1.diff命令(文件,目录对比命令):
用法:
diff [options] files1 files2 | directory1 directory2
输出信息:
[num1,num2] [ a | c | d ] [num3,num4]
num1,num2 ##第一个文件中的行
a ##添加
c ##更改
d ##删除
< ##第一个文件中的内容
> ##第二个文件中的内容
num1,num2 ##第一个文件中的行
num3,num4 ##第二个文件中的行
常用参数:
-b ##忽略空格
-B ##忽略空行
-i ##忽略大小写
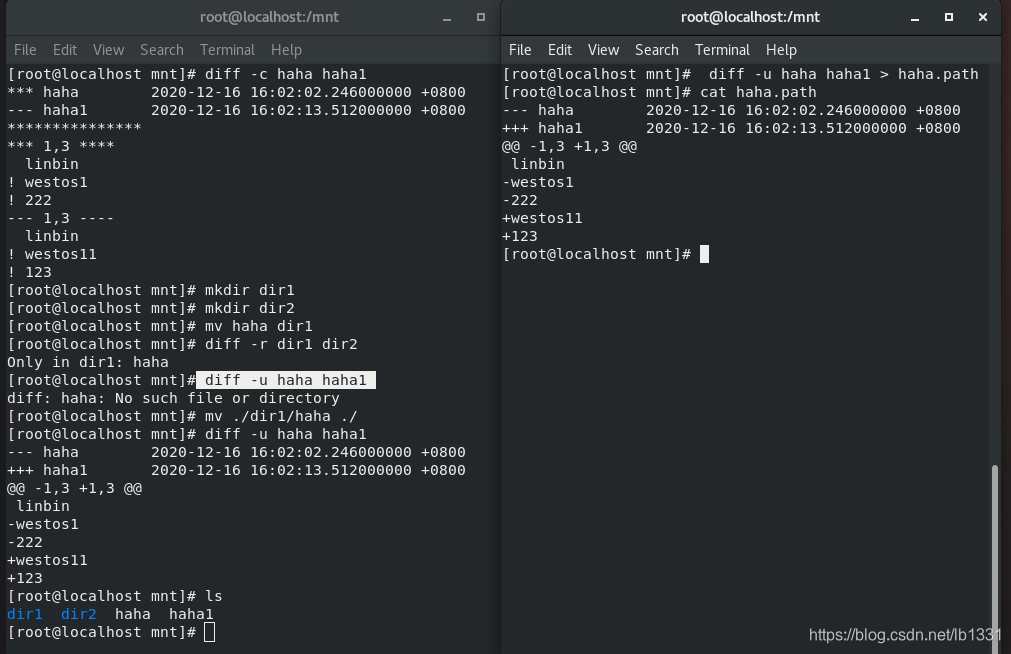
-c ##显示文件所有内容并标示不同
-r ##对比目录
-u ##合并输出 (常用来生成补丁文件)
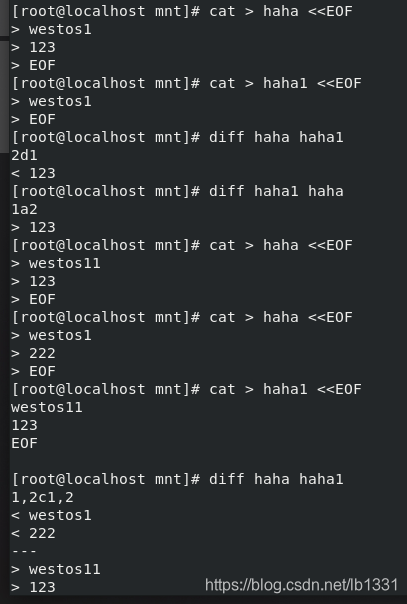
如图:2d1 表示: 第一个文件(haha)第2行与第二个文件(haha1)的第一行来说:删除了第一个文件中的123(<123):
2.patch 命令:(补丁)
dnf install patch -y
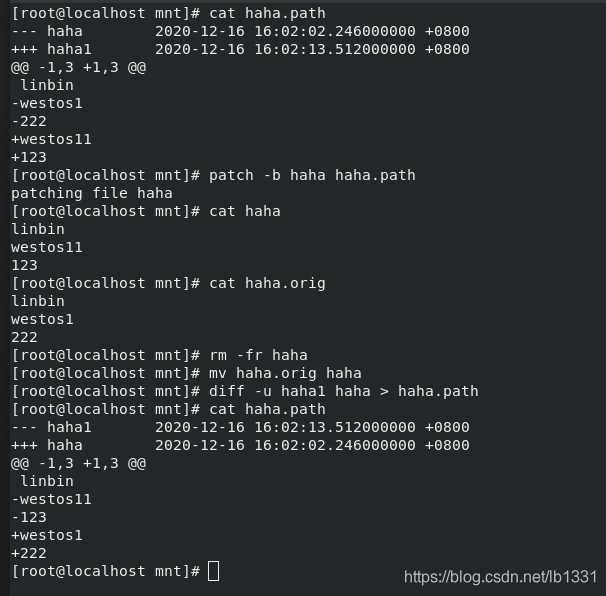
patch 原文件 补丁文件
-b 备份原文件 (备份文件为 源文件名.orig)
