ElasticSearch搜索引擎在web页面的应用实例
简介
在我的上一篇博文中,详细写到了ElasticSearch的日志服务的应用场景,本文讨论的是另一个场景:ElasticSearch作为搜索引擎在web项目中的使用。ElasticSearch作为搜索引擎最主要的作用是分词,即将一个段文字或一个词组分割成小粒度,并将这些经过分割再组合的小粒度的文字来匹配搜索结果,如有需要,还可以高亮显示。
效果如下:
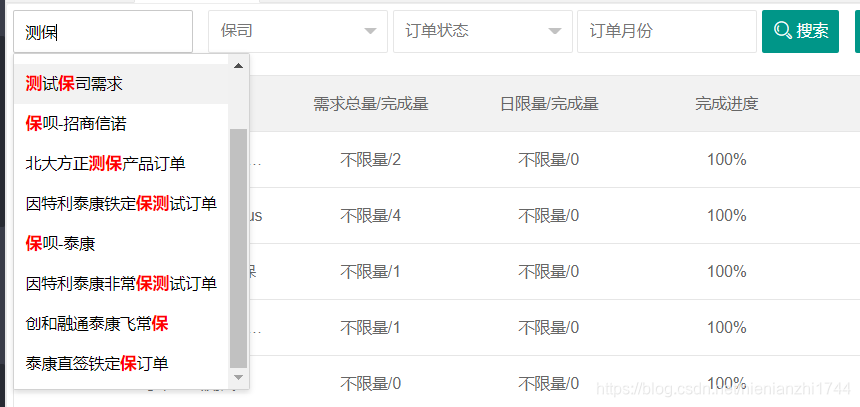
我这里是用ElasticSearch做了一个input的输入自动填充,自动匹配出来的下拉框就是ElasticSearch将我输入的词汇经过分割后在索引中匹配出来的结果。
使用
上面的demo基于以下环境开发:
后端:springboot:2.0.1.RELEASE
前端:layui
elasticsearch:6.8.1
demo中的红色高亮显示是在后端elasticsearch的代码中配置的。
demo中的input自动填充框组件为 autocomplete,可在layui 第三方组件平台自行下载。如果前端不是用的layui,比如vue的elementUI等,也都有各自适配的input自动填充组件。自动填充组件的匹配条目的数据源是后端elasticsearch的搜索结果。
elasticsearch的匹配到的数据最初是存在mysql数据库中,通过logstash将mysql的数据同步给elasticsearch,并以索引的形式存在。
1,修改logstash的配置
修改 …\logstash-6.3.0\bin目录下的logstash.conf文件。可以通过logstash同步mysql的数据给elasticsearch。如下
input {
stdin {
} }
input {
tcp {
type => "deliver_log"
host => "127.0.0.1"
port => 9250
mode => "server"
codec => json_lines
}
jdbc {
type => "baoji_company_requirements"
jdbc_connection_string => "jdbc:mysql://localhost:3306/baoji-staging?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&&useSSL=false"
jdbc_user => "root"
jdbc_password => "123456789"
jdbc_driver_library => "D:\Work\Project\elk\logstash-6.3.0\bin\mysql-connector-java-5.1.46.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
#取消小写
lowercase_column_names => false
#要执行的sql语句
statement => "select * from baoji_company_requirements"
#这里可以定制定时操作,比如每10分钟执行一次同步(分 时 天 月 年)
schedule => "*/10 * * * *"
}
}
# output {
stdout {
