写在前面
C S P 2019 d a y 1 CSP2019day1 CSP2019day1 无脑挂掉 150 ! 150! 150!
再次被老师嘲讽没考过 0 0 0基础的
这么一说 学 O I 3 OI3 OI3年了一事无成见证了一届又一届学长从巅峰到成功 从低谷到辉煌 从 0 0 0基础一步一步超过自己 而自己却仍然在原地踏步…
已经高一了 还有最后一次联赛的机会了…留给自己的时间已经不多了 既然初二玩的这么开心 高一一定要努力了
从这篇文章开始 给自己定个小目标 最慢每周自学两篇提高篇一节的知识点 一共 30 30 30篇 要在放假之前做完 20 20 20篇
P S : PS: PS:虽然被迫进不了机房 不过光老师还是很贴心地为我保留了一个账号可以让我刷题 真是太感谢了哈哈哈
o k ok ok进入正题
首先什么是哈希?
哈希
哈希算法就是通过引入一个哈希函数 H H H,将一种数据(包括字符串、较大的数等)转化为能够用变量表示火是直接就可作为数组下标的数,通过哈希函数转化得到的数值我们称之为哈希值。通过哈希值可以实现快速查找和匹配。蓝书里给出了两个:一个是字符串 H a s h Hash Hash,一个是哈希表
字符串 H a s h Hash Hash
字符串 H a s h Hash Hash具体来说就是将字符串转化为可以用变量表示的数据,主要用于解决字符串匹配的问题。大多数都可以用 K M P KMP KMP看毛片算法解决。但不是说 H a s h Hash Hash就没用了,如果是从子串中每次选出两个子串判断是否匹配的问题,还是要用字符串 H a s h Hash Hash求解。
如果我们用 O ( m ) O(m) O(m)的时间计算长度为 m m m的字符串,跟打暴力没什么区别了,所以要用到一个叫滚动哈希的东西。其实很个人感觉可以类比成前缀和
我们选取两个合适的互质常数 b b b和 m ( b < m ) m\,\,(b<m) m(b<m),假设字符串 C = c 1 c 2 . . . c m C=c_1c_2...c_m C=c1c2...cm,那么我们定义哈希数: H ( C ) = ( c 1 b m − 1 + c 2 b m − 2 + . . . + c m b 0 ) m o d m H(C)=(c_1b^{m-1}+c_2b^{m-2}+...+c_mb^{0})\,mod\,\,m H(C)=(c1bm−1+c2bm−2+...+cmb0)modm 其实相当于把字符串看做是 b b b进制数。
这一过程是递推计算的,设 H ( C , k ) H(C,k) H(C,k)为前 k k k个字符构成的字符串的哈希值,则:
H ( C , k + 1 ) = H ( c , k ) × b + c k + 1 H(C,k+1)=H(c,k)×b+c_{k+1} H(C,k+1)=H(c,k)×b+ck+1
通常,题目要求的是判断主串中的一段字符与另一个匹配串是否匹配,即判断字符串 C = c 1 c 2 . . . c m C=c_1c_2...c_m C=c1c2...cm从位置 k + 1 k+1 k+1开始的长度为 n n n的子串 C ′ = c k + 1 c k + 2 . . . c k + n C'=c_{k+1}c_{k+2}...c_{k+n} C′=ck+1ck+2...ck+n的哈希值与另一匹配串 S = s 1 s 2 . . . s n S=s_1s_2...s_n S=s1s2...sn的哈希值是否相等,则 H ( C ′ ) = H ( C , k + n ) − H ( C , k ) × b n H(C')=H(C,k+n)-H(C,k)×b^n H(C′)=H(C,k+n)−H(C,k)×bn
于是我们只需要预求出 b n b^n bn,就能在 O ( 1 ) O(1) O(1)的时间内得到任意字符串的子串哈希值,从而完成字符串匹配,那么上述字符串匹配问题的算法时间复杂的就为 O ( n + m ) O(n+m) O(n+m)。
上题:
乌力波(oulipo)
题目描述
法国作家乔治·佩雷克(Georges Perec,1936-1982)曾经写过一本书,《敏感字母》(La disparition),全篇没有一个字母‘e’。他是乌力波小组(Oulipo Group)的一员。下面是他书中的一段话:
Tout avait Pair normal, mais tout s’affirmait faux. Tout avait Fair normal, d’abord, puis surgissait l’inhumain, l’affolant. Il aurait voulu savoir où s’articulait l’association qui l’unissait au roman : stir son tapis, assaillant à tout instant son imagination, l’intuition d’un tabou, la vision d’un mal obscur, d’un quoi vacant, d’un non-dit : la vision, l’avision d’un oubli commandant tout, où s’abolissait la raison : tout avait l’air normal mais…
鬼鬼?