注意: diff -u haha haha1 与 diff -u haha1 haha 生成的补丁文件不同;(离参数近的是模板)
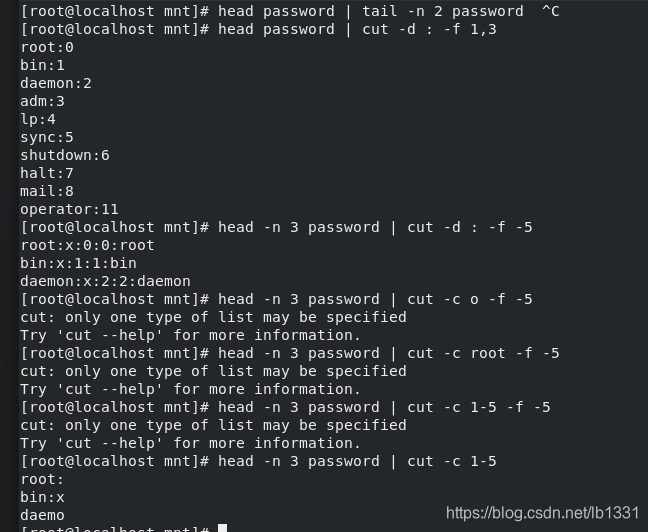
3.cut 命令:(截取,筛选)
head + tail 可以截取查看文件的行 cut 截取查看文件的列
-d : ##指定:为分隔符
-f ##指定显示的列 5第五列 | 3,5 3和5列 | 3-5 3到5列 | 5- 第五列以后 | -5 到第五列
-c ##指定截取的字符(数字用法同-f) cut -c 1-5 显示第1到5个字符
如图:head + tail 可以截取查看文件的行 cut 截取查看文件的列:
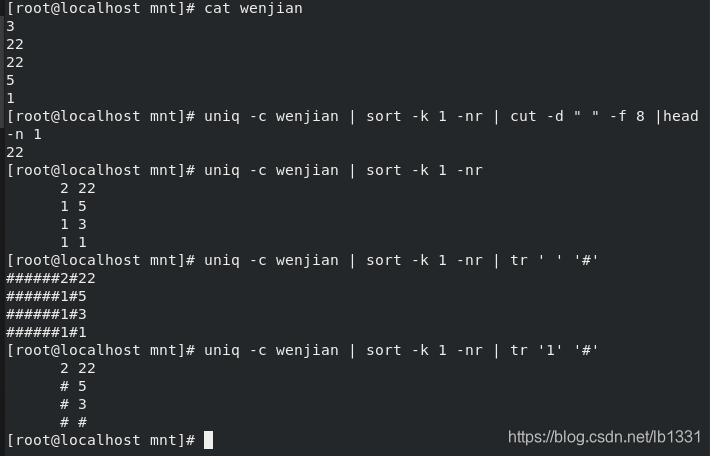
4.sort :(排序命令);uniq:(查重命令)
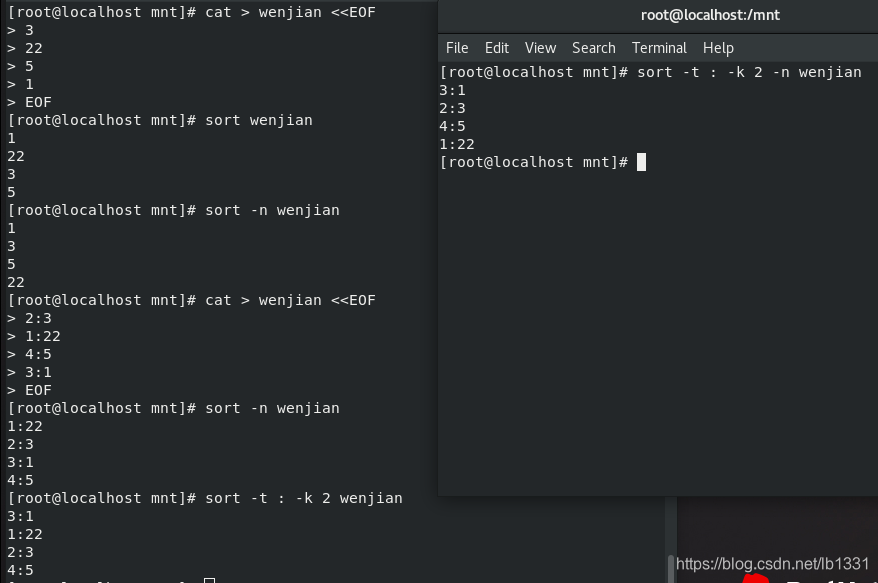
sort :
-n ##纯数字排序
-r ##倒叙
-u ##去掉重复
-o ##输出到指定文件
-t ##指定分隔符
-k ##指定排序的列
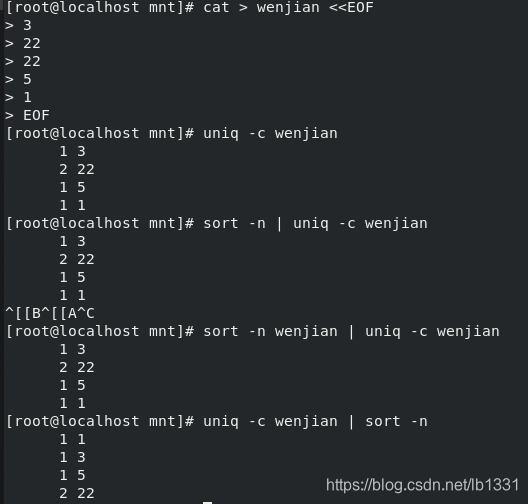
uniq :
-c #合并重复并统计重复个数
-d #显示重复的行
-u #显示唯一的行
