由“源代码”到“可执行文件”的过程包括四个步骤:预编译、编译、汇编、链接。所以,首先就应该清楚的首要问题就是:预编译只是对程序的文本起作用,换句话说就是,预编译阶段仅仅对源代码的单词进行变换,而不是对程序中的变量、函数等。
预编译指令的基本知识不作详细介绍,只稍作汇总,重点是后面的我能想到的 使用时的注意事项。
1. 基本内容
预编译指令基本分类如下
类别 |
指令 |
| 预定义符号 | __FILE__、__LINE__、__DATE__、__TIME__、__STDC__ |
| 宏 | #define |
| 文件包含 | #include |
| 条件编译 | #if、#elif、#else、#ifdef、#ifndef、#endif |
还有一些指令,名称和功能如下表:
| 指令 | 功能 |
| # | 空指令 |
| #undef | 移除一个空定义 |
| #error | 停止编译,并生成错误信息 |
| #line | 修改__LINE__和__FILE__的值 |
| #progma | 允许编译器提供额外功能 |
在定义宏的时候,有两个运算符:
| 运算符 | 功能 |
| # | 将宏参数转换为字符串 |
| ## | 将多个符号连接成一个标识符 |
2. 宏定义
1. 一般在宏定义的结尾不加分号。
我们在使用的时候,要加上分号,像我们平时写语句一样。
2. 注意加括号。
在有参数的空定义中,如果含有数值运算,那么就要在“宏整体”和“宏参数”两端都要加上括号。
如:#define max(a, b) ((a)+(b));
3. 注意空格。
在有参数的宏定义中,注意“宏名称”和“参数列表”之间不能有空格。
如:#define max (a, b) ((a)+(b)); 在"max”和”(a, b)”之间不能有空格。
4. 不要使用有副作用的参数区调用宏。
常见的有副作用的参数有:a++,getchar()等。
如:宏定义为#define max (a, b) ((a)+(b)); 那么使用max(i++, j++)调用该宏,会造成 i 或 j 中的一个值增加2,而不是我们期望的 1。
5. 可以使用编译器选项 添加宏 和 移除宏。
我使用的是gcc,添加宏的指令是”-D”,移除宏的指令是”-U”。
6. 宏参数替换的时候,不会替换字符串中的字符。
即不会替换双引号之间的字符,其他的都会被替换,包括单引号之间的。
7. 可以使用#将 宏参数的值 转化为字符串。
直接使用#,是将宏参数的名称转化为字符串。利用下面的技巧(增加一个过渡宏),可以将“宏参数的值”转化为字符串(当宏参数有值时,这时的宏参数常常也是一个宏)。
- #include <stdio.h>
- #include <stdlib.h>
- #define NUMBER ten /* 宏名称为NUMBER,宏的值为ten */
- #define Str(x) #x
- #define XStr(x) Str(x) /* 增加的一个 过渡宏 */
- int main(){
- printf("Str(NUMBER) == %s /n", Str(NUMBER));
- printf("XStr(NUMBER) == %s /n", XStr(NUMBER));
- system("pause");
- return EXIT_SUCCESS;
- }
输出结果为:
- Str(NUMBER) == NUMBER
- XStr(NUMBER) == ten
8. 使用##运算符来实现标识符连接。
不过,不建议使用操作符##来连接标识符,因为这个容易是程序可读性大大降低。
3. 文件包含
1. 要将头文件的定义在保护条件中。
目的是为了防止重复包含头文件。如果你查看过gcc或者其他编译器的源代码,你一定对这个非常熟悉。
例如,你要编写一个头文件,myheader.h,那么你的头文件的内容形式应该为:(定义一个_MYHEADER宏)
- #ifndef _MYHEADER
- #define _MYHEADER 1
- /* 中间是你的头文件内容 */
- #endif /* _MYHEADER */
2. 注意windows系统和Unix系统的路径符号不同。
可以再#include中指定路径来包含文件,例如 #include “../head.h”。但是注意,windows中使用反斜线”/”作为路径分隔符,而Unix系统使用的是斜线”/”。
3. 可以使用 编译器选项 来设置搜索路径。
我使用的gcc,使用的-Idir选项,例如: -I"D:/Dev-Cpp/include"。
4. 条件编译
1. #ifdef等价于#if defined(),#ifndef等价于#if !defined()。
2. 在#if中可以使用逻辑操作符(&&、||、!)。在#ifdef 中是不可以使用的,这也是#if的优越点。
