前言
在大规模的分布式集群节点中,出现机器损坏的现象是十分常见的。但为了保证数据的高可用性,系统在设计上往往采用多副本的形式来达到冗余的效果。对于那些“损坏”了的机器,正常的逻辑是走正常下线过程,即decommission流程。Decommission最为核心的一点是,它要保证节点内的数据完好无恙的复制到其它健康的节点上,然后最后将此节点标记为Decommissioned状态,随后就可以从集群中移除了。Decommission过程能够减小因为坏节点下线对于集群产生的不利影响。在我们所熟知的HDFS里面,就有相当完整的Decommission过程以及命令使用方式。本文笔者不聊HDFS的Decommission,而是聊聊新一代对象存储系统Ozone的Decommission原理过程。尽管Ozone在底层数据存储原理上与HDFS差异较大,但是在Decommission部分逻辑上还是有许多共通之处的,笔者会在下文中具体阐述其中的一些区别点。
Ozone Decommission原理过程
Ozone Decommission过程用更为具体清晰的解释:Ozone基于Container的Decommission过程。Ozone在数据replication是在Datanode的Container level来做的,那么Decommission过程也就自然同样是根据Container来做的。
在Ozone Decommission的整个过程里,它需要保证以下3点核心要求:
- Datanode Decommission过程中, 其节点上的数据不能被允许再写,读还是可以的。
- Datanode Decommission过程意外中断,下次可再次进行Decommission恢复继续。
- Datanode Decommission后,其节点内的数据完好无损的replication到其它健康节点上。
下面我们来结合Ozone Decommission原理过程图,来看看在实际实现中,上面3点要求是如何被实现的:
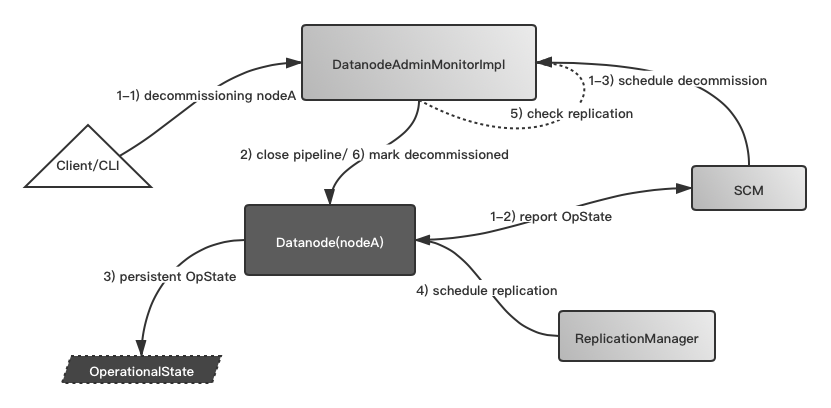
上图根据颜色划分,总共分为3个模块:
- 白色部分,client端,负责指定要decommission哪个节点。
- 灰色部分,SCM端, 负责处理节点decommission的全部过程。
- 黑色部分,Datanode端,以当前节点为source,实际数据发生replication的地方。
对照上图的流程步骤为:
1-1) Client端输入待下线节点,这个命令新发送到SCM端
2)SCM内部DatanodeAdminMonior接受到了decommission节点信息,然后首先开始执行节点的close pipeline操作,此操作目的为不允许此节点上的Container数据允许被写。此步骤对应的就是上面的1)要求。
3) 随后Datanode这边会持久化当前的Operational State,意为是否是处于Decommission状态,此举用于Decommission的意外恢复中断。此步骤对应的就是上面的2)要求。
4)随后ReplicationManager会在周期性检测Container replica数时,会检测到数量不足的replica Container,然后触发Replication操作行为。
5)DatanodeAdminMonior定期检查decommission节点上的Container副本情况,判断其是否已达到预期副本数数量。
6)如果已达到,则标记节点为decommissioned成功的节点。
附带Decommission过程意外中断恢复步骤:
1-2)Datanode初次加入报给SCM的自身的Operational State。
1-3)SCM发现其处于decommission的状态,调度此节点为decommission模式。后续步骤同上述步骤3)~6)。
以上即为Ozone内部Decommission原理过程,如有感兴趣的同学,可点击以下相关JIRA。
相关链接
[1].https://issues.apache.org/jira/browse/HDDS-1880