文章目录
前言
在文件系统的存储中,我们一般不建议是一个目录下存放过多的文件或子目录。因为这会造成后续在此目录下文件或子目录的操作效率。我们宁愿用分散存储的方式,也比用集中在一个目录下的方式要来得效率高。这个大目录下查询文件效率低的现象在其它分布式文件系统中其实也存在,比如HDFS的大目录操作。假设我们HDFS目录下有个超大目录,其下子文件数量达到数十万级别,那么后续在这个文件下进行添加,或删除操作将会变得异常的缓慢。典型的例子比如HDFS删除大目录操作,导致NameNode hung住甚至可能crash的情况。笔者今天来聊聊此类分布式存储系统的大目录下文件操作性能的提升。
现有HDFS大目录文件操作效率
大家如果对HDFS没有很强的背景知识,这里笔者做个简单的介绍。在HDFS中,对于目录来说,它使用的类叫做INodeDirectory。在这个类中,它所有的子文件或子目录都用一个List结构的child列表保存,如下所示:
// 这里存储的INode可以是子文件INodeFile或者子目录INodeDirectory
private List<INode> children = null;
OK,我们看到这里存储子文件的方式其实很简单。后续外界对这个目录进行添加,获取或删除文件的操作即是对这个children list做一些add,get/remove操作而已。
当一个目录下的子文件数在比较正常的情况下时(几个或几十个子文件类似),添加删除操作基本不会有任何的效率问题。但是当子文件达到万甚至数十万级别之后,这个children list的结构将会有明显的性能问题。表现在HDFS层面的现象,就是一个delete Directory的call要花很长的时间,如果这个目录是超大型目录的情况。
HDFS的大目录删除性能问题本质上是Java List(此处使用的ArrayList)在超大element数量情况下的性能问题。
笔者在本地做了个对ArrayList的add/delete性能测试,以下为部分测试结果:
| List Size | Add Time(ms) | Delete Time(ms) |
|---|---|---|
| 5000 | 16 | 1 |
| 50000 | 117 | 112 |
| 500000 | 7072 | 12230 |
以上是笔者测试其中一组数据。我们可以看到list的add,delete操作时间并不是随着list size线性增长的,这个size越大,实际所花时间的增长远超之前的数值。这样归结于ArrayList在add,delete操作中要做array数组的copy以及element位置的挪动有关。当其内部element越大的时候,这个copy,挪动的成本将会越来越高。举个例子,我们在一个size为50w的ArrayList头部插入一个新element,那么这意味着ArrayList会将现有的50w个element都往后移一个位置,腾出第一个位置给新插入的element。可想而知,这个代价是相当高的。
OK,基于上述现象以及其底层的本质原因,我们要想改善HDFS大目录操作性能问题或是类似此原理做目录管理的性能问题,我们有一个最直接有效的办法:改造现有用List存储目录子文件的结构。
基于哈希分区的多List目录存储结构
既然上面的问题是ArrayList在大数量集存储下会有性能问题,那么我们为何不可以将其拆散分散成多个小List进行存储呢?小List的操作效率跟之前持平,只是我们需要多一步文件到具体List的一个映射问题。HDFS社区JIRA HDFS-7174:Support for more efficient large directories 就是基于这个思路实现的。
在这里笔者将新的基于哈希分区的ArrayList叫做HashedArrayList,原始结构ArrayList和HashedArrayList的结构组织如下图所示:
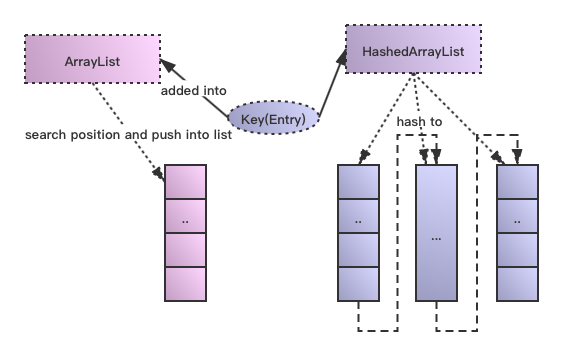
HashedArrayList对于外界使用者来说,它的逻辑层意义还是维持了单List的概念,它区别于原始ArrayList的操作在于:
需要对插入的element项,按照key算出它所在的分区号,在这里叫做table index,意为哪一个list列。
具体找到这个列后,后续根据key查找进行列表的位置插入操作和原来方式一致。
HashedArrayList的element的索引查找
HashedArrayList内部实际使用多ArrayList做存储,但是对外又要保持全局单一List的方式使用,在这里必然会存在索引查找的gap。
简单来说,在原有的ArrayList下,我们的查找操作如下步骤所示:
- 1)通过一个key(文件名),直接拿目录下的children list做二分比较查找,然后得到一个index下标值。
- 2)从children list获取第index值表示的element项即可。
显然ArrayList的直接index在HashedArrayList中是行不通的,因为后者还存在table index。所以在这里我们需要构造一个新型的专属于哈希分区List使用的Index索引结构,它预期应该是TableIndex + ListIndex的样子。
社区JIRA HDFS-7174在实现中对此做了巧妙的设计,为了保持ArrayList index的Int类型的兼容性,它将一个32位的int值做了拆分,高位存储Table Index,低位存储List Index,如下图设计所示:
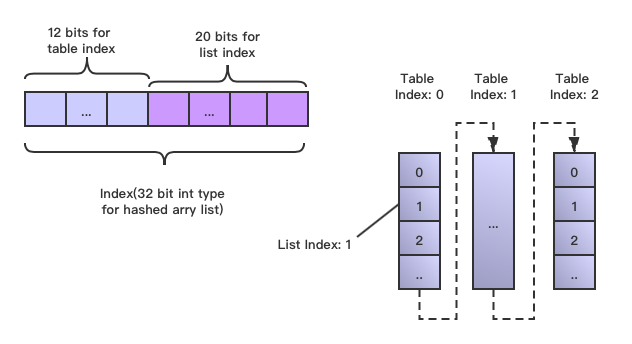
在笔者的测试HashedArrayList例子中,采用高12,低20位的Index存储方式。在高位存储中,需要去除掉1位做符号位的bit,其余Table/List Index的range分别为:
- 11个bit位用于做Table Index的标识:0~2047(2的11次方-1)
- 20个bit位用于做List Index的标识 :0~1048575(2的20次方-1)