- #include <stdio.h>
- #include <stdlib.h>
- #define A 1
- #define B 0
- int main(){
- #if defined( A ) && defined( B )
- printf("test logic operation in #if /n"); /* 如果上面的逻辑判断成立,那么将打印出一句话;如果不成立,那么就不会打印这句话 */
- #endif
- system("pause");
- return EXIT_SUCCESS;
- }
运行结果:
- test logic operation in #if
3. sizeof(int)在预编译阶段是不会被求值的。
只要知道“预编译阶段”在真正的“编译阶段”之前,就很容易理解了。预编译阶段只是对组成源代码中的字符进行作用,从某种意义上来说,它有时甚至不知道它的操作对象是什么,它只是按照既定的规则执行替换。
sizeof(int),无论是sizeof的解析,还是类型的解析,都是在“编译阶段”才开始的,编译阶段知道它的操作对象是什么。
下面的代码是错误的
- #if sizeof(int) == 2
- printf("precompile sizeof(int)");
- #endif
5. 额外注意
把一个预处理指令写成多行的形式,要使用符号”/”,并且在该符号后面应紧跟换行符。而非预处理指令的代码行不需要使用该符号,直接换行即可。 原因:编译阶段会自动忽略空白符,而预编译阶段不会。
预处理
预处理是一种展开,下表是常用的一些预处理命令

还有下列几种预处理宏(是双下划线)
__LINE__ 表示正在编译的文件的行号
__FILE__表示正在编译的文件的名字__DATE__表示编译时刻的日期字符串,例如: "25 Dec 2007"
__TIME__ 表示编译时刻的时间字符串,例如: "12:30:55"
__STDC__ 判断该文件是不是定义成标准 C 程序
我的vs2013不是定义的标准c语言
宏函数很好用,是直接展开,在这我顺便说一下宏的好处和坏处。
宏优点1代码复用性2提高性能
宏缺点1 不可调试(预编译阶段进行了替换),2无类型安全检查3可读性差,容易出错。
这里附上《c和指针》中的一张表格,总结宏和函数十分到位,我就不多说了
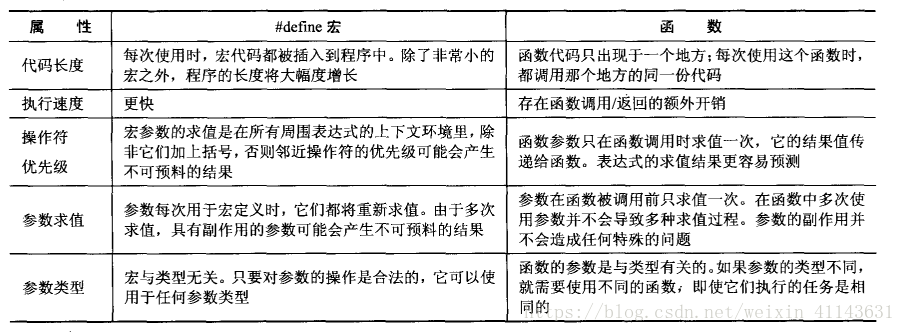
宏函数很皮,#define定义一个比如判断大小,替换常量,很是方便。
不过我现在也就用下,#define ERROR_POWEROFF -1,#define _CRT_SECURE_NO_WARNINGS 1这样的和编译器有关的东西,不会去写宏函数,宏函数这东西,可读性特别差,在c++中,一般用const/枚举/内联去替代宏。
但是,define宏在某些方面真的是非常好用,我很推荐。
1.替代路径
#define ENG_PATH_1 C:\Program Files (x86)
2.针对编译器版本不兼容报错
#define _CRT_SECURE_NO_WARNINGS 1
3.条件编译
#ifdef 标识符
程序段 1
#else
程序段 2
#endif
4.使用库中的宏
vc++中有许多有意思的宏,都是大牛们写出来的,真的是充满智慧,十分刁钻,怎么学也学不完,我个人担心出错就很少写宏,用函数代替了。在以后的博客中我会记录一些常用的,充作笔记。
emmm,当然,还有其他许多重要的预处理。
比如
include
#include <filename>
尖括号是预处理到系统规定的路径中去获得这个文件(即 C 编译系统所提供的并存放在指定的子目录下的头文件)。找到文件后,用文件内容替换该语句。如stdio.h
#include“filename”
“”则是预处理我们自己第三方的文件,如程序员小刘写的Date.h,我们就可以include“Date.h”
#error 预处理,#line 预处理,#pragma 预处理
#error 预处理指令的作用是,编译程序时,只要遇到 #error 就会生成一个编译错误提示消息,并停止编译。
这个我没写过,但碰到过很多次,在编写mfc代码中,拉入控件时我加入密码框控件,OS编译时会自动弹出#error 提示我该编辑框为密码,注意明文问题
#line 的作用是改变当前行数和文件名称,如#line 28 liu
目前我没使其派上用场,但了解为好。
#pragma 是比较重要且困难的预处理指令。
#pragma once
这个的做用就是防止头文件多次包含
当然,还有另外一种风格,防止被包含,我同时给出来
是巧妙地利用了define宏
-
#ifndef _SOME_H
-
#define _SOME_H
-
-
-
...
