免责声明:自本文章发布起, 本文章仅供参考,不得转载,不得复制等操作。浏览本文章的当事人如涉及到任何违反国家法律法规造成的一切后果由浏览本文章的当事人自行承担与本文章博客主无关。以及由于浏览本文章的当事人转载,复制等操作涉及到任何违反国家法律法规引起的纠纷和造成的一切后果由浏览本文章的当事人自行承担与本文章博客主无关。
1. 加载模块
PyCharm
https://blog.csdn.net/YKenan/article/details/96290603
控制台
pip3 install requests
2. 请求数据
引用模块
import requests
语法
GET 参数:
- url: get 请求的 URL.
- params: get 请求传入的数据.
- headers: 请求头. 多进行设置 User-Agent.
- timeout: 限制连接超时时间, 单位为 s.
POST 参数:
- url: post 请求的 URL.
- data: post 请求传入的数据.
- headers: 请求头. 多进行设置 User-Agent.
- timeout: 限制连接超时时间, 单位为 s.
# get 请求
requests.get(url, params, headers, timeout)
# post 请求
requests.post(url, data, headers, timeout)
比如模拟百度翻译
# url, UA, 参数
url = "https://fanyi.baidu.com/sug"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"
}
word = input("请输入单词:")
# post 请求传入的数据
data = {
"kw": word
}
# 爬取
response = requests.post(url=url, data=data, headers=headers, timeout=5)
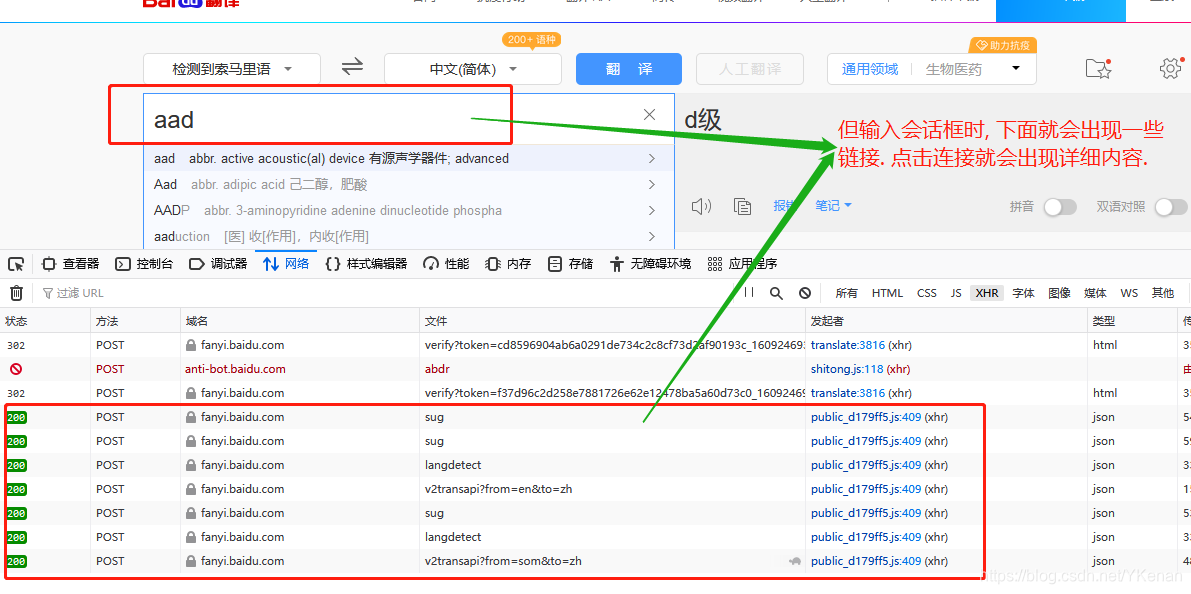
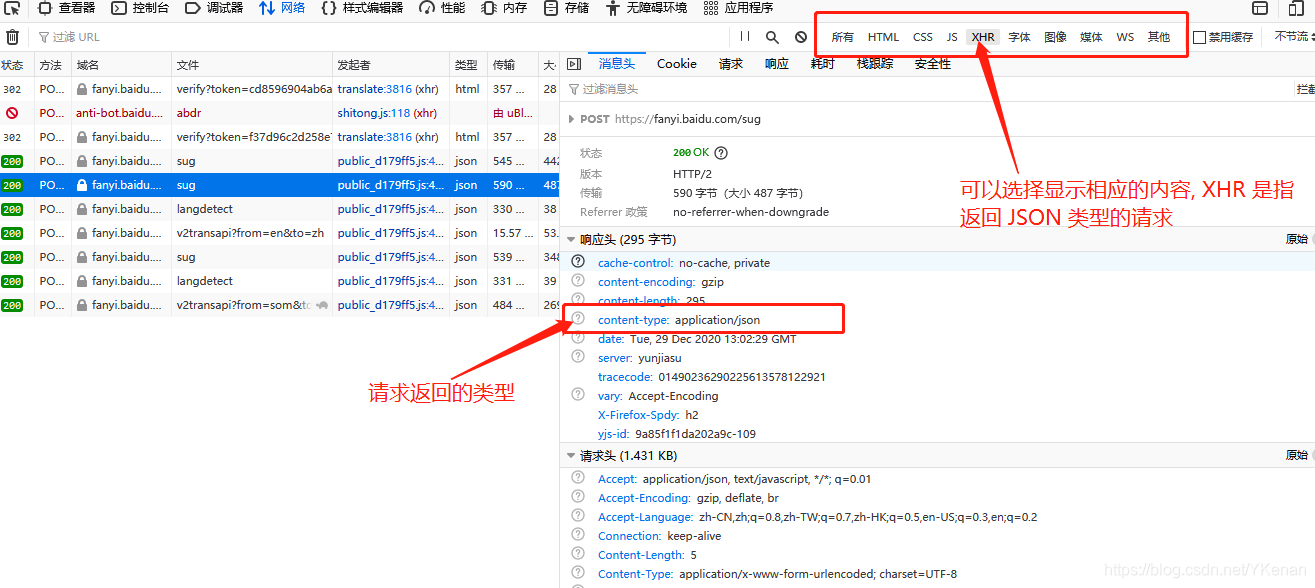
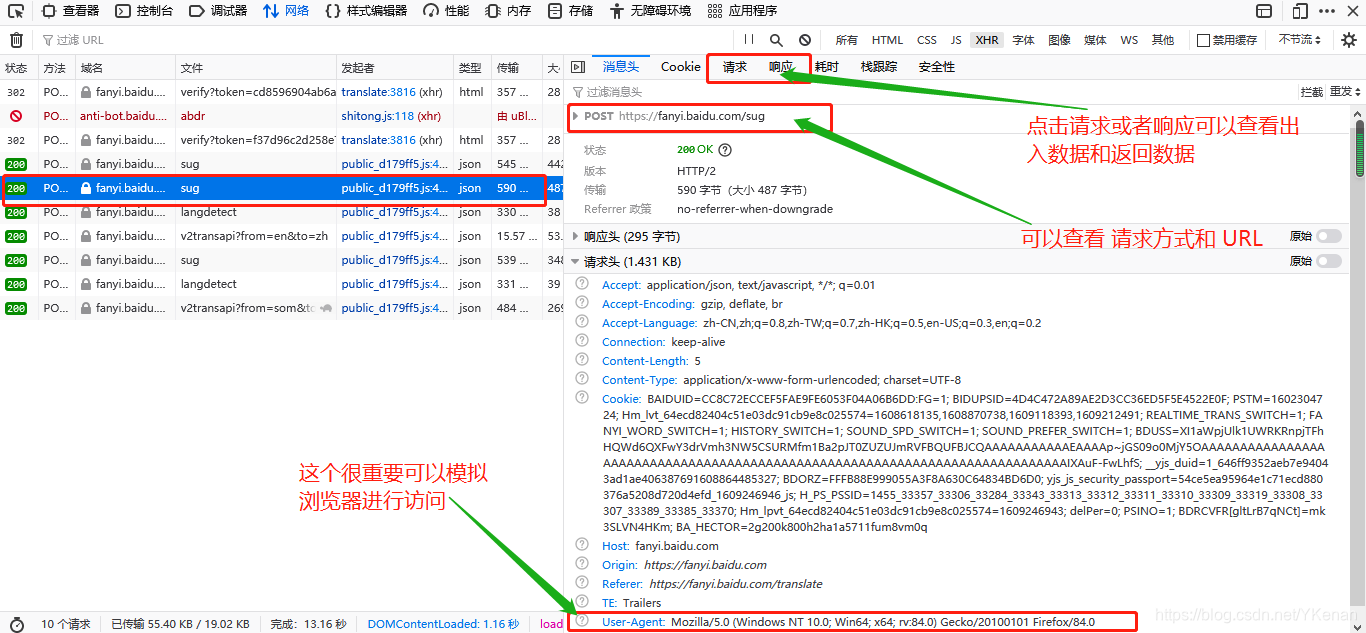
其中如何寻找连接:
进入百度页面右键检查元素或者点击F12
点击网络重新刷新页面.