以上index range的乘积即哈希List理论所能承受的最大element数,已经可以达到惊人的20亿数量级别了。这个在实际运用场景中已经足够达到标准了。
这里关键的index计算与反解析操作方法如下所示:
// The lower 20 bits of the int is the index in the ArrayList.
// The upper 12 bits is the index in the listTable.
private static int getLocator(int tableIndex, int listIndex) {
assert listIndex < MAX_LIST_INDEX && listIndex > -MAX_LIST_INDEX;
assert tableIndex < L1_SIZE && tableIndex >= 0;
// 先进行tableIndex的左移20位操作,给后面的ListIndex进行位值的存储
if (listIndex < 0) {
// this is an insertion point.
return -(tableIndex << 20 | (0xfffff & -listIndex));
} else {
return tableIndex << 20 | (0xfffff & listIndex);
}
}
// Index in the listTable
// 将hashed list index右移20位,获取余下的Table Index值
static int getTableIndex(int loc) {
int index = loc < 0 ? -loc >> 20 : loc >> 20;
assert index < L1_SIZE;
return index;
}
// Index in a specific ArrayList
// 后20位的bit数做&运算,获取List Index值
static int getListIndex(int loc) {
return loc < 0 ? -(0xfffff & -loc): (0xfffff & loc);
}
HashedArrayList的代码实现
相信大家在看完上述结构后,比较关心HashedArrayList的代码实现以及其相应的性能提升了。笔者基于HDFS-7174里的原始模型,做了稍许的改动,代码如下,
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.hdfs.server.namenode;
import java.util.Collections;
import java.util.Iterator;
import java.util.ArrayList;
import java.util.Arrays;
import com.google.common.annotations.VisibleForTesting;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.hdfs.server.namenode.INode;
import org.apache.hadoop.hdfs.util.ReadOnlyList;
/**
* A more efficient children list implementation for large directories.
* The normal ArrayList-based children list is simple and provides reasonable
* performance for small directories. However, the insertion cost of O(n)
* becomes too expensive when the directory gets big.
*
* This class implements a children list with the bounded lookup and insertion
* time. However it requires slightly more memory and the list not being
* completely sorted.
*/
@InterfaceAudience.Private
public class INodeHashedArrayList extends AbstractINodeList {
// With the index table size of 1024, the average size of individual
// ArrayList will be under 64KB.
private static int L1_SIZE = 1024;
// The lower 20 bits of the int used to store list index, so the
// maximum should be 1 << 20.
private static int MAX_LIST_INDEX = 1 << 20;
// The PB size limit of 64KB dictates the maximum number of immediate
// children that can be saved per directory.
private static int MAX_DIRENT = 8*1024*1024 - 1;
// Default initial size of the whole list.
private static int DEFAULT_INITIAL_SIZE = 32*1024;
// The list index table for locating ArrayList.