codec => rubydebug } }
output {
stdout{
codec =>rubydebug}
# 这个if判断容易写成if[type=="deliver_log"],注意中括号内只有type这个属性名,不包含条件。
# deliver_log是将收集到的日志输出到日志对应的索引中
if[type]=="deliver_log"{
elasticsearch {
hosts => ["localhost:9200"]
index => "logback-%{+YYYY.MM.dd}"
user => "elastic"
password => "gJRr45HLoRVzoqyRaWxO"
}
}
# baoji_company_requirements是将收集到的表数据输出到表名对应的索引中
# 我们此处直接将要创建的索引名index写成表名,方便记忆与理解
if[type]=="baoji_company_requirements"{
elasticsearch {
hosts => ["localhost:9200"]
index => "baoji_company_requirements"
user => "elastic"
password => "gJRr45HLoRVzoqyRaWxO"
}
}
}
以上配置完成后,记得启动ElasticSearch服务和Logstash服务。启动logstash服务成功后会立即自动扫描数据库中的数据;在kibana配置索引模式后也可以看到扫描到的同步后的mysql数据。
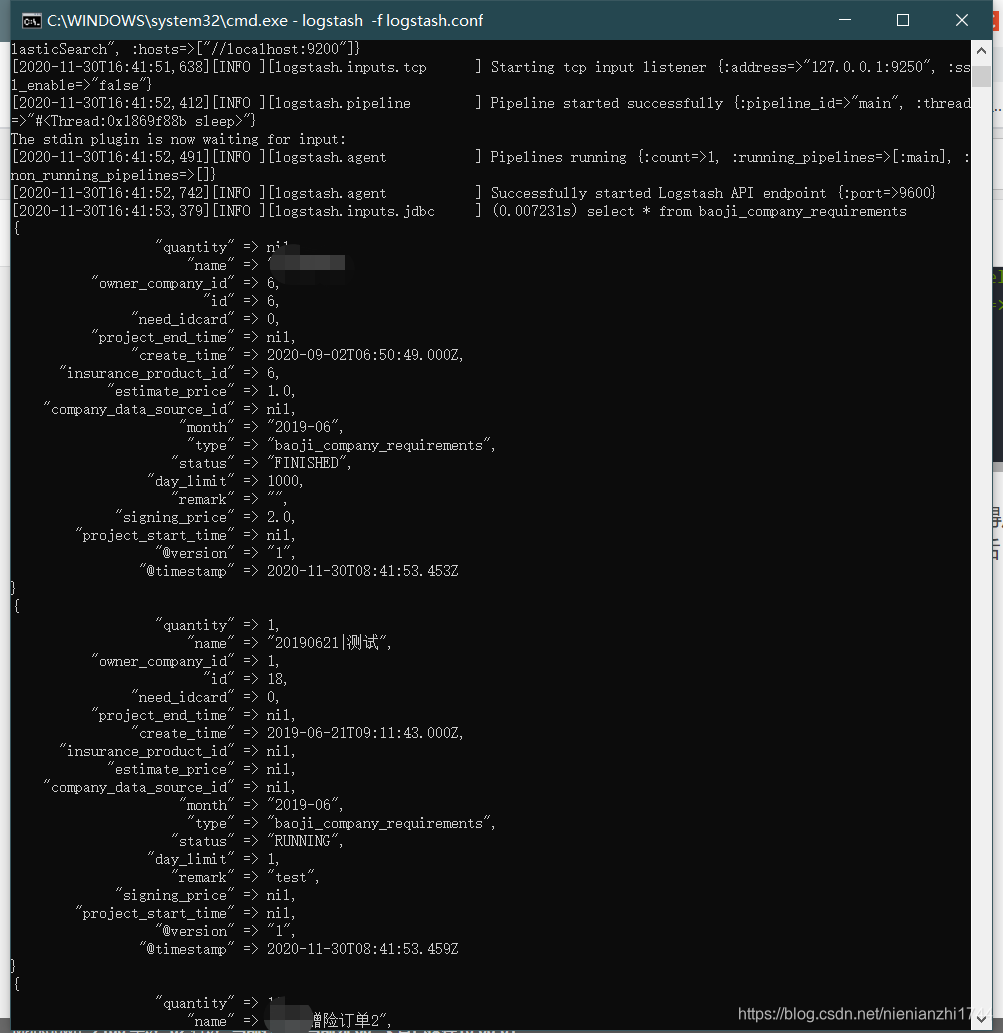
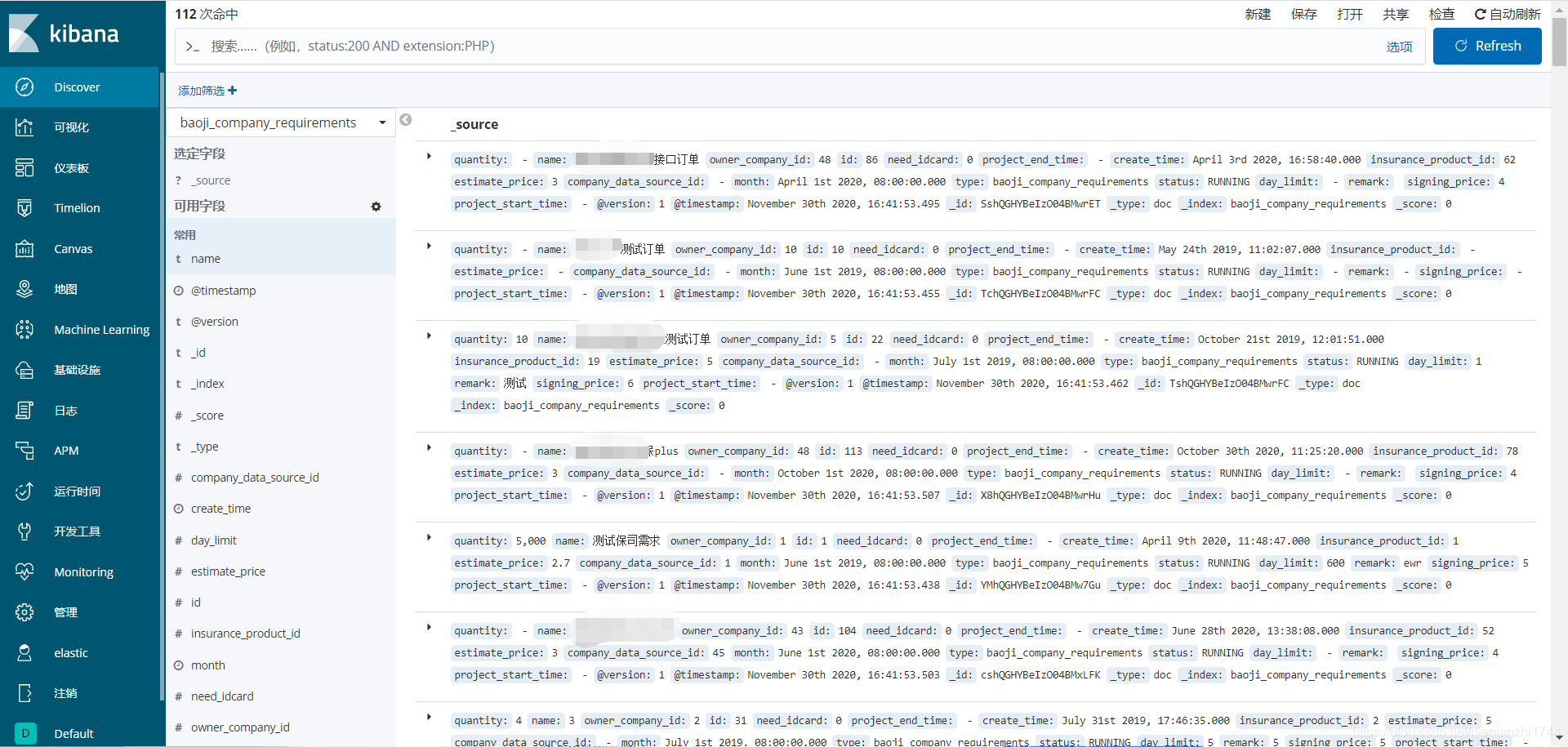
2,修改springboot的配置文件
先看项目结构:
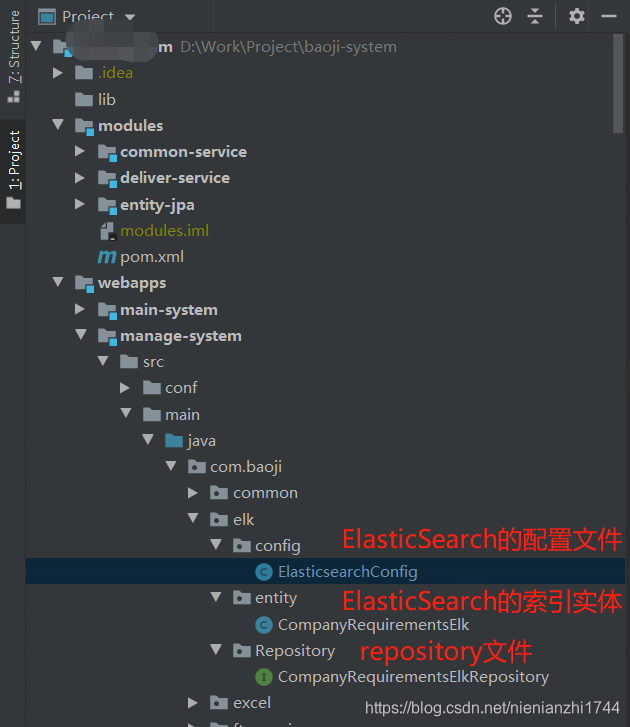
我的项目是多模块项目,本文的demo在图上的manage-system模块。除了图上的三个文件,还有该模块下的pom文件以及application.properties配置文件需要改动
1,修改pom文件,添加依赖(如果项目有多个模块,修改需求所在的当前子模块)
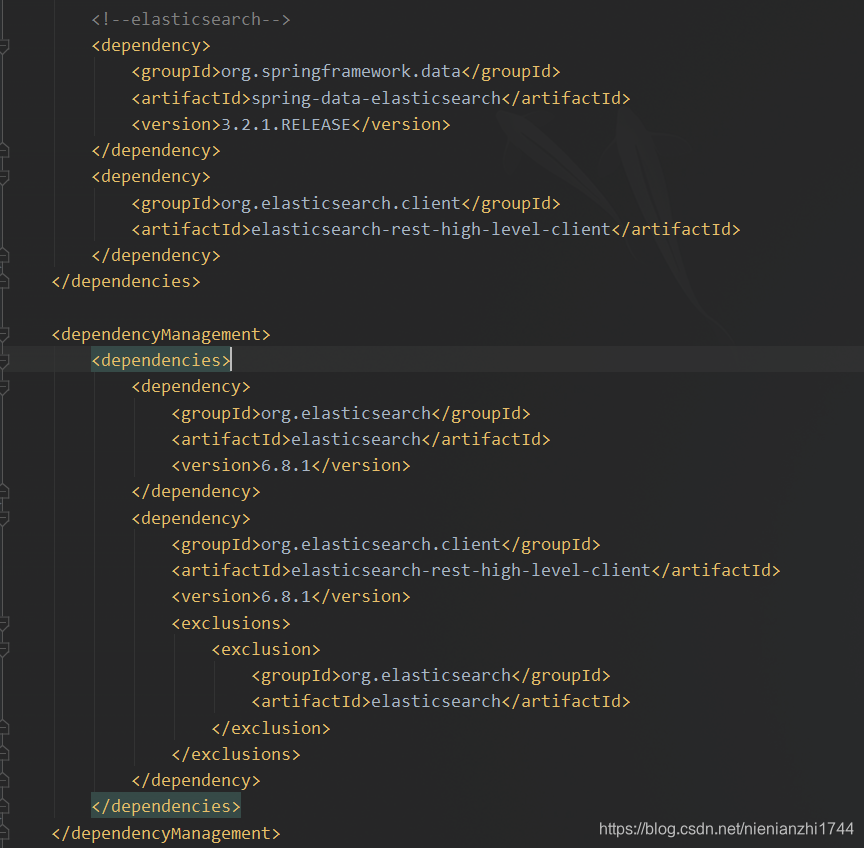
<!--elasticsearch-->
<dependencies>
<!-- 其他不相关的依赖省略... -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>3.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
</dependencies>
<!--版本控制-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.8.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.8.1</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
</dependencyManagement>
(使用dependencyManagement管理版本是为防止启动时报错:Caused by: java.lang.ClassNotFoundException: org.elasticsearch.common.xcontent.DeprecationHandler)