//(some.h头文件内容)
-
-
-
#endif
变量的防止重复定义则利用extern,在头文件中不初始化只声明。引用该头文件即可,在链接过程中。就可以使用到这个变量。
(附:extern在c++中经常用于 extern "C" 告诉编译器下面是c语言风格)
#pragma warning
#pragma warning( disable : 4507 34; once : 4385; error : 164 )
等价于:
#pragma warning(disable:4507 34) // 不显示 4507 和 34 号警告信息
#pragma warning(once:4385) // 4385 号警告信息仅报告一次
#pragma warning(error:164) // 把 164 号警告信息作为一个错误。
另外还有
#pragma pack
使用指令#pragma pack (n),编译器将按照 n 个字节对齐。
使用指令#pragma pack (),编译器将取消自定义字节对齐方式。
在#pragma pack (n)和#pragma pack ()之间的代码按 n 个字节对齐。
字节对齐,我将另起炉灶,在另外一篇博客中归纳总结。
#pragma pack(push) //保存当前对其方式到 packing stack
#pragma pack(push,n) 等效于
#pragma pack(push)
#pragma pack(n) //n=1,2,4,8,16 保存当前对齐方式,设置按 n 字节对齐
#pragma pack(pop) //packing stack 出栈,并将对其方式设置为出栈的对齐
#运算符和##预算符
#define SQR(x) printf("The square of "#x" is %d.\n", ((x)*(x)));
这段代码中#就是帮助x作为一个变量,表现出来,而不是一个简单的字母
如果有#,SQR(3)运算出来就是
The square of 3 is 9
如果没有# SQL(3)运算出来就是
The square of x is 9
##预算符
##把两个语言符号组合成单个语言符号
概览
从hello world说起。
#include <stdio.h>
int main()
{
printf("Hello world\n"):
return 0;
}
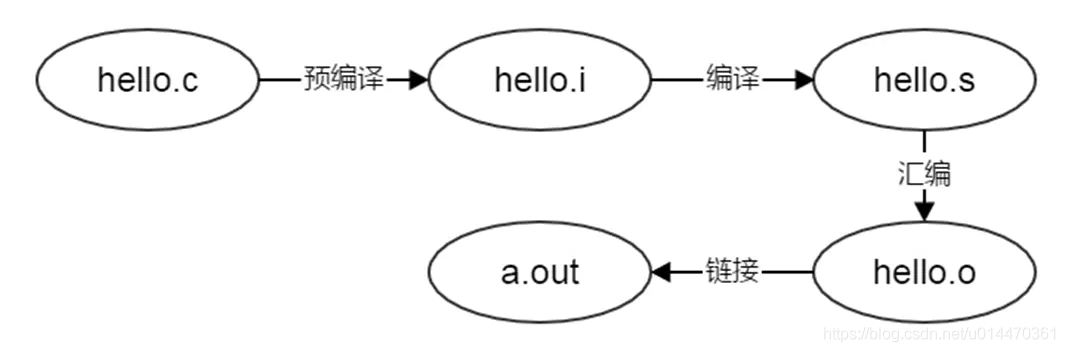