@SuppressWarnings("unchecked")
private ArrayList<INode>[] listTable = (ArrayList<INode>[])(new ArrayList[L1_SIZE]);
// initial size of each list
private int initialSize;
public INodeHashedArrayList() {
this(DEFAULT_INITIAL_SIZE);
}
/** Create with the given initial size */
public INodeHashedArrayList(int size) {
super();
int listSize = size/L1_SIZE;
this.initialSize = (listSize < 5) ? 5 : listSize;
}
// Pick an array list based on the hash of the name.
private static int calcIndex(byte[] name) {
int hash = Arrays.hashCode(name) % L1_SIZE;
return (hash > 0) ? hash : -hash;
}
// The lower 16 bits of the int is the index in the ArrayList.
// The upper 16 bits is the index in the listTable.
private static int getLocator(int tableIndex, int listIndex) {
assert listIndex < MAX_LIST_INDEX && listIndex > -MAX_LIST_INDEX;
assert tableIndex < L1_SIZE && tableIndex >= 0;
if (listIndex < 0) {
// this is an insertion point.
return -(tableIndex << 20 | (0xfffff & -listIndex));
} else {
return tableIndex << 20 | (0xfffff & listIndex);
}
}
private ArrayList<INode> getList(int loc) {
int index = getTableIndex(loc);
if (listTable[index] == null) {
listTable[index] = new ArrayList<INode>(initialSize);
}
return listTable[index];
}
// Index in the listTable
static int getTableIndex(int loc) {
int index = loc < 0 ? -loc >> 20 : loc >> 20;
assert index < L1_SIZE;
return index;
}
// Index in a specific ArrayList
static int getListIndex(int loc) {
return loc < 0 ? -(0xfffff & -loc): (0xfffff & loc);
}
@Override
public int size() {
int count = 0;
for (int i = 0; i < L1_SIZE; i++) {
ArrayList<INode> list = listTable[i];
if (list != null) {
count += list.size();
}
}
return count;
}
/**
* locator for the existing entry or the insertion point.
*/
@Override
public int searchChildren(byte[] name) {
int tableIndex = calcIndex(name);
if (listTable[tableIndex] == null) {
listTable[tableIndex] = new ArrayList<INode>(initialSize);
}
int listIndex = Collections.binarySearch(listTable[tableIndex], name);
return getLocator(tableIndex, listIndex);
}
@Override
public void add(int index, INode node) {
if (node == null) {
throw new IllegalArgumentException("INode is null");
}
ArrayList<INode> list = getList(index);
int listIndex = getListIndex(index);
list.add(listIndex, node);
}
@Override
public INode get(int index) {
return getList(index).get(getListIndex(index));
}
@Override
public INode set(int index, INode node) {
if (node == null) {
throw new IllegalArgumentException("INode is null");
}
return getList(index).set(getListIndex(index), node);
}
@Override
public INode remove(int index) {
return getList(index).remove(getListIndex(index));
}
@Override
public void clear() {
for (int i = 0; i < L1_SIZE; i++) {
ArrayList<INode> list = listTable[i];
if (list != null) {
list.clear();
}
}
}
@Override
public Iterator<INode> iterator() {
return iterator(0);
}
// Find the first valid locator starting from loc. If not found,
// -1 is returned.
private int getFirstLocator(int loc) {
int tableIndex = getTableIndex(loc);
int listIndex = getListIndex(loc);
ArrayList<INode> list = listTable[tableIndex];
// An entry exists at the slot pointed by the locator.
if (list != null && list.size() > listIndex) {
return loc;
}
// search the next list
tableIndex++;
for (; tableIndex < L1_SIZE; tableIndex++) {
list = listTable[tableIndex];
if (list != null && list.size() > 0) {
return getLocator(tableIndex, 0); // The first item in the list.
}
}
// not found.
return -1;
}
// Return an iterator that starts at the first valid entry found from
// the locator.
Iterator<INode> iterator(int loc) {
final int startingLoc = getFirstLocator(loc);
// No more entries. Return an empty iterator.
if (startingLoc < 0) {
return new Iterator<INode>() {
@Override
public boolean hasNext() {
return false;
}
@Override
public INode next() {
throw new java.util.NoSuchElementException("No more entry");
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
};
}
return new Iterator<INode>() {
int currentTableIndex = getTableIndex(startingLoc);
int currentListIndex = getListIndex(startingLoc);
@Override
public boolean hasNext() {
// It starts with a non-null list and the current list will always be
// non-null. So there is no need to check the list against null.