2:修改配置文件,添加属性
elasticsearch.host=127.0.0.1
elasticsearch.port=9200
elasticsearch.search.pool.size=5
elasticsearch.username=elastic
elasticsearch.password=gJRr45HLoRVzoqyRaWxO
(username和password在我的 上一篇博客有提到)
3,代码文件
代码文件最基本的要有(参上图目录结构):
1.连接elasticSeartch的配置文件(意义上类似jdbc的配置类)
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories;
@Configuration
@EnableElasticsearchRepositories(basePackages = "com.xxx.elk.entity")
public class ElasticsearchConfig {
@Value("${elasticsearch.host}")
private String esHost;
@Value("${elasticsearch.port}")
private int esPort;
@Value("${elasticsearch.clustername}")
private String esClusterName;
@Value("${elasticsearch.search.pool.size}")
private Integer threadPoolSearchSize;
@Value("${elasticsearch.username}")
private String userName;
@Value("${elasticsearch.password}")
private String password;
@Bean
public RestHighLevelClient client(){
/*用户认证对象*/
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
/*设置账号密码*/
credentialsProvider.setCredentials(AuthScope.ANY,new UsernamePasswordCredentials(userName, password));
/*创建rest client对象*/
RestClientBuilder builder = RestClient.builder(new HttpHost(esHost, esPort))
.setHttpClientConfigCallback(new RestClientBuilder.HttpClientConfigCallback() {
@Override
public HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpAsyncClientBuilder) {
return httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
}
});
