1.1 kafaka 简介
Apache Kafka 是一个快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统,
使用 Scala 与 Java 语言编写,能够将消息从一个端点传递到另一个端点,较之传统的消息中间件(例如 ActiveMQ、RabbitMQ),Kafka 具有高吞吐量、内置分区、支持消息副本和高容错的特性,非常适合大规模消息处理应用程序。
Kafka 官网: http://kafka.apache.org/
1.2 Kafa 系统架构

1.3 应用场景
Kafka 的应用场景很多,这里就举几个最常见的场景。
1.3.1 用户的活动追踪
用户在网站的不同活动消息发布到不同的主题中心,然后可以对这些消息进行实时监测实时处理。当然,也可加载到 Hadoop 或离线处理数据仓库,对用户进行画像。像淘宝、京东这些大型的电商平台,用户的所有活动都是要进行追踪的。
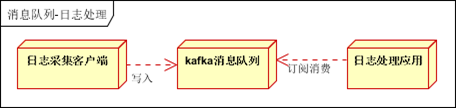
1.3.2 日志聚合
1.3.3 限流削峰

1.4 kafka 高吞吐率实现
Kafka 与其它 MQ 相比,其最大的特点就是高吞吐率。为了增加存储能力,Kafka 将所有的消息都写入到了低速大容的硬盘。按理说,这将导致性能损失,但实际上,kafka 仍可保持超高的吞吐率,性能并未受到影响。其主要采用了如下的方式实现了高吞吐率。
顺序读写:Kafka 将消息写入到了分区 partition 中,而分区中消息是顺序读写的。顺序读写要远快于随机读写。
零拷贝:生产者、消费者对于 kafka 中消息的操作是采用零拷贝实现的。
批量发送:Kafka 允许使用批量消息发送模式。
消息压缩:Kafka 支持对消息集合进行压缩。
1.5 流处理
kafka消息处理包含多个阶段。其中原始输入数据是从kafka主题消费的,然后汇总,丰富,或者以其他的方式处理转化为新主题,例如,一个推荐新闻文章,文章内容可能从“articles”主题获取;然后进一步处理内容,得到一个处理后的新内容,最后推荐给用户。这种处理是基于单个主题的实时数据流。从0.10.0.0开始,轻量,但功能强大的流处理,就进行这样的数据处理了