佩雷克很可能在下面的比赛中得到高分(当然,也有可能是低分)。在这个比赛中,人们被要求针对一个主题写出甚至是意味深长的文章,并且让一个给定的“单词”出现次数尽量少。我们的任务是给评委会编写一个程序来数单词出现了几次,用以得出参赛者最终的排名。参赛者经常会写一长串废话,例如500000个连续的‘T’。并且他们不用空格。
因此我们想要尽快找到一个单词出现的频数,即一个给定的字符串在文章中出现了几次。更加正式地,给出字母表{‘A’,‘B’,‘C’,…,‘Z’}和两个仅有字母表中字母组成的有限字符串:单词W和文章T,找到W在T中出现的次数。这里“出现”意味着W中所有的连续字符都必须对应T中的连续字符。T中出现的两个W可能会部分重叠。
输入
输入包含多组数据。
输入文件的第一行有一个整数,代表数据组数。接下来是这些数据,以如下格式给出:
第一行是单词W,一个由{‘A’,‘B’,‘C’,…,‘Z’}中字母组成的字符串,保证1<=|W|<=10000(|W|代表字符串W的长度)
第二行是文章T,一个由{‘A’,‘B’,‘C’,…,‘Z’}中字母组成的字符串,保证|W|<=|T|<=1000000。
输出
对每组数据输出一行一个整数,即W在T中出现的次数。
样例输入
3
BAPC
BAPC
AZA
AZAZAZA
VERDI
AVERDXIVYERDIAN
样例输出
1
3
0
提示
我想到了一个绝妙的提示,可是这里地方太小写不下
S o l u t i o n : Solution: Solution:裸的哈希 也可以搞 K M P KMP KMP
#include<bits/stdc++.h>
using namespace std;
#define reg register
typedef unsigned long long ll;
const ll bas=1553915539;
int t,l1,l2,ans;
ll s,pw[1000100],sum[1000100];
char s1[10010],s2[1000100];
int main(){
scanf("%d",&t);
pw[0]=1;
for(reg int i=1;i<1000100;i++)pw[i]=pw[i-1]*bas;
while(t--){
scanf("%s%s",s1+1,s2+1);
l1=strlen(s1+1),l2=strlen(s2+1);
ans=s=sum[0]=0;
for(reg int i=1;i<=l2;i++)sum[i]=sum[i-1]*bas+ll(s2[i]-'A'+1);
for(reg int i=1;i<=l1;i++)s=s*bas+ll(s1[i]-'A'+1);
for(reg int i=1;i<=l2-l1+1;i++){
if(s==sum[i+l1-1]-sum[i-1]*pw[l1])ans++;
}
printf("%d\n",ans);
}
}
Power Strings
洛谷上搞到题了:题面
S o l u t i o n : Solution: Solution:对于每个字符串,可以作为循环节长度的只有它的因子,所以找最大的循环节只需要找出最小的循环节 k k k,输出 n / k n/k n/k就好了
对于每个字符串 我们枚举它的因子,用滚动哈希判断这个长度是否可以为循环节
#include<bits/stdc++.h>
using namespace std;
#define reg register
typedef unsigned long long ll;
const ll bas=1553915539;
int t,len,ans,f;
ll pw[1000100],sum[1000100];
char s[1000100];
int main(){
scanf("%d",&t);
pw[0]=1;
for(reg int i=1;i<1000000;i++)pw[i]=pw[i-1]*bas;
while(scanf("%s",s+1)){
if(s[1]=='.')return 0;
len=strlen(s+1),ans=sum[0]=0;
for(reg int i=1;i<=len;i++)sum[i]=sum[i-1]*bas+ll(s[i]-'a'+1);
for(reg int i=1;i<=len/2;i++){
if(len%i)continue;f=0;
for(reg int j=i;j<len;j+=i){
if(sum[i]!=sum[j+i]-sum[j]*pw[i]){
f=1;break;
}
}
if(!f){
printf("%d\n",len/i);break;}
if(i==len/2)puts("1");
}
}
}
Seek the Name,Seek the Fame
题目描述
给定一个字符串s,从小到大输出s中既是前缀又是后缀的子串的长度。
字符串长度不超过四十万
输入
输入包含许多测试数据。 每个测试数据为包含上述字符串S的单行。
限制:输入中只能出现小写字母。 1 <= S的长度<= 400000。
输出
对于每个数据,从小到大给出整数,每个整数代表既是前缀又是后缀的子串的长度
样例输入
