我们都知道SQL的join关联表的使用方式,但是这次聊的是实现join的算法,join有三种算法,分别是Nested Loop Join,Hash join,Sort Merge Join。
MySQL官方文档中提到,MySQL只支持Nested Loop Join这一种join algorithm
MySQL resolves all joins using a nested-loop join method. This means that MySQL reads a row from the first table, and then finds a matching row in the second table, the third table, and so on.
explain-output
所以本篇只聊Nested Loop Join。
NLJ是通过两层循环,用第一张表做Outter Loop,第二张表做Inner Loop,Outter Loop的每一条记录跟Inner Loop的记录作比较,符合条件的就输出。而NLJ又有3种细分的算法:
1、Simple Nested Loop Join(SNLJ)
// 伪代码
for (r in R) {
for (s in S) {
if (r satisfy condition s) {
output <r, s>;
}
}
}

SNLJ就是两层循环全量扫描连接的两张表,得到符合条件的两条记录则输出,这也就是让两张表做笛卡尔积,比较次数是R * S,是比较暴力的算法,会比较耗时。
2、Index Nested Loop Join(INLJ)
// 伪代码
for (r in R) {
for (si in SIndex) {
if (r satisfy condition si) {
output <r, s>;
}
}
}
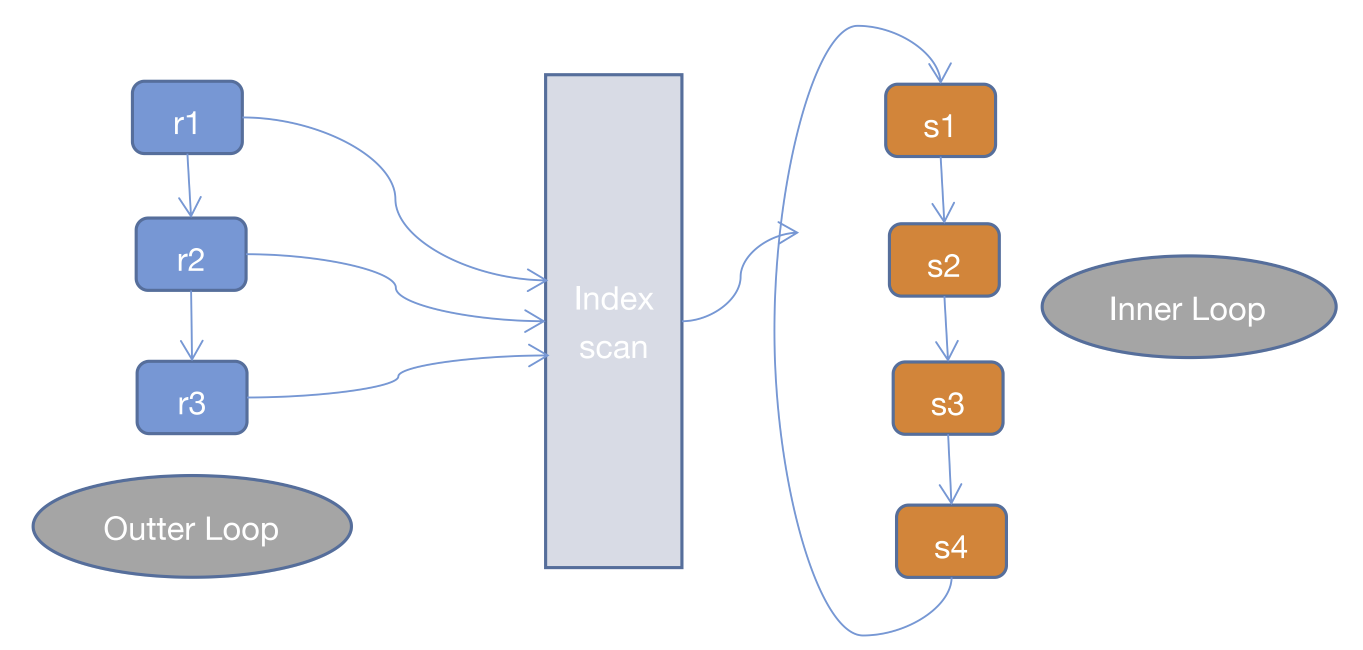
INLJ是在SNLJ的基础上做了优化,通过连接条件确定可用的索引,在Inner Loop中扫描索引而不去扫描数据本身,从而提高Inner Loop的效率。
而INLJ也有缺点,就是如果扫描的索引是非聚簇索引,并且需要访问非索引的数据,会产生一个回表读取数据的操作,这就多了一次随机的I/O操作。
3、Block Nested Loop Join(BNLJ)
一般情况下,MySQL优化器在索引可用的情况下,会优先选择使用INLJ算法,但是在无索引可用,或者判断full scan可能比使用索引更快的情况下,还是不会选择使用过于粗暴的SNLJ算法。
这里就出现了BNLJ算法了,BNLJ在SNLJ的基础上使用了join buffer,会提前读取Inner Loop所需要的记录到buffer中,以提高Inner Loop的效率。
// 伪代码
for (r in R) {
for (sbu in SBuffer) {
if (r satisfy condition sbu) {
output <r, s>;
}
}
}
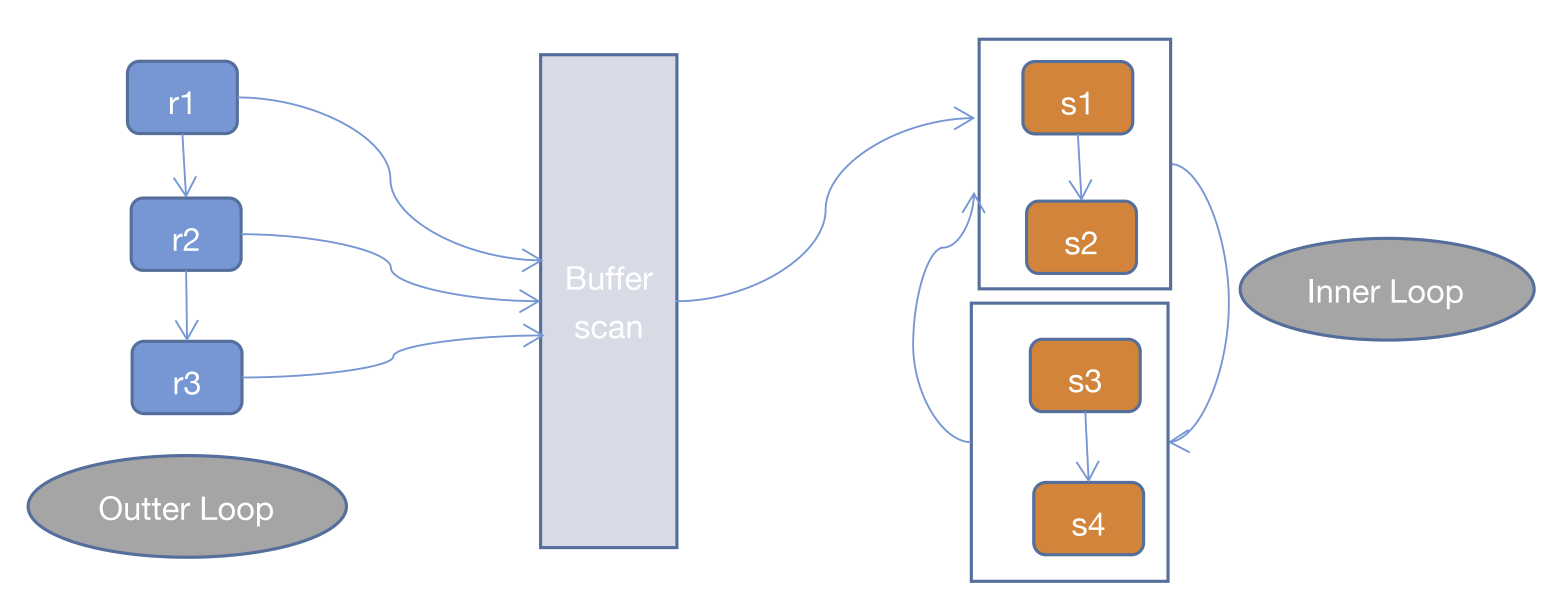
MySQL中控制join buffer大小的参数名是join_buffer_size。
We only store the used columns in the join buffer, not the whole rows.
join-buffer-size
根据MySQL手册中的说法,join_buffer_size缓冲的是被使用到的列。
算法比较(外表大小R,内表大小S):
| \algorithm comparison\ |
Simple Nested Loop Join | Index Nested Loop Join | Block Nested Loop Join |
|---|---|---|---|
| 外表扫描次数 | 1 | 1 | 1 |
| 内表扫描次数 | R | 0 |  |
| 读取记录次数 | R + R * S | R + RS_Matches |  |
| 比较次数 | R * S | R * IndexHeight | R * S |
| 回表次数 | 0 | RS_Matches | 0 |
在MySQL5.6中,对INLJ的回表操作进行了优化,增加了Batched Key Access Join(批量索引访问的表关联方式,这样翻译可以不。。。)和Multi Range Read(mrr,多范围读取)特性,在join操作中缓存所需要的数据的rowid,再批量去获取其数据,把I/O从多次零散的操作优化为更少次数批量的操作,提高效率。
MySQL如何查看开启NLJ(Nested Loop Join)算法
SELECT @@optimizer_switch;
index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on,use_index_extensions=on.如何开启NLJ(Nested Loop Join)
开启/关闭 block_nested_loop = on/off
set @@optimizer_switch = 'index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on';验证开启成功
EXPLAIN SELECT * FROM appt_appointment t1 JOIN phe_institution t2;