uniq命令与sort命令一起使用:
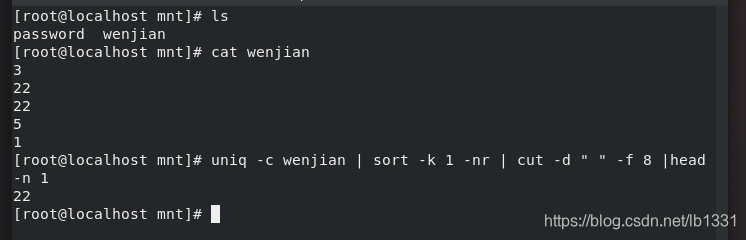
示例如下图: 输出文本中出现次数最多的数:
5.tr命令:(转换大小写,字符,符号)
tr 'a-z' 'A-Z' ##小写转大写
tr 'A-Z' 'a-z' ##大写转小写
tr ' ' '*' ##空格转换成*
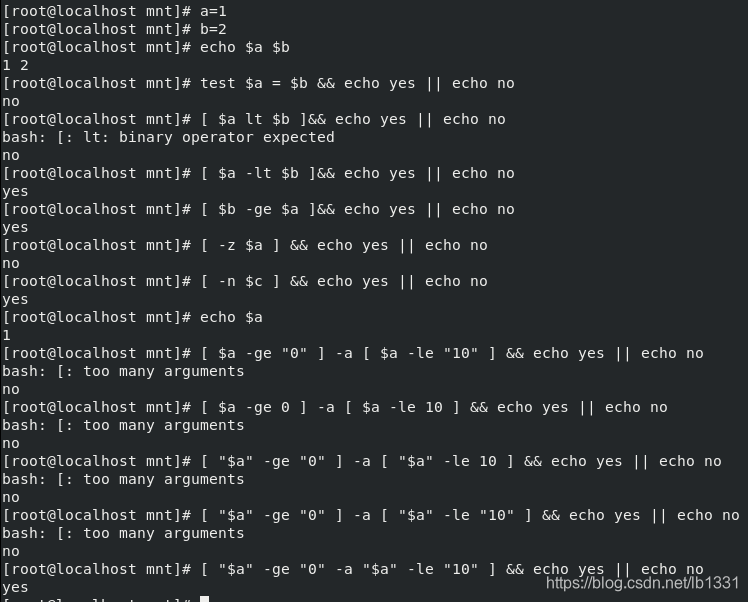
6.test对比命令与&&(是),||(非) :
test = [] ##[ ] 就相当于test命令
test $a = $b = [ $a = $b ] 注意:[ ] 两端有空格
test的数字对比
=
!=
-eq ##等于
-ne ##不等于
-le ##小于等于
-lt ##小于
-ge ##大于等于
-gt ##大于
test的条件关系
-a ##并且
-o ##或者
test对值是否为空的判定
-n ##nozero 判定内容不为空
-z ##zero 判定内容为空
&& 符合条件作动作,是
|| 不符合条件作动作,非
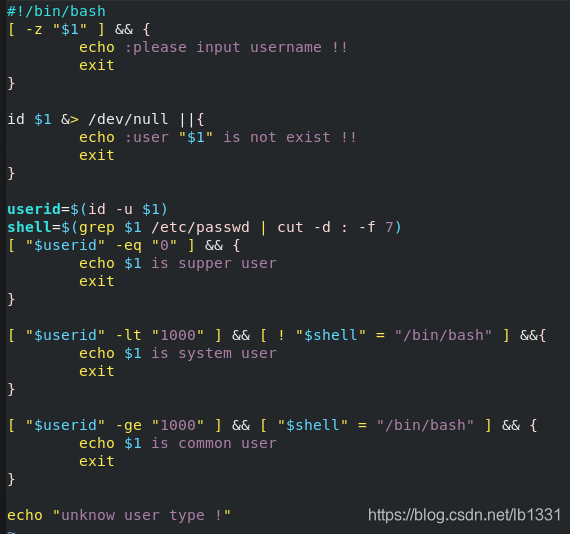
编写一个shell脚本,完成下列判断:
user_check.sh +用户
用户类型为:super user,system user,common user;