ababcababababcabab
aaaaa
样例输出
ababcababababcabab
aaaaa
提示
无可奉告
S o l u t i o n : Solution: Solution:对于每个字符串 只需要从 1 − n 1-n 1−n判断前缀后缀哈希值是否相等就好了
#include<bits/stdc++.h>
using namespace std;
#define N 400040
#define reg register
typedef unsigned long long ll;
const ll bas=1553915539;
ll pw[N],sum[N];
int len;
char s[N];
int main(){
pw[0]=1;
for(reg int i=1;i<=400000;i++)pw[i]=pw[i-1]*bas;
while(scanf("%s",s+1)!=EOF){
len=strlen(s+1),sum[0]=0;
for(reg int i=1;i<=len;i++)sum[i]=sum[i-1]*bas+ll(s[i]-'a'+1);
for(reg int l=1;l<=len;l++){
if(sum[l]==sum[len]-sum[len-l]*pw[l])printf("%d ",l);
}
putchar(10);
}
}
friends
找来了 b z bz bz上的题面:题面
f r i e n d s ? f r i e n d i ? friends?friendi? friends?friendi?
S o l u t i o n : Solution: Solution:毒瘤!!!!
这题其实没多难 只需要每次枚举位置 i i i是不是多余的就行
但是真tm毒瘤瘤
如果删掉这数 a a a和删掉数 b b b后字符串是相等的,不算 N O T U N I Q U E . . . NOT \,\,\,\,UNIQUE... NOTUNIQUE...
比如:
7 7 7
A A A A A A A AAAAAAA AAAAAAA
输出的是 A A A AAA AAA不是 N O T U N I Q U E NOT\,\,\,\,UNIQUE NOTUNIQUE
上代码
#include<bits/stdc++.h>
using namespace std;
#define N 2000200
#define reg register
typedef unsigned long long ll;
const ll bas=1553915539;
ll x,y,hs,pw[N],sum[N];
int len,ans;
char s[N];
int main(){
pw[0]=1;
for(reg int i=1;i<=2000002;i++)pw[i]=pw[i-1]*bas;
scanf("%d%s",&len,s+1);
if(len%2==0)return printf("NOT POSSIBLE\n"),0;
len=strlen(s+1),sum[0]=0;
for(reg int i=1;i<=len;i++)sum[i]=sum[i-1]*bas+ll(s[i]-'A'+1);
for(reg int i=1;i<=len;i++){
if(i<=len/2){
x=sum[len/2+1]-sum[i]*pw[len/2+1-i]+sum[i-1]*pw[len/2+1-i];
y=sum[len]-sum[len/2+1]*pw[len/2];
if(x==y){
if(!hs||hs==y)ans=2,hs=y;
else return printf("NOT UNIQUE\n"),0;
}
}
else if(i>len/2+1){
x=sum[len/2];
y=sum[len]-sum[i]*pw[len-i]+(sum[i-1]-sum[len/2]*pw[i-1-len/2])*pw[len-i];
if(x==y){
if(!hs||hs==x)ans=1,hs=x;
else return printf("NOT UNIQUE\n"),0;
}
}
else{
if(sum[i-1]==sum[len]-sum[i]*pw[len-i]){
if(!hs||hs==sum[i-1])ans=1,hs=sum[i-1];
else return printf("NOT UNIQUE\n"),0;
}
}
}
if(ans==1)for(reg int i=1;i<=len/2;i++)putchar(s[i]);
else if(ans==2)for(reg int i=len/2+2;i<=len;i++)putchar(s[i]);
else printf("NOT POSSIBLE");
putchar(10);
}
A Horrible Poem
题面
S o l u t i o n : Solution: Solution:这个题吧和前面的 P o w e r S t r i n g s Power \,\,Strings PowerStrings差不多 就是时间要求高了点
那么我们怎么优化呢?
