
1.概述
本文是视频 视频 的笔记
2. 一致性hash算法哪里用?

一般情况下如果我们的数据很多,一台机器装不下,我们一般会采用分布式缓存,但是因为是分布式,我们要解决3个问题
- 数据怎么存储到分布式机器上,采用什么算法
- 数据查询的时候,如何知道我们的相关数据是缓存到那台机器了?
- 如果机器扩容的时候,算法如何兼容

2. 第一种简单类型

这种每次增加一个机器失效了 n分之一数据缓存丢失,如果是4台就是4分之3失效,如果是100就是 百分之99 失效。
这个值是怎么计算的呢?

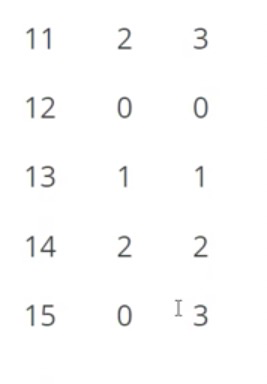
可以看到是两个数的最小公倍数。

这个加入一台机器可能导致缓存雪崩。
3. 一致性hash算法

这样情况下,如果加入一台机器,影响是无法计算的。因为和加入机器的位置有关,比如如下



优化,达到理想的情况下

redis就是采用这个原理,redis有16384个槽位。