预编译过程测试
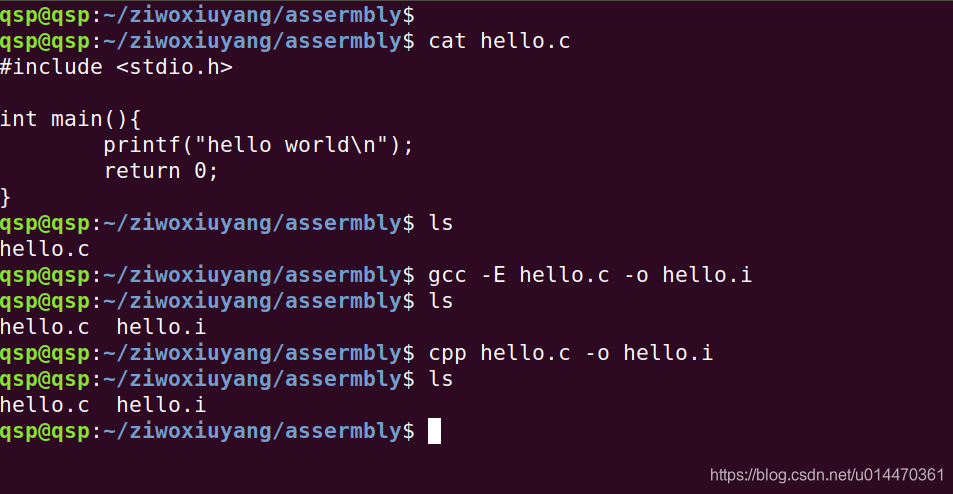
vim hello.i , 如下:

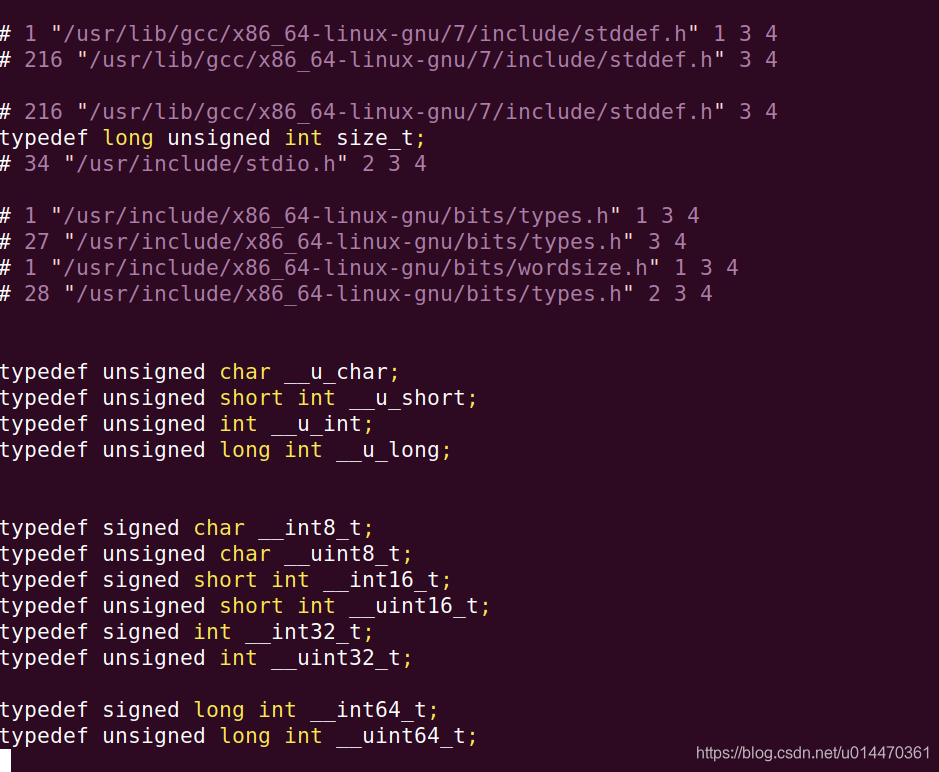
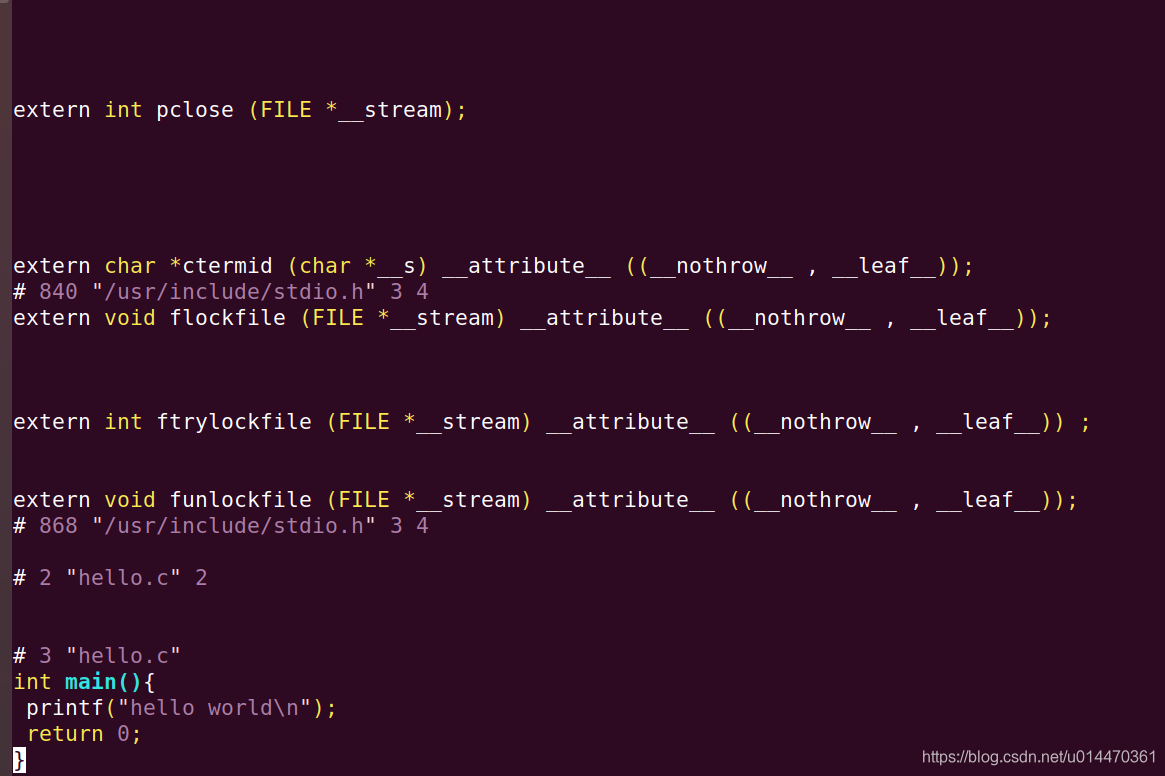
编译过程到底发生了什么?
·将所有的#define删除,并且展开所有的宏定义
·处理所有的条件预编译指令,比如#if #ifdef #elif #else #endif等
·处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。
·删除所有注释“//”和”/* */”.
·添加行号和文件标识,以便编译时产生调试用的行号及编译错误警告行号。
·保留所有的#pragma编译器指令,因为编译器需要使用它们
经过预编译后的.i文件不含任何宏定义,所有的宏已经被展开并且插入到.i文件中。
以上即为预编译过程发生的事情。当怀疑宏定义错误或者头文件包含不对时,可以生成预编译的.i文件来调试定位问题。
由“源代码”到“可执行文件”的过程包括四个步骤:预编译、编译、汇编、链接。所以,首先就应该清楚的首要问题就是:预编译只是对程序的文本起作用,换句话说就是,预编译阶段仅仅对源代码的单词进行变换,而不是对程序中的变量、函数等。
预编译指令的基本知识不作详细介绍,只稍作汇总,重点是后面的我能想到的 使用时的注意事项。
1. 基本内容
预编译指令基本分类如下
类别 |
指令 |
| 预定义符号 | __FILE__、__LINE__、__DATE__、__TIME__、__STDC__ |
| 宏 | #define |
| 文件包含 | #include |
| 条件编译 | #if、#elif、#else、#ifdef、#ifndef、#endif |
还有一些指令,名称和功能如下表:
| 指令 | 功能 |
| # | 空指令 |
| #undef | 移除一个空定义 |
| #error | 停止编译,并生成错误信息 |
| #line | 修改__LINE__和__FILE__的值 |
| #progma | 允许编译器提供额外功能 |
在定义宏的时候,有两个运算符:
| 运算符 | 功能 |
| # | 将宏参数转换为字符串 |
| ## | 将多个符号连接成一个标识符 |
2. 宏定义
1. 一般在宏定义的结尾不加分号。
我们在使用的时候,要加上分号,像我们平时写语句一样。