3. 获取数据结果
# 返回二进制响应内容
response.content
# 返回页面内容
response.text
# 返回 JSON 数据
response.json()
爬取过程中数据大些用
try防止网络问题而导致停止爬取.
requests 爬取基本上都和re模块一起使用, 通过正则抽取出所需的数据内容.
4. 实例
百度翻译
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# 导包
import requests
import json
if __name__ == '__main__':
# url, UA, 参数
url = "https://fanyi.baidu.com/sug"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"
}
word = input("请输入单词:")
# post 请求传入的数据
data = {
"kw": word
}
# 爬取
response = requests.post(url=url, data=data, headers=headers)
# 返回 json 数据
print(response.json()["data"][0]["v"])
# 存储
fp = open(f"./data/fanyi/{word}.json", "w", encoding="utf-8")
# ensure_ascii=False 显示中文
json.dump(response.json(), fp=fp, ensure_ascii=False)
fp.close()
下载照片
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import requests
import re
if __name__ == '__main__':
# 遍历页数
for page in range(21, 40):
# url 及参数
url = "http://aspx.sc.chinaz.com/query.aspx"
params = {
"keyword": "可爱",
"classID": "11",
"page": page
}
# UA
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"
}
# 爬取
response = requests.get(url=url, params=params, headers=headers)
# 网页内容
text = response.text
# 正则 () 内匹配想要的内容
image_urls = re.findall('<img data-src="(.*?)" alt=".*?" class="preview" />', text, re.S)
print(image_urls)
# 便利照片
for image_url in image_urls:
# 得到照片的二进制数据
image_url__content = requests.get("http:" + image_url, headers=headers).content
with open(f"./data/image/{'%d-%d' % (page, image_urls.index(image_url))}.jpg", "wb") as f:
f.write(image_url__content)
print(image_url + " 下载完成")
国家药品监督管理局爬取数据
http://scxk.nmpa.gov.cn:81/xk/
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# 导包
import requests
import pandas as pd
# 返回值可以作为输入值
def getID(list_page):
# 记录爬虫没有爬取成功的页数
list_error = []
# 遍历页数
for page in list_page:
# url, UA, 参数
url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"
