前言
众所周知,在当下存储系统中为了存储效率的提升,Erasure Coding(纠删码)技术在扮演着一个越来越重要的角色。比如说目前Hadoop HDFS中,它就已经能够支持EC功能了。在EC模式下,HDFS 可以不必存储多打3份这样的冗余副本数来为了容灾保护。存储效率的提高意味着存储海量数据所需要的存储节点资源的减少。不过本文并不是聊HDFS的EC实现的,而是谈谈时下另外一个存储系统Ozone的EC设计,也是简单聊聊在Ozone的对象存储模式下,EC要如何实现以及它能够带来的好处。
EC技术以及EC下的存储效率的提升
关于EC技术本身,全称Erasure Coding,中文称之为纠删码技术。EC的具体算法实现细节网上资料讲述的也已经很多了,本文不做过分细致的阐述。
简单的来说,就是将原始数据块进行划分成多个data block,然后根据EC算法的计算,产生出新的校验块(parity block),如下所示:
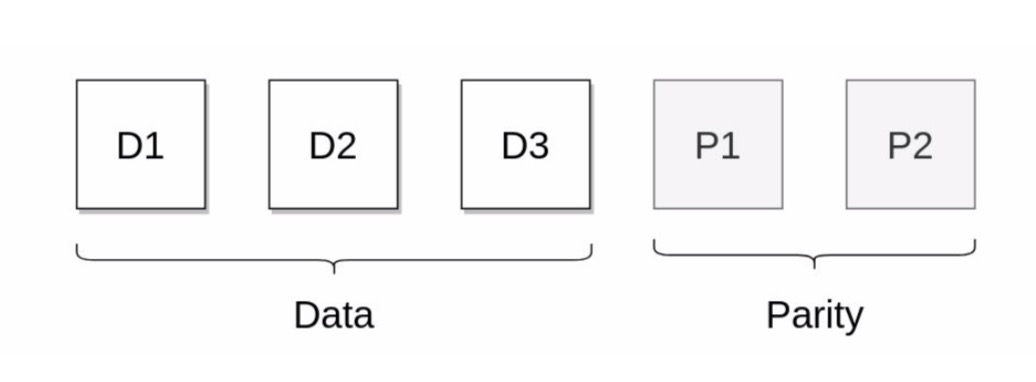
当上述数据块或者校验块发生丢失或者损坏的情况时,系统可以根据EC算法进行重新生成来恢复,以此达到数据保护的效果。
还有一个问题,这里的数据存储效率的提升体现在哪里呢?
继续以上述例子为例,在上面3个数据块,2个校验块模式下,那么此时数据存储效率为3/(3+2)=60%,而在传统3副本模式下,存储效率只为1/3=33%,它的另外2份存储是完全冗余的,注意我们这里谈的是绝对有效的存储。
OK,我们可以看到在EC模式下,系统的存储效率能够得到不小的提升,当采用不同EC算法模式时,这个存储效率还可能更高。
凡是硬币都有正方面,另外一方面,EC的劣势在于做它做数据恢复时,需要耗费更多的网络和CPU资源,所以我们一般将那些访问低频次的冷数据进行EC的处理。