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
@Bean(name="elasticsearchTemplate")
public ElasticsearchRestTemplate elasticsearchRestTemplate(){
return new ElasticsearchRestTemplate(client());
}
}
2.索引实体类(意义上类似mysql数据库表对应的实体类)
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import javax.persistence.Id;
import java.util.Date;
/*Document注解中的type为什么是doc呢,因为elasticsearch7默认不在支持指定索引类型,默认索引类型是doc,
createIndex为false即不主动创建索引,因为这个索引在logstash启动的时候就被创建过了*/
@Document(indexName = "baoji_company_requirements",type = "doc",createIndex = false)
public class CompanyRequirementsElk {
@Id
private Long id;
@Field(name = "name",type = FieldType.Text,analyzer = "ik_max_word")
private String name;
@Field(name = "create_time",type = FieldType.Date)
private Date createTime;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
}
(索引实体并没有将elasticSearch索引中所有的字段都取出来,我这里只取了三个字段,因为需要自动填充的name字段,实际我这里只写一个name就够了。)
3 .repository(意义上类似dao层的数据访问文件)
import com.baoji.elk.entity.CompanyRequirementsElk;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface CompanyRequirementsElkRepository extends ElasticsearchRepository<CompanyRequirementsElk, Long>{
}
4 .业务代码
@GetMapping("getRequirementNames")
public PageResult<Map> getRequirementNames(String keywords){
/*自定义返回结果*/
List<Map> returnList=new ArrayList<>();
/*查询*/
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", keywords);
Iterable<CompanyRequirementsElk> search = companyRequirementsElkRepository.search(matchQueryBuilder);