}
# post 请求传入的数据
data = {
"method": "getXkzsList",
"page": page,
}
try:
# 爬取, 并设置超时时间为 3s
response = requests.post(url=url, data=data, headers=headers, timeout=3)
# 返回 json 数据, 得到 List
json_list_ = response.json()["list"]
# 得到 ID
for json_list_data in json_list_:
print(json_list_data["ID"])
# 写入文件
with open("./data/nmpa/list_ID.txt", "a", encoding="utf-8") as f:
f.write(json_list_data["ID"] + "\n")
except:
list_error.append(page)
return list_error
# 返回值可以作为输入值
def get_detail(list_id):
# 记录爬虫没有爬取成功的 ID
list_error = []
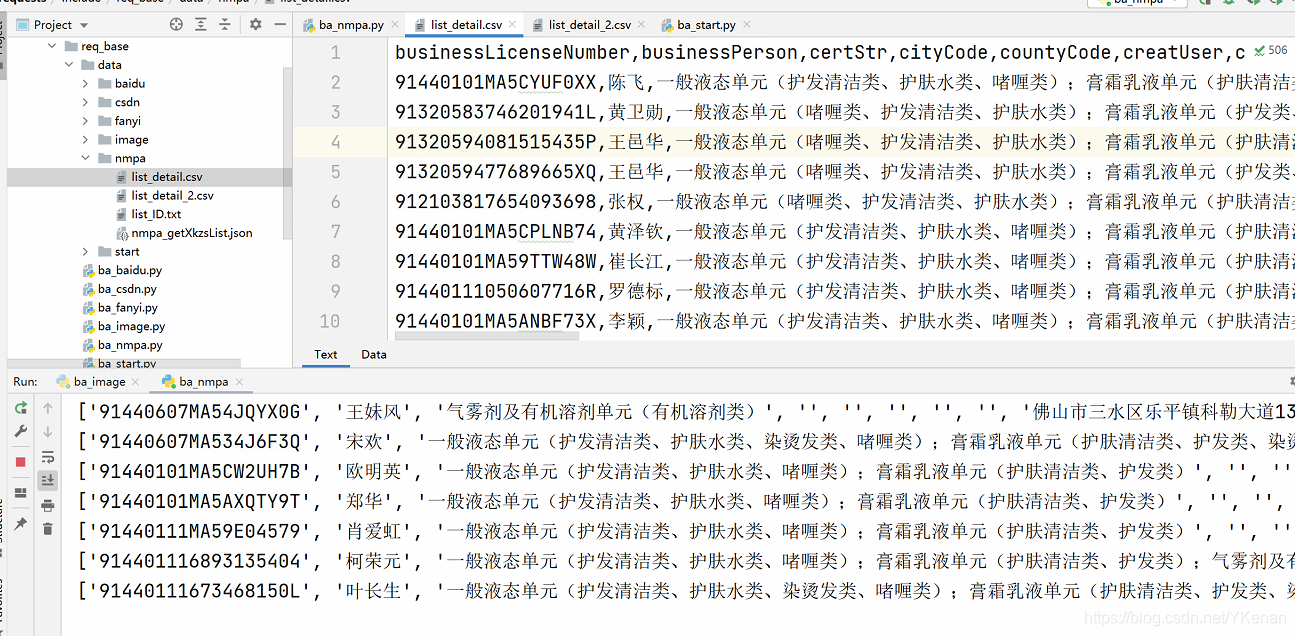
columns = ['businessLicenseNumber', 'businessPerson', 'certStr', 'cityCode', 'countyCode', 'creatUser', 'createTime', 'endTime', 'epsAddress', 'epsName', 'epsProductAddress', 'id', 'isimport', 'legalPerson', 'offDate', 'offReason', 'parentid', 'preid', 'processid', 'productSn', 'provinceCode', 'qfDate', 'qfManagerName', 'qualityPerson', 'rcManagerDepartName', 'rcManagerUser', 'startTime', 'xkCompleteDate', 'xkDate', 'xkDateStr', 'xkName', 'xkProject', 'xkRemark', 'xkType']
df = pd.DataFrame(columns=columns)
for ID in list_id:
# url, UA, 参数
url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0"
}
# post 请求传入的数据
data = {
"method": "getXkzsById",
"id": ID,
}
try:
# 爬取, 并设置超时时间为 3s
response = requests.post(url=url, data=data, headers=headers, timeout=1)
# 返回 json 数据, 得到 List
list_detail = list(dict(response.json()).values())
print(list_detail)
df.loc[len(df)] = pd.Series(list_detail, index=columns)
except:
list_error.append(ID)
df.to_csv("./data/nmpa/list_detail_2.csv", encoding='utf_8_sig', index=False)
return list_error
if __name__ == '__main__':
# 获取 ID
print(getID(range(1, 360)))
# 读取文件
f = open("./data/nmpa/list_ID.txt", "r", encoding="utf-8")
lines = f.read().splitlines()
f.close()
# 爬取信息
print(get_detail(lines))