Ozone下的EC方案设计
在上小节部分我们对EC有个简单的了解后,我们再来看看针对Ozone系统的特点,Ozone社区是如何做这块的设计的。Ozone社区在JIRA HDDS-3816:Erasure Coding in Apache Hadoop Ozone中对此方案进行了设计。
在此方案中它主要提出了2套可选的方案:
- 以Container为基本存储单元,针对Container Level的EC实现。
- 以Block(Container内的Block)为基本存储单元,针对Block Level的EC实现。
这2种EC的实现方案在实现复杂度以及各自方案的优劣势都有所不同。下面我们来分别来了解这里面的实现细节部分的内容。
Container Level的EC实现
首先Container Level的EC实现,以Container为基本单位,Ozone将会把一个整的Container作为一个大的data block,而Container里面实际存储的Block在是这个data block的一个小的部分。然后不同的Container就组成了多data block,最后就是校验Container块的产生了。
此过程图如下所示:
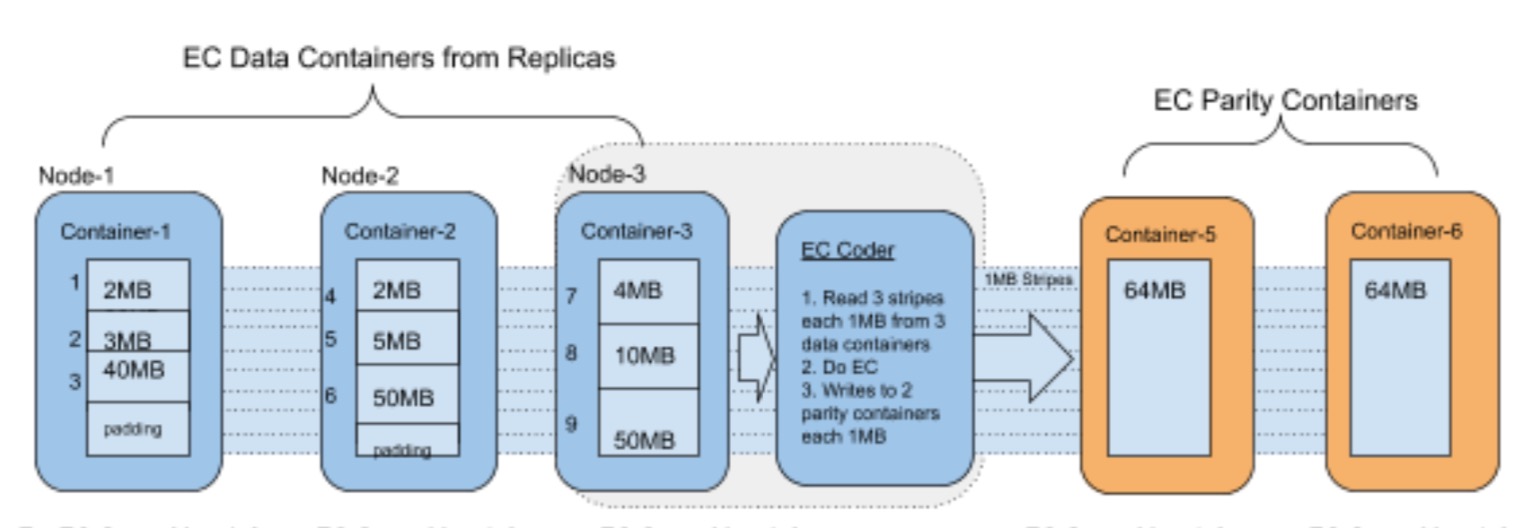
上面Container里面1,2,3,4,5数字代表的里面的Block块。每个相同偏移量位置的Block数据进行对应检验块数据的生成,如下图所示:
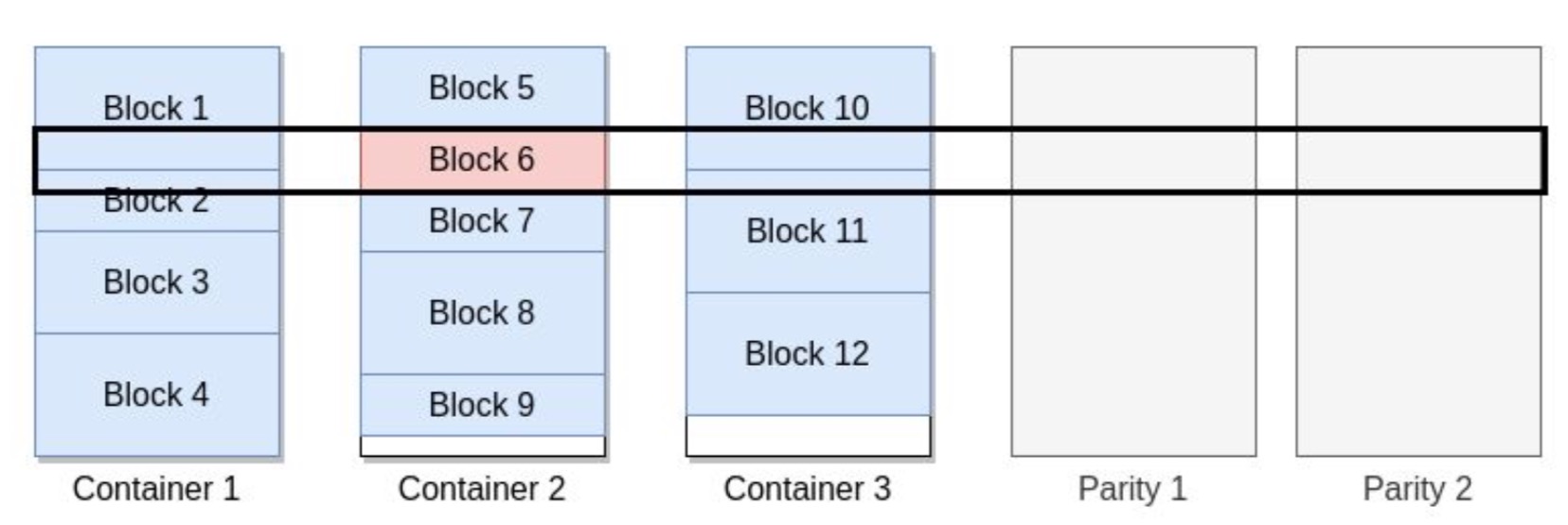
我们从另外一个层面来看,多余的Container副本就可以校验Container剔除取代了,