search.forEach(companyRequirements -> {
/*自定义返回结果*/
Map companyRequirementMap=new HashMap();
companyRequirementMap.put("name",companyRequirements.getName());
returnList.add(companyRequirementMap);
});
return new PageResult(returnList);
}
以上的代码就实现了分词搜索,MatchQueryBuilder 会默认使用最大分词粒度进行分词。但仅仅是分词搜索似乎不够酷,所以我们将分隔的词汇加上高亮显示。改造如下:
@Autowired
ElasticsearchConfig elasticsearchConfig;
@GetMapping("getRequirementNames")
public PageResult<Map> getRequirementNames(String keywords){
/*自定义返回结果*/
List<Map> returnList=new ArrayList<>();
/*高亮的样式及匹配字段设置*/
HighlightBuilder highlightBuilder=new HighlightBuilder()
.field("name")
.preTags("<span style='color:red;font-weight:bold;font-size:15px;'>").postTags("</span>");
/*将高亮的配置加入到查询中*/
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.highlighter(highlightBuilder);
/*查询条件设置*/
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", keywords);
searchSourceBuilder.query(matchQueryBuilder);
/*查询请求,参数为 索引名称,即要查哪个索引库*/
SearchRequest searchRequest = new SearchRequest("baoji_company_requirements");
searchRequest.source(searchSourceBuilder);
/*使用RestHighLevelClient连接elasticSearch服务*/
RestHighLevelClient restHighLevelClient=elasticsearchConfig.client();
SearchResponse searchResponse=null;
try {
/*调用使用RestHighLevelClient连接elasticSearch服务的查询接口*/
searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
LOGGER.error(e.getMessage());
}
/*获取到命中结果的集合*/
Iterator<SearchHit> searchHitIterator = searchResponse.getHits().iterator();
