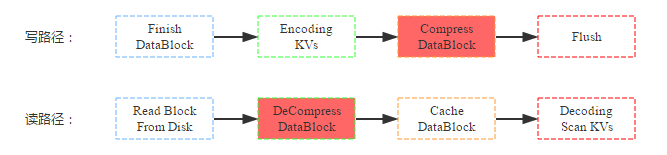
结合上图,来看看数据压缩对资源使用情况以及读写性能的影响:
(1) 资源使用情况:压缩最直接、最重要的作用即是减少数据硬盘容量,理论上snappy压缩率可以达到5:1,但是根据测试数据不同,压缩率可能并没有理论上理想;压缩/解压缩无疑需要大量计算,需要大量CPU资源;根据读路径来看,数据读取到缓存之前block块会先被解压,缓存到内存中的block是解压后的,因此和不压缩情况相比,内存前后基本没有任何影响。
(2) 读写性能:因为数据写入是先将kv数据值写到缓存,最后再统一flush的硬盘,而压缩是在flush这个阶段执行的,因此会影响flush的操作,对写性能本身并不会有太大影响;而数据读取如果是从HDFS中读取的话,首先需要解压缩,因此理论上读性能会有所下降;如果数据是从缓存中读取,因为缓存中的block块已经是解压后的,因此性能不会有任何影响;一般情况下大多数读都是热点读,缓存读占大部分比例,压缩并不会对读有太大影响。具体参考:HBase2.2 说明文档
可见,压缩特性就是使用CPU资源换取磁盘空间资源,对读写性能并不会有太大影响。HBase目前提供了三种常用的压缩方式:GZip | LZO | Snappy,下面表格是官方分别从压缩率,编解码速率三个方面对其进行对比:

2.2.Encode/Decode
除了数据压缩之外,HBase还提供了数据编码功能。和压缩一样,数据在落盘之前首先会对KV数据进行编码;但又和压缩不同,数据块在缓存前并没有执行解码,因此即使后续命中缓存的查询也是编码的数据块,需要解码后才能获取到具体的KV数据。写路径和读路径分别如下:
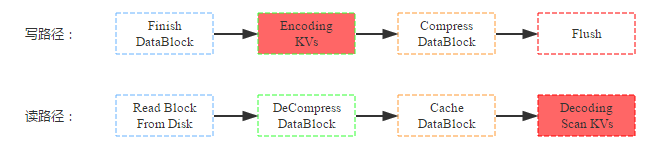
同样,来看看数据压缩对资源使用情况以及读写性能的影响:
(1) 资源使用情况:和压缩一样,编码最直接、最重要的作用也是减少数据硬盘容量,但是数据压缩率一般没有数据压缩的压缩率高,理论上只有5:2;编码/解码一般也需要大量计算,需要大量CPU资源;根据读路径来看,数据读取到缓存之前block块并没有被解码,缓存到内存中的block是编码后的,因此和不编码情况相比,相同数据block快占用内存更少,即内存利用率更高。
(2) 读写性能:和数据压缩相同,数据编码也是在数据flush到hdfs阶段执行的,因此并不会直接影响写入过程;前面讲到,数据块是以编码形式缓存到blockcache中的,因此同样大小的blockcache可以缓存更多的数据块,这有利于读性能。另一方面,用户从缓存中加载出来数据块之后并不能直接获取KV,而需要先解码,这却不利于读性能。可见,数据编码在内存充足的情况下会降低读性能,而在内存不足的情况下需要经过测试才能得出具体结论。
HBase目前提供了四种常用的编码方式:Prefix | Diff | Fast_Diff | Prefix_Tree
2.2.1.使用哪种压缩器或数据块编码器(官方)
使用的压缩或编解码器类型取决于数据的特征。选择错误的类型可能会导致您的数据占用更多的空间而不是更少的空间,并且可能会影响性能。
通常,您需要在较小的空间和更快的压缩/解压缩之间权衡选择。以下是一些一般性准则,这些准则是在
有关压缩和编解码器的文档指导。
- 如果您有长键(与值相比)或多列,请使用前缀编码器。建议使用FAST_DIFF。
- 如果值较大(并且未进行预压缩,例如图像),请使用数据块压缩器。
- 将GZIP用于不经常访问的冷数据。 GZIP压缩比Snappy或LZO占用更多的CPU资源,但提供更高的压缩率。
- 将Snappy或LZO用于经常访问的热数据。与GZIP相比,Snappy和LZO使用的CPU资源更少,但压缩率却不高。
- 在大多数情况下,默认情况下启用Snappy或LZO是一个不错的选择,因为它们的性能开销较低并且可以节省空间。
- 在Snappy于2011年由Google推出之前,默认值为LZO。 Snappy具有与LZO相似的质量,但表现出更好的性能
2.3.预分区
2.3.1.为何要预分区
- 增加数据读写效率,将数据写到不同的Region
- 负载均衡,防止数据倾斜,读写热点问题发生
- 方便集群容灾调度region
2.3.2.如何预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。
下面的例子就是手动的预分区:
create 'win_kangll_day',{NAME=>'d',VERSIONS => 1,COMPRESSION=>'SNAPPY',DATA_BLOCK_ENCODING => 'FAST_DIFF'},{SPLITS=> ['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f']}