shell之正则表达式
目录
一、shell之正则表达式
一、sort命令----以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
语法格式:
sort [选项] 参数
cat file | sort 选项


常用选项:
-f:忽略大小写
-b:忽略每行前面的空格
-n:按照数字进行排序
-r:反向排序
-u:等同于uniq,表示相同的数据仅显示一行
-t:指定字段分隔符,默认使用[Tab]键分隔
-k:指定排序字段
-o <输出文件>:将排序后的结果转存至指定文件
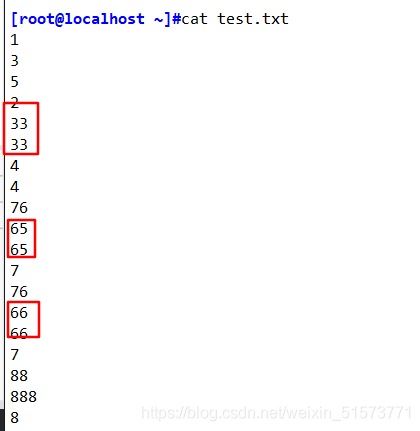
sort -n test.txt

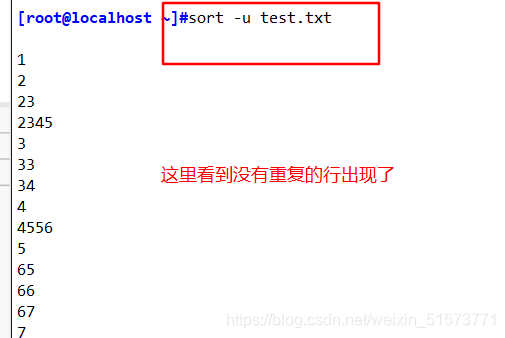
sort -u test.txt
sort -t ":" -k3 -n /etc/passwd

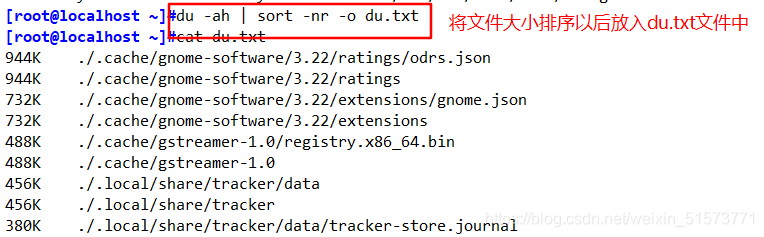
du -ah | sort -nr -o du.txt
二、uniq命令—用于报告或者忽略文件中连续的重复行,常与 sort 命令结合使用
语法格式:
uniq [选项] 参数
cat file | uniq 选项
常用选项:
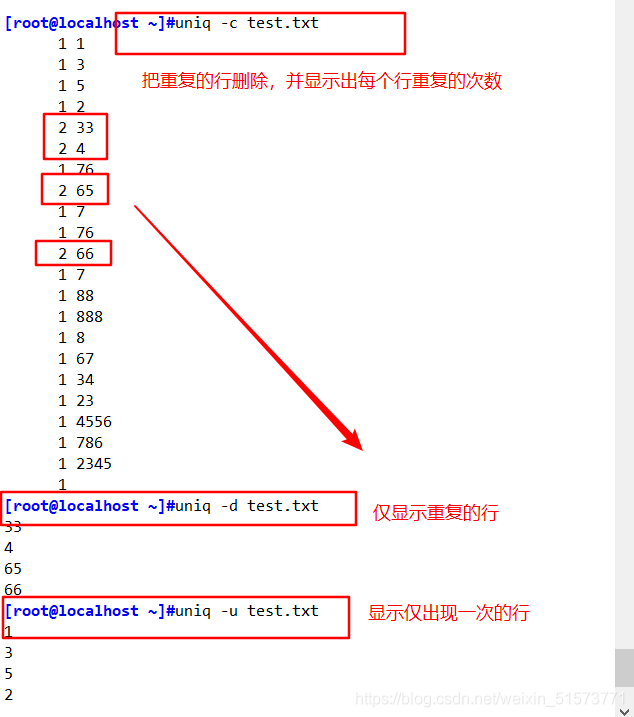
-c:进行计数,并删除文件中重复出现的行
-d:仅显示重复行
-u:仅显示出现一次的行
三、tr命令—常用来对来自标准输入的字符进行替换、压缩和删除
语法格式:
tr [选项] [参数]
常用选项:
-c:保留字符集1的字符,其他的字符用(包括换行符\n)字符集2替换
-d:删除所有属于字符集1的字符
-s:将重复出现的字符串压缩为一个字符串;用字符集2 替换 字符集1
-t:字符集2 替换 字符集1,不加选项同结果。
参数:
字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。但执行删除操作时,不需要参数“字符集2”;
字符集2:指定要转换成的目标字符集。
[root@localhost ~]#echo "abc" | tr 'a-z' 'A-Z'
ABC
#将abc替换成ABC
[root@localhost ~]#echo abccabacca | tr -c "ab\n" "0"
ab00aba00a
#保留ab字符,将其他字符替换成00
[root@localhost ~]#echo 'hello world' | tr -d 'od'
hell wrl
#删除od字符
[root@localhost ~]#echo "thissss is a text linnnnnnne." | tr -s 'sn'
this is a text line.
#将重复出现的s n字符压缩成一个字符
[root@localhost ~]#cat 123.txt
aa
bb
[root@localhost ~]#cat 123.txt | tr -s "\n"
aa
bb
#删除空行
[root@localhost ~]#echo $PATH | tr -s ":" "\n"
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/root/bin
#把路径变量中的冒号":",替换成换行符"\n"
#删除Windows文件“造成”的'^M'字符:
cat 22.txt | tr -s "\r" "\n" > new_22.txt
或cat 22.txt | tr -d "\r" > new_22.txt
Linux中遇到换行符("\n")会进行回车+换行的操作,回车符反而只会作为控制字符("^M")显示,不发生回车的操作。而windows中要回车符+换行符("\r\n")才会回车+换行,缺少一个控制符或者顺序不对都不能正确的另起一行。
[root@localhost ~]#rz -E
rz waiting to receive.
[root@localhost ~]#cat -A aa.txt
aa^M$
^M$
^M$
^M$
#在window创建一个文件,放入linux里面cat -A aa.txt 看到每个空格显示^M$.格式会发生变化