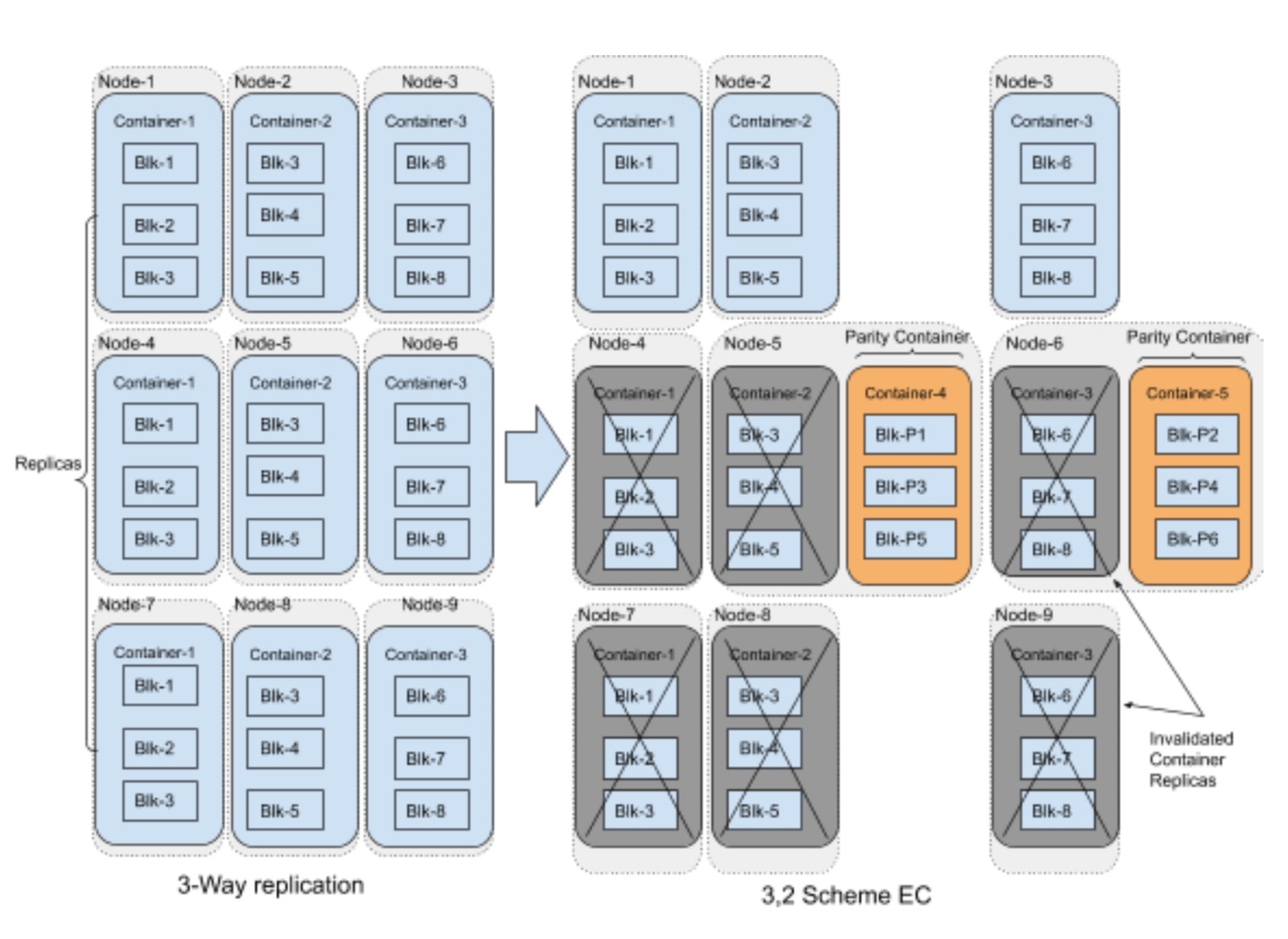
在Container Level的EC实现中,对现有Ozone内部的改动其实是稍微比较小的。因为Container内部的Block数据结构,位置其实都没有发生改变。OM那边也不需要更新Key对应的Block位置信息。换句话锁,Container Level的EC对于原有的对象数据的读写访问没有什么影响。
但是这里的影响主要在于Container的异步校验Container的生成,当前设计是只考虑给closed状态的Container做EC处理,因此我们不会有数据新写入Container,而校验Container还是老的这样的问题。
另外一点的影响方面是closed状态的Container数据的删除,在Container EC模式中,每个Container的作用是被放大了,每个Container不仅自身存储有Block数据外,它还同时担负着帮助其它Container进行数据错误恢复的作用,即使这个Container它可能已经被删除了。简单来说,在Ozone中被删除的closed状态的Container或Container中的任何Block数据被删除了,都不能被马上立即地被物理删除掉,除非等到它所依赖的Container已经重新组织别的新的Container进行校验Container的生成。
最后是我们以Container级别的粒度做数据的恢复,它的cost开销可能会比较大。目前Ozone默认一个Container最大的size是5GB。在HDFS中,它的block设置往往就128MB,256MB这种级别,在Ozone中我们提升到了GB级别,它所需要的开销必然会有所增加的。