2. 注意加括号。
在有参数的空定义中,如果含有数值运算,那么就要在“宏整体”和“宏参数”两端都要加上括号。
如:#define max(a, b) ((a)+(b));
3. 注意空格。
在有参数的宏定义中,注意“宏名称”和“参数列表”之间不能有空格。
如:#define max (a, b) ((a)+(b)); 在"max”和”(a, b)”之间不能有空格。
4. 不要使用有副作用的参数区调用宏。
常见的有副作用的参数有:a++,getchar()等。
如:宏定义为#define max (a, b) ((a)+(b)); 那么使用max(i++, j++)调用该宏,会造成 i 或 j 中的一个值增加2,而不是我们期望的 1。
5. 可以使用编译器选项 添加宏 和 移除宏。
我使用的是gcc,添加宏的指令是”-D”,移除宏的指令是”-U”。
6. 宏参数替换的时候,不会替换字符串中的字符。
即不会替换双引号之间的字符,其他的都会被替换,包括单引号之间的。
7. 可以使用#将 宏参数的值 转化为字符串。
直接使用#,是将宏参数的名称转化为字符串。利用下面的技巧(增加一个过渡宏),可以将“宏参数的值”转化为字符串(当宏参数有值时,这时的宏参数常常也是一个宏)。
- #include <stdio.h>
- #include <stdlib.h>
- #define NUMBER ten /* 宏名称为NUMBER,宏的值为ten */
- #define Str(x) #x
- #define XStr(x) Str(x) /* 增加的一个 过渡宏 */
- int main(){
- printf("Str(NUMBER) == %s /n", Str(NUMBER));
- printf("XStr(NUMBER) == %s /n", XStr(NUMBER));
- system("pause");
- return EXIT_SUCCESS;
- }
输出结果为:
- Str(NUMBER) == NUMBER
- XStr(NUMBER) == ten
8. 使用##运算符来实现标识符连接。
不过,不建议使用操作符##来连接标识符,因为这个容易是程序可读性大大降低。
3. 文件包含
1. 要将头文件的定义在保护条件中。
目的是为了防止重复包含头文件。如果你查看过gcc或者其他编译器的源代码,你一定对这个非常熟悉。
例如,你要编写一个头文件,myheader.h,那么你的头文件的内容形式应该为:(定义一个_MYHEADER宏)