yum install -y dos2unix
dos2unix 33.txt #借用这个工具也可以改变格式,需要安装

数组排序
abc=(3 5 8 7 9 2 1)
echo ${abc[*]} | tr ' ' '\n' | sort -n

二、正则表达式
1、作用
正则表达式通常用于判断语句中,用来检测某一字符串是否满足某一格式
2、正则表达式组成
正则表达式是由普通字符与元字符组成
普通字符包括大小写字母、数字、标点符号及一些其他符号
元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
3、基础正则表达式常见元字符(支持的工具:grep、egrep、sed、awk)
| 基础正则表达式常见元字符 | 描述 |
|---|---|
| \ | 转义字符,用于取消特殊符号的含义。例:!、\n、$等 |
| ^ | 匹配字符串开始的位置。例:a、the、#、[a-z] |
| $ | 匹配字符串结束的位置。例:wordKaTeX parse error: Expected group after ‘^’ at position 2: 、^̲匹配空行 |
| . | 匹配除\n之外的任意的一个字符。例:go.d、g…d |
| * | 匹配前面子表达式0次或者多次,例:goo*d、go.*d |
| [list] | 匹配list列表中的一个字符,例:go[ola]d、[abc]、[a-z]、[a-z0-9]、[0-9]匹配任意一位数字 |
| [^list] | 匹配任意非list列表中的一个字符,例:[ ^0-9]、[ ^A-Z0-9]、[ ^a-z]匹配任意一位非小写字母 |
| {n} | 匹配前面的子表达式n次,例:go{2}d、’[0-9]{2,}'匹配两位数字 |
| {n} | 匹配前面的子表达式不少于n次,例:go{2,}d、’[0-9]{2,}'匹配两位及两位以上数字 |
| {n,m} | 匹配前面的子表达式n到m次,例:go{2,3}d、’[0-9]{2,3}'匹配两位到三位数字 |
注意:egrep、awk使用{n}、{n,}、{n,m}匹配时”{}“前不用加”\“
4、扩展正则表达式元字符(支持的工具:egrep、awk)
| 扩展正则表达式元字符 | 描述 |
|---|---|
| + | 匹配前面子表达式1次以上,例:go+d,将匹配至少一个o,如god、good、goood等 |
| ? | 匹配前面子表达式0次或者1次,例:go?d,将匹配gd或god |
| () | 将括号中的字符串作为一个整体,例:g(oo)+d,将匹配oo整体1次以上,如good、gooood等 |
| | | 以或的方式匹配字条串,例:g(oo|la)d,将匹配good或者glad |