AdaBoost
自适应增强-Adaptive Boosting
简单易懂 by hch
“强可学习”与“弱可学习”
Kearns和Valiant提出了“强可学习”(strongly learnable)和“弱可学习”(weakly learnable):在概率近似正确(probably approximately correct,PAC)学习框架下,一个概念如果存在多项式的学习算法学习它,并且正确率很高,那么这个概念就被称为强可学习的;一个概念,如果存在多项式的学习算法学习它,并且正确率只比随机猜测好一点,那么这个概念称为弱可学习的。
AdaBoost是干啥的?
上面说的“弱可学习”就没有一点用吗?我们构建出来“弱分类模型”,比胡猜好不了多少,这个模型就废了吗?假如我告诉你存在 集成方法,能够将这些“弱分类模型”结合起来变成“强学习模型”,你会想了解吗?
集成方法主要包括Bagging和Boosting两种方法
这两种方法都是把若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果,将不同的分类算法套入到此类算法框架中一定程度上会提高了原单一分类器的分类效果,但是也增大了计算量。
天上的朋友, 地上的朋友,山上的朋友,树上的朋友,水里的朋友,天台上的朋友, 铁窗后的朋友, 把你们的元气借给我!!!

AdaBoost的具体流程
训练集
| x | 特征值1 | 特征值2 | … | 特征值n | y |
|---|---|---|---|---|---|
| x1 | 1 | 0 | … | 1 | 0 |
| x2 | 0 | 1 | … | 1 | 1 |
| … | … | … | … | … | … |
| xm | 1 | 0 | … | 1 | 0 |
xj表示第j个样本,共有m个样本
xji表示第j个样本的第i维特征值
yj表示第j个样本的tag,即结果
我们试图通过已知tag的数据去训练模型,从而预测未知tag的数据
(下面数学公式有哪里不懂了,记得回来看这里的定义)
具体流程
D t ( j ) 表 示 第 t 轮 第 j 个 样 本 的 权 重 , 进 行 T 轮 更 新 Z t 表 示 第 t 轮 样 本 权 重 之 和 , Z t = ∑ j = 1 m D t ( i ) D_t(j)表示第t轮第j个样本的权重,进行T轮更新\\ Z_t表示第t轮样本权重之和,Z_t=\sum_{j=1}^{m}D_t(i) Dt(j)表示第t轮第j个样本的权重,进行T轮更新Zt表示第t轮样本权重之和,Zt=j=1∑mDt(i)
初 始 化 : D 1 ( i ) = 1 m , 样 本 权 重 目 前 都 是 1 / m Z 1 = ∑ j = 1 m D 1 ( j ) = 1 初始化: D_1(i)=\frac{1}{m},样本权重目前都是1/m\\ Z_1=\sum_{j=1}^mD_1(j)=1 初始化:D1(i)=m1,样本权重目前都是1/mZ1=j=1∑mD1(j)=1
For t in range(1,T):
利 用 第 一 个 弱 分 类 器 分 类 所 有 样 本 利用第一个弱分类器分类所有样本 利用第一个弱分类器分类所有样本
计 算 错 误 率 : ϵ = 未 正 确 分 类 的 样 本 数 目 全 部 样 本 数 目 m 计算错误率:\epsilon =\frac{未正确分类的样本数目}{全部样本数目m} 计算错误率:ϵ=全部样本数目m未正确分类的样本数目
计 算 该 分 类 器 的 权 重 : α = 1 2 ∗ l n ( ϵ 1 − ϵ ) 计算该分类器的权重:\alpha=\frac{1}{2}*ln(\frac{\epsilon}{1-\epsilon}) 计算该分类器的权重:α=21∗ln(1−ϵϵ)
更 新 每 一 个 样 本 的 权 重 : D t + 1 ( j ) = D t ( j ) Z t ∗ { e − α i f ( h θ ( x j ) = = y j ) e α i f ( h θ ( x j ) ! = y i ) 更新每一个样本的权重:D_{t+1}(j)=\frac{D_{t}(j)}{Z_t}*\begin{cases}e^{-\alpha} &if(h_\theta(x_j)==y_j)\\e^\alpha& if(h_\theta(x_j)!=y_i) \end{cases} 更新每一个样本的权重:Dt+1(j)=ZtDt(j)∗{ e−αeαif(hθ(xj)==yj)if(hθ(xj)!=yi)
Z t = ∑ j = 1 m D j Z_t=\sum_{j=1}^{m}D_j Zt=j=1∑mDj
循环完毕,利用集成模型预估结果:
g ( x ) = ∑ t = 1 T ( α ∗ h θ ( x ) ) g(x)=\sum_{t=1}^{T}(\alpha*h_\theta(x)) g(x)=t=1∑T(α∗hθ(x))
把每个模型的预测结果乘以它们的权重相加
试图理解具体流程:
维基百科:
AdaBoost方法是一种迭代算法,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率。每一个训练样本都被赋予一个权重,表明它被某个分类器选入训练集的概率。如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它被选中的概率就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。通过这样的方式,AdaBoost方法能“聚焦于”那些较难分(更富信息)的样本上。
我的话:
理解分类器的权重:
首先观察这个函数:
f ( ϵ ) = l n ( 1 − ϵ ϵ ) f(\epsilon)=ln(\frac{1-\epsilon}{\epsilon}) f(ϵ)=ln(ϵ1−ϵ)
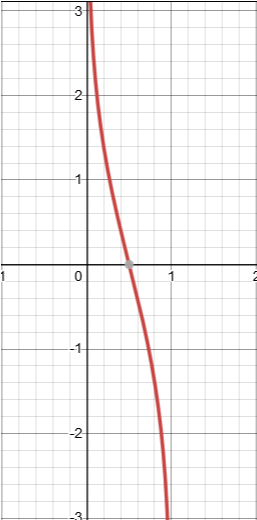
观察图像后,我们会发现这就是sigmoid函数给倒过来了嘛,我们自然也就清楚了它的意义,若趋向于1,则趋向于负无穷,若趋向于0,则趋向于正无穷。
也就是分类器预测的越对,则该权重越趋向于正无穷。
理解样本权重的更新:
对于样本权重:
∗ { e − α i f ( 预 测 对 了 ) e α i f ( 没 预 测 对 ) *\begin{cases} e^{-\alpha}&if(预测对了)\\e^\alpha&if(没预测对) \end{cases} ∗{
e−αeαif(预测对了)if(没预测对)
错误率低分类器的且对该样本分类对的会使该样本权重趋于0,符合上面维基百科的说法:
某个样本点已经被准确地分类,那么在构造下一个训练集中,它被选中的概率就被降低
反之分类器错误率很低,但该样本分类错了,就把这个样本权重提的很高
分类器错误率很高的话,预测对了,就把权重提的很高
分类器错误率很高的话,预测错了,就把权重趋向于0