- #ifndef _MYHEADER
- #define _MYHEADER 1
- /* 中间是你的头文件内容 */
- #endif /* _MYHEADER */
2. 注意windows系统和Unix系统的路径符号不同。
可以再#include中指定路径来包含文件,例如 #include “../head.h”。但是注意,windows中使用反斜线”/”作为路径分隔符,而Unix系统使用的是斜线”/”。
3. 可以使用 编译器选项 来设置搜索路径。
我使用的gcc,使用的-Idir选项,例如: -I"D:/Dev-Cpp/include"。
4. 条件编译
1. #ifdef等价于#if defined(),#ifndef等价于#if !defined()。
2. 在#if中可以使用逻辑操作符(&&、||、!)。在#ifdef 中是不可以使用的,这也是#if的优越点。
- #include <stdio.h>
- #include <stdlib.h>
- #define A 1
- #define B 0
- int main(){
- #if defined( A ) && defined( B )
- printf("test logic operation in #if /n"); /* 如果上面的逻辑判断成立,那么将打印出一句话;如果不成立,那么就不会打印这句话 */
- #endif
- system("pause");
- return EXIT_SUCCESS;
- }
运行结果:
- test logic operation in #if
3. sizeof(int)在预编译阶段是不会被求值的。
只要知道“预编译阶段”在真正的“编译阶段”之前,就很容易理解了。预编译阶段只是对组成源代码中的字符进行作用,从某种意义上来说,它有时甚至不知道它的操作对象是什么,它只是按照既定的规则执行替换。
sizeof(int),无论是sizeof的解析,还是类型的解析,都是在“编译阶段”才开始的,编译阶段知道它的操作对象是什么。
下面的代码是错误的
- #if sizeof(int) == 2
- printf("precompile sizeof(int)");
- #endif
5. 额外注意
把一个预处理指令写成多行的形式,要使用符号”/”,并且在该符号后面应紧跟换行符。而非预处理指令的代码行不需要使用该符号,直接换行即可。 原因:编译阶段会自动忽略空白符,而预编译阶段不会。