前言
最近在做一个爬虫项目,爬取微博评论,项目提测了,现在就来简单的总结一下。
项目架构
因为公司的架构体系,所以python不能直接连接redis,需要写一个java的项目,来做连接数据库的工具。所以整个项目包含了6部分:python(爬虫)、python(cookie生成器)、python(情感分析,用的snownlp的库),java(服务端:用于连接es、redis、mysql),java(展示端,用于展示评论,统计展示等),java(后台管理,配置账号、关键字、网址等)
爬虫
爬取微博的难点有三个:
- 登录的时候,网站有很多反扒策略,比如输入验证码等等,我们用的验证码工具是云打码
- 爬取数据分为全量爬取和增量爬取,在爬取过程中遇到异常,如何恢复到发生异常之前的状态
- 和java之间的通信问题,开始我们选用了nio的方式,但是后来决定改用http的方式,因为更加熟悉这个协议,而且代码看起来更加清晰易懂
一、登陆:第一版的时候我们是把登陆和爬虫写在一起,登陆后会生成cookie ,将cookie存到本地,下次还使用cookie登陆,如果失败了则重新从登录页进行登陆,而且账户信息都是写在项目的配置文件中,不容易修改,而且每一次都使用同一个账号,容易被微博识别出来
优化方案:java维护一个cookie池,为了便于理解,我将cookie池画了一个示意图
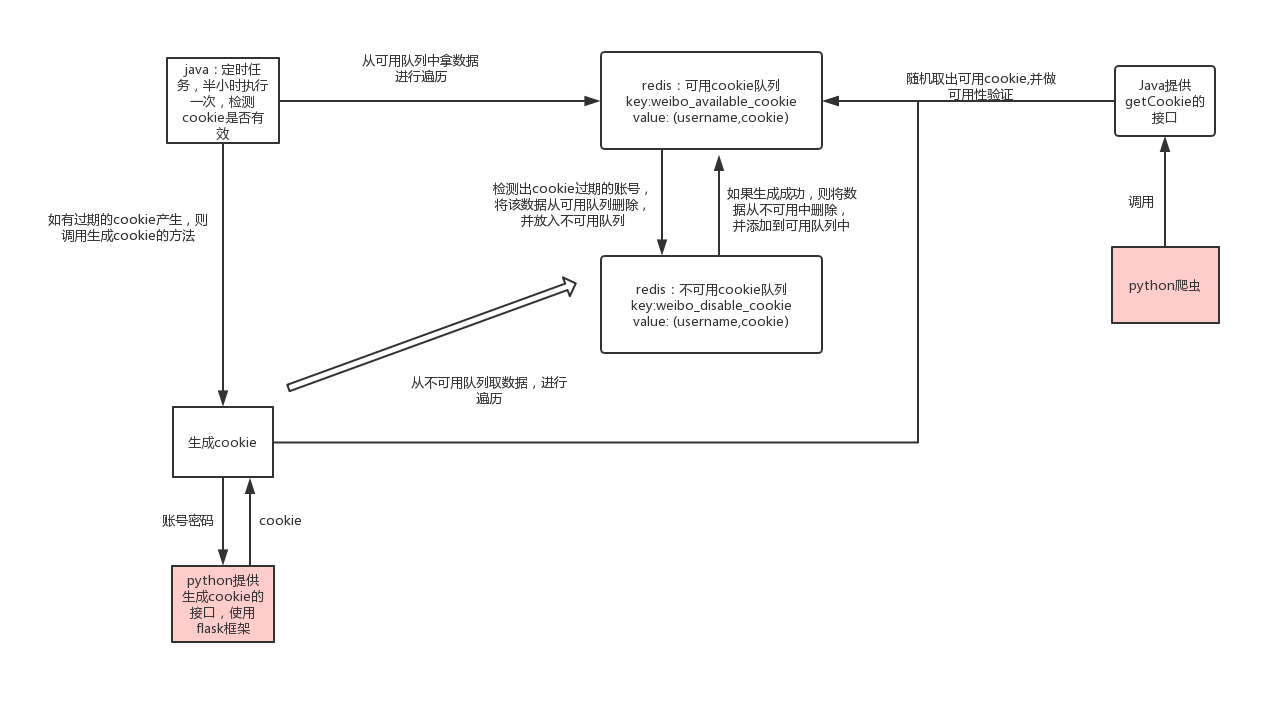
大体思路是这样的,其中一些小细节,比如多久检测一次,每个账号生成中间相隔时间,都需要根据有多少账号来做调整
这样,我们就将登陆这部分的功能从原来的爬虫拆分出去,爬虫的功能就更加的唯一
二、爬虫状态记录问题,在数据库中存储每个关键字的页数,在爬取过程中,先遍历关键字,然后从数据库中获得该关键字所在的页数,从这一页开始爬取,如果出现异常,则更新库中的关键字,记录下出现异常的页数,这样每一次即使异常退出了,也可以恢复到之前的状态。
我设置的爬取频率是半小时将所有的关键字爬一遍,但是是增量爬取,只爬前两页的数据;晚上在进行所有关键字的全量爬取
在爬取过程中还有一个需要注意的问题,那就是微博评论如何更新,我们想的策略是第一次爬取话题时,将话题的id和url等关键信息存在mysql中,然后如果下次再爬到该条微博,则直接跳过。更新评论的任务是另一个爬虫在做。这个爬虫会从mysql中取出话题的数据,进行遍历,如果评论数发生变化,则进行评论的爬取,如果没有变化则跳过
总结
这一篇简单的介绍了一下舆情系统的设计思路,具体的代码涉及公司的一些信息,不方便贴出来,但是github上有很多开源的代码,可以参考