注意: /dev/null 可以理解为垃圾箱; 可以通过 $ &> /dev/null 来判断 $ 是否存在:
测试结果:
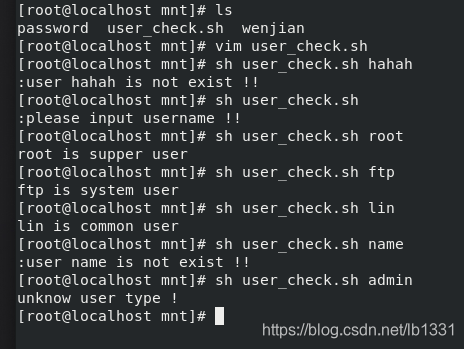
上述方法存在bug:例如:输入user为 lin 时,grep命令也会过滤出 linux 用户,导致判断出错;可将grep改为egrep解决该问题;
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
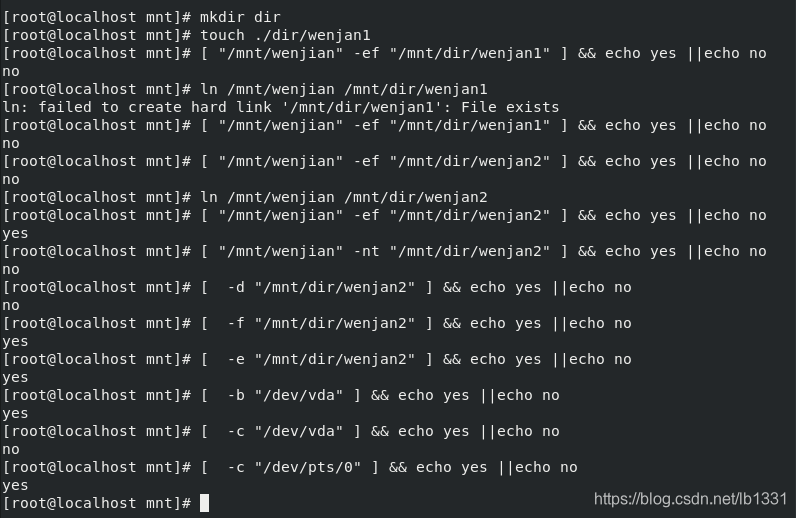
test对于文件的判定
-ef ##文件节点号是否一致(硬链接)
-nt ##文件1是不是比文件2新
-ot ##文件1是不是比文件2老
-d ##目录
-S ##套结字
-L ##软连接
-e ##存在
-f ##普通文件
-b ##快设备
-c ##字符设备
实验效果如图:
示例:编写脚本完成以下条件
file_check.sh 在执行时
如果脚本后未指定检测文件报错“未指定检测文件,请指定”
如果脚本后指定文件不存在报错“此文件不存在”
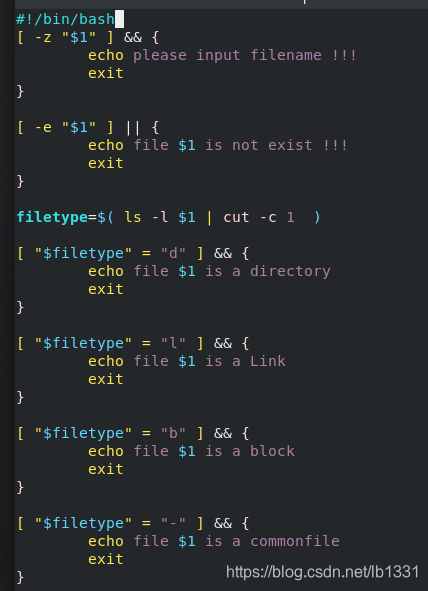
当文件存在时请检测文件类型并显示到输出中;
shell脚本如图: