1 概述
- 管道函数为 并行执行,在普通函数中使用
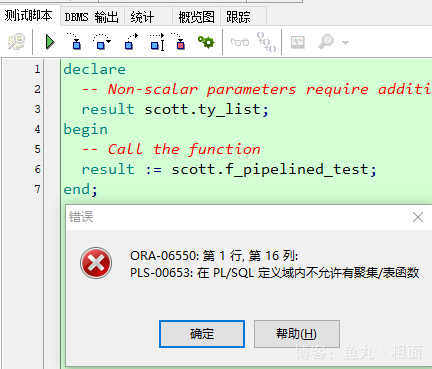
dbms_output输出的信息,需要等服务器执行完整个函数后一次性返回给客户端。如果需要在客户端 实时 输出函数执行过程中的一些信息,在 Oracle9i 以后,可以使用管道函数(大数据处理时,性能提升)。 - 关键字
pipelined表明这是一个 oracle 管道函数,其返回值类型必须为 集合,在函数中,pipe row语法被用来返回该集合的 单个元素,函数以一个空的return语句结束,以表明它已经完成。
2 实例
2.1 首先创建一个表类型
-- 直接定义类型
CREATE OR REPLACE TYPE scott.ty_list IS TABLE OF VARCHAR2(300);
-- PL/SQL 中可在 package head 中定义
-- index by ... 是为了不再手动扩充 extend(1)
TYPE scott.ty_list IS TABLE OF VARCHAR2(300) INDEX BY PLS_INTEGER;
2.2 实时返回数据
准备:
1. arraysize 是 sql*plus 中可以设置的一个参数: 表示一次可以从数据库服务端获取的记录行数
2. 首先需要设置 arraysize 为 1,否则服务器会按照默认的 15 来向客户端返回信息,这会影响我们测试效果
3. 查询命令: show arraysize
4. 设置命令: set arraysize 15
验证:PL/SQL 代码:
管道函数:
CREATE OR REPLACE FUNCTION scott.f_pipelined_test RETURN scott.ty_list
PIPELINED IS
BEGIN
PIPE ROW('start...');
FOR i IN 1 .. 5 LOOP
PIPE ROW(i || ' ' || to_char(SYSDATE, 'YYYY-MM-DD HH24:MI:SS'));
sys.dbms_lock.sleep(1); -- 等待 1 秒
END LOOP;
PIPE ROW('end...');
RETURN;
END;
/
一般函数:
CREATE OR REPLACE FUNCTION scott.f_normal_test RETURN scott.ty_list IS
v_list_out_put scott.ty_list;
BEGIN
-- 初始化
v_list_out_put := scott.ty_list();
-- 扩展信息,可在 package 定义 type 时,增加 index by pls_integer 自动扩展 extend
FOR i IN 1 .. 5 LOOP
v_list_out_put.extend(1); -- 手动扩展
v_list_out_put(i) := i || ' ' ||
to_char(SYSDATE, 'YYYY-MM-DD HH24:MI:SS');
sys.dbms_lock.sleep(1); -- 等待 1 秒
END LOOP;
RETURN v_list_out_put;
END;
/
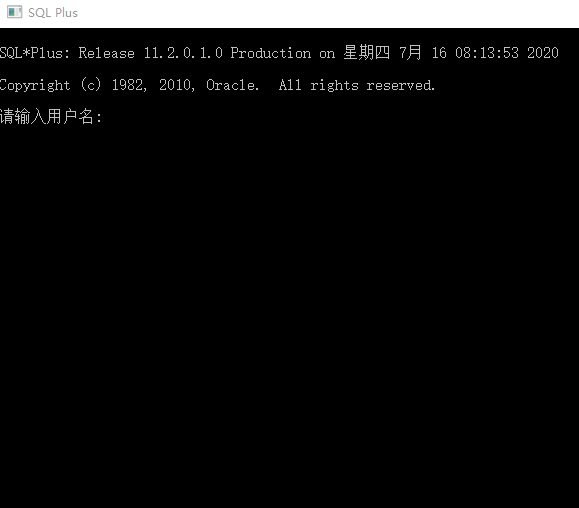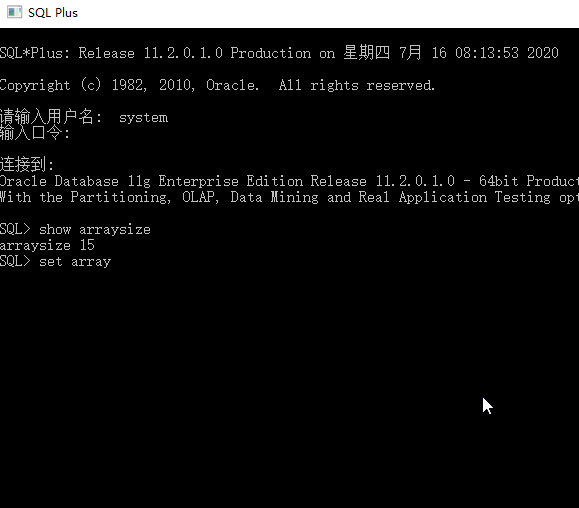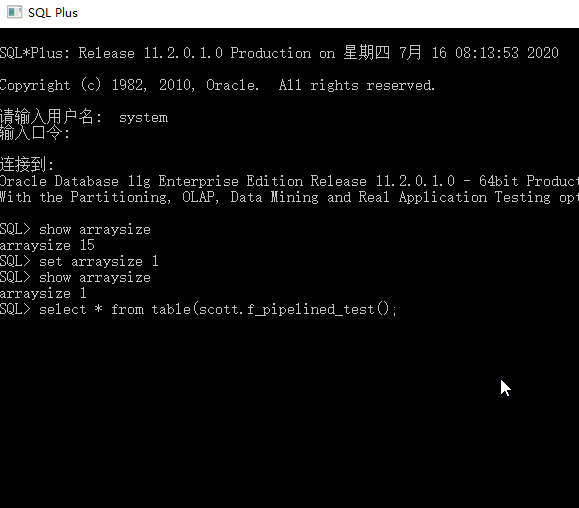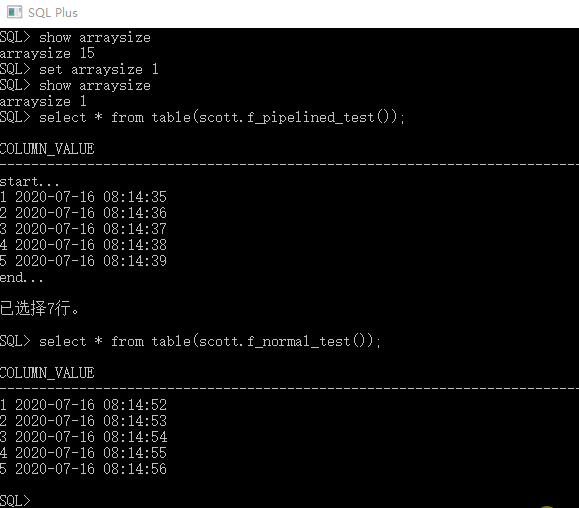
sql*plus 窗口验证演示
小提示:
sql*plus是与 Oracle 进行交互的 客户端 工具(安装 Oracle 客户端时自带)plsql是一款很好的可视化开发工具
结论:
- 管道函数:实时输出
- 一般函数:运算完成后输出
动态图示:
3 其它实例
| 序号 | 描述 |
|---|---|
| 1 | 管道函数不支持 debug |
| 2 | 字符串切割 split |
暂时用到这些,后续若还有,继续补充…
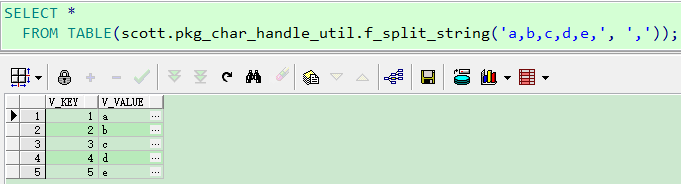
效果展示:
首先定义类型:
CREATE TYPE scott.ty_object_map IS OBJECT
(
v_key NUMBER,
v_value VARCHAR2(100)
)
;
/
CREATE TYPE scott.ty_table_map IS TABLE OF scott.ty_object_map;
/
-- 删除type、若需要
DROP TYPE scott.ty_table_map;
DROP TYPE scott.ty_object_map;
package head:
CREATE OR REPLACE PACKAGE scott.pkg_char_handle_util IS
FUNCTION f_split_string(p_string IN VARCHAR2,
p_delimiter IN VARCHAR2) RETURN scott.ty_table_map
PIPELINED;
END pkg_char_handle_util;
/
package body:
CREATE OR REPLACE PACKAGE BODY scott.pkg_char_handle_util IS
--************************************************
-- 功能: 切割字符串
-- 参数: p_string 字符串
-- p_delimiter 分隔符
-- 返回值: table 类型
--************************************************
FUNCTION f_split_string(p_string IN VARCHAR2,
p_delimiter IN VARCHAR2) RETURN scott.ty_table_map
PIPELINED IS
v_length PLS_INTEGER := length(p_string); -- 字符串长度
v_start PLS_INTEGER := 1; -- 字符开始位置
v_index PLS_INTEGER; -- 下标
v_key PLS_INTEGER := 1; -- 截取后,字符串的个数
v_object_map scott.ty_object_map;
BEGIN
WHILE (v_start <= v_length) LOOP
-- 获取符合条件的 第一个下标
v_index := instr(p_string, p_delimiter, v_start);
IF v_index = 0 THEN
-- 没有符合条件的记录,直接打印,如 string = 'a', 直接打印 a
v_object_map := scott.ty_object_map(v_key,
substr(p_string, v_start));
PIPE ROW(v_object_map);
RETURN;
ELSE
-- 否则,循环截取打印
v_object_map := scott.ty_object_map(v_key,
substr(p_string,
v_start,
v_index - v_start));
PIPE ROW(v_object_map);
-- 循环判断依据: 每次 '分隔符' 后 '第一个字符'
v_start := v_index + 1;
END IF;
-- 个数递增
v_key := v_key + 1;
END LOOP;
RETURN;
END f_split_string;
END pkg_char_handle_util;
/