Block Level的EC实现
聊完Container Level的EC方案后,我们再来说说Block的EC方案。这里的Block指的是Container内的那些Block。如果我们按照Container Block做EC的实现,其本质已经十分类似于HDFS的EC实现了。它同样是将一个Block进行条带式的分散写入到多个Container,多个node里去。
这里类似HDFS Block EC结构,下图为HDFS Block的EC条带式存储:

这样的方式会打破现有Block数据的写入实现逻辑,而且OM服务那边Key对应的Block位置信息也是需要更新的。Block Level的EC实现所需要的代码变动相较Container Level来说是更多一点的。
不过在Block Level下,笔者认为它的读写性能理应会得到提升的,因为数据横向存储在多节点中,我们可以采用并行读写,然后合并结果的方式来提升数据读写的效率。
另外在Block Level下,我们可以针对更细粒度Key级别做EC的设置了。当然了,它也会损失数据的locality特征,因为此时数据是分散存储在多节点之下的。
但论整体完整度和潜在影响来说,笔者个人观点是认为Block Level的EC方案要比Container Level更好一些。包括它也没有上面提到的Container删除的问题。
以上就是本文今天所要阐述的关于Ozone EC的内容了,还是很期待这个功能在Ozone中得到完整的实现的。
引用
[1].https://issues.apache.org/jira/browse/HDDS-3816 . Erasure Coding in Apache Hadoop Ozone