ArrayList<INode> list = listTable[currentTableIndex];
if (list.size() > currentListIndex) {
return true;
}
// No more entries in the current list.
if (currentTableIndex + 1 == L1_SIZE) {
// it was the last list
return false;
}
// Find the next entry.
int newLoc = getFirstLocator(getLocator(currentTableIndex+1, 0));
if (newLoc < 0) {
// no more entries
return false;
}
currentTableIndex = getTableIndex(newLoc);
currentListIndex = getListIndex(newLoc);
return true;
}
@Override
public INode next() {
if (hasNext()) {
INode node = ((ArrayList<INode>)listTable[currentTableIndex]).get(currentListIndex);
currentListIndex++;
assert node != null;
return node;
}
throw new java.util.NoSuchElementException("No more entry");
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
};
}
@Override
public ReadOnlyList<INode> toReadOnlyList() {
final INodeHashedArrayList iList = this;
return new ReadOnlyList<INode>() {
@Override
public Iterator<INode> iterator() {
return iList.iterator();
}
@Override
public boolean isEmpty() {
return iList.isEmpty();
}
@Override
public int size() {
return iList.size();
}
@Override
public INode get(int i) {
return iList.get(i);
}
@Override
public <K> int getMinIndex(K key) {
byte[] bytes = new byte[0];
if (key.getClass() == bytes.getClass()) {
return getLocator(calcIndex((byte[])key), 0);
}
throw new IllegalArgumentException("Need byte[] as a key");
}
@Override
public <K> int getMaxIndex(K key) {
byte[] bytes = new byte[0];
if (key.getClass() == bytes.getClass()) {
int index = calcIndex((byte[])key);
ArrayList list = listTable[index];
if (list == null || list.isEmpty()) {
return getLocator(index, -1);
}
return getLocator(index, list.size() -1);
}
throw new IllegalArgumentException("Need byte[] as a key");
}
@Override
public int countRemaining(int loc) {
if (loc < 0) {
return 0;
}
int count = 0;
int tableIndex = getTableIndex(loc);
int listIndex = getListIndex(loc);
ArrayList<INode> list = listTable[tableIndex];
// Initially get the number for the current list.
if (list != null && list.size() > listIndex) {
count += list.size() - listIndex;
}
// Visit the rest of the lists.
tableIndex++;
while(tableIndex < L1_SIZE) {
list = listTable[tableIndex];
if (list != null) {
count += list.size();
}
tableIndex++;
}
return count;
}
@Override
public Iterator<INode> iterator(final int startingLocator) {
return iList.iterator(startingLocator);
}
};
}
@VisibleForTesting
public void setTableSize(int tableSize) {
this.L1_SIZE = tableSize;
}
}
还有另外相关的一个原始ArrayList的包装类,以及一个自动切换的ArrayList类AutoSwitchingINodeList(根据目录下的children数,自动进行相应更优的ArrayList类型进行转化)类在HDFS-7174的社区JIRA patch内可以找到,这里笔者就不展开篇幅介绍了。
HashedArrayList性能测试
随后笔者对这个新的基于哈希分区的List结构做了性能测试,同样在5000,5w,50w的量级下做了测试,测试结果非常喜人:
时间值按照排序:ArrayList/HashedArrayList
| List Size | Add Time(ms) | Delete Time(ms) | Get Time(ms) |
|---|---|---|---|
| 5000 | 16/4 | 3/5 | 1/1 |
| 50000 | 117/38 | 112/25 | 5/9 |
| 500000 | 7072/541 | 12230/354 | 16/49 |
在上述的性能测试数据中,我们可以验证出以下结论:
在大规模数量级情况下,哈希分区List在add/delete有显著于原ArrayList的改善效果,不过在get操作上慢了一点点,这主要的开销源于HashedArrayList在element查找的时候,需要多做一层Table List的子list查找过长。不过这部分时间开销总时间的绝对并不高,因此实际影响还好。因此整体来看,HashedArrayList的已经表现出了高效的执行效率,远超出原ArrayList。
笔者目前还处于对此结构的测试阶段,不过相信HashedArrayList基于哈希分区的多List管理结构思路能很好地解决文件系统中大目录操作的性能效率问题,假设我们能完美地将其适配到我们的系统中去。
引用
[1].https://issues.apache.org/jira/browse/HDFS-7174 . Support for more efficient large directories