/*遍历命中结果*/
while(searchHitIterator.hasNext()){
/*每个查询命中对象*/
SearchHit searchHit = searchHitIterator.next();
Map<String, HighlightField> hightlightFields = searchHit.getHighlightFields();
/*命中的属性*/
HighlightField titleField = hightlightFields.get("name");
/*提取拼接成String*/
String hightStr="";
Text[] text=titleField.getFragments();
if (text != null) {
for (Text str : text) {
hightStr += str.string();
}
}
/*自定义返回结果*/
Map companyRequirementMap=new HashMap();
companyRequirementMap.put("name",hightStr);
returnList.add(companyRequirementMap);
}
/*PageResult是对返回结果的一层自定义封装。这里可直接返回list*/
return new PageResult(returnList);
}
上面controller中的代码经过debug可以发现,我们提取的结果已经是包含了高亮样式的结果。
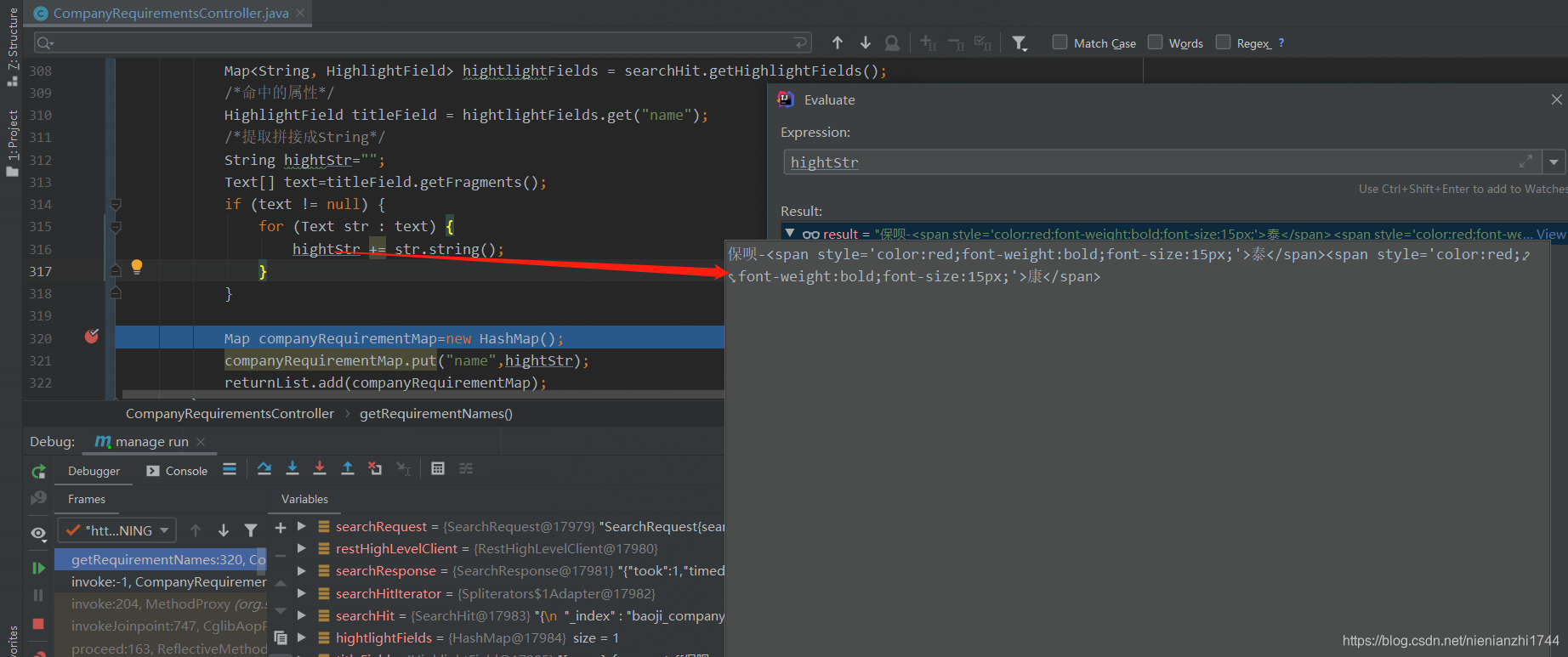
到此为止:elasticSearch搜索的分词+高亮的后端代码已经完成。至于前端,前端框架各有不同,只要能保证从这个业务接口取到了返回数据就好了。
以layui的前端为例:
jquery部分
autocomplete.render({
elem: $('#requireMentId'),//标签id
cache: false,//不启用缓存
url: base_server +'companyRequirements/getRequirementNames',//接口地址
params:{
access_token: admin.getToken()},//接口请求参数,组件内置了输入框的一个名为keywords的参数
response: {
code: 'code', data: 'data'},//接口返回参数格式
template_val: '{
{d.name}}',//匹配条目选中的值
template_txt: '{
{d.name}}',//匹配条目显示的值
onselect: function (resp) {
console.log(resp);
}
});
html部分
<input id="requireMentId" autocomplete="off" class="layui-input" type="text" placeholder="订单名称"/>
效果图:

总结
这个类似淘宝京东的宝贝搜索框输入和百度搜索等的输入,做elasticsearch搜索的分词+高亮是一个很有成就感的事情,同时再次对elasticSearch感到震撼,elasticSearch基于Lucene搜索引擎实现。学无止境,去研究Lucene去了…