注意到如果 k k k是循环节 那么 2 k 3 k . . . 2k\,\,3k... 2k3k...都是循环节
对于每个长度 我们已经求出它的一个循环节 那么我们需要找它的因子是不是循环节
那怎么快速的找呢 那就要用到线性筛了
我们在筛的过程中顺便把这个数最小的质因子维护一下 找循环节时每次除去长度最小的这个质因子逐个判断
那么问题又来了 O ( n ) O(n) O(n)判断又炸了肿么办?
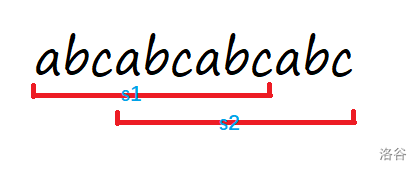
注意到当循环节时 3 3 3时 s 1 s_1 s1和 s 2 s_2 s2的 h a s h hash hash值时相等的
所以每次只需要判断 x x x到 y − l y-l y−l和 x + l x+l x+l到 y y y的 h a s h hash hash值就可以了
上代码
#include<bits/stdc++.h>
using namespace std;
#define maxn 500000
#define N 500050
#define reg register
typedef unsigned long long ll;
inline void read(int &x){
int s=0,w=1;char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-')w=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){
s=(s<<3)+(s<<1)+(ch&15);ch=getchar();}
x=s*w;
}
const ll bas=1553915539;
int q,x,y,ans,cnt,len,now,g[N],prime[N];
bool vis[N];
char s[N];
ll pw[N],sum[N];
void work(){
for(reg int i=2;i<=maxn;i++){
if(!vis[i])prime[++cnt]=g[i]=i;
for(reg int j=1;i*prime[j]<=N;j++){
vis[i*prime[j]]=true,g[i*prime[j]]=prime[j];
if(i%prime[j]==0)break;
}
}
}
inline bool check(int l, int x, int y){
if(l==y-x+1)return true;
int L=y-x+1;
if(sum[y-l]-sum[x-1]*pw[L-l]==sum[y]-sum[x+l-1]*pw[L-l])return true;
return false;
}
int main(){
read(len);work();
scanf("%s",s+1);
read(q);
pw[0]=1;
for(reg int i=1;i<=len;i++)pw[i]=pw[i-1]*bas,sum[i]=sum[i-1]*bas+ll(s[i]-'a'+1);
while(q--){
read(x),read(y);
ans=now=y-x+1;
while(now!=1){
if(check(ans/g[now],x,y))ans/=g[now];
now/=g[now];
}
printf("%d\n",ans);
}
}
Beads
题面
S o l u t i o n : Solution: Solution:首先要知道 从 1 1 1到 n n n 每次枚举长度为 k k k的子串的时间复杂度是 O ( n l o g n ) O(nlog_n) O(nlogn)
因为子串个数是 ⌊ n k ⌋ \lfloor\frac{n}{k}\rfloor ⌊kn⌋ 枚举总次数就是 ∑ k = 1 n ⌊ n k ⌋ \sum_{k=1}^{n}\lfloor\frac{n}{k}\rfloor ∑k=1n⌊kn⌋
∑ n = 1 ∞ 1 n \sum_{n=1}^{∞}\frac{1}{n} ∑n=1∞n1叫什么调和级数 约为 l n n ln_n lnn
所以总复杂度为 O ( n l o g n ) O(nlog_n) O(nlogn)
那么显然我们需要用 O ( 1 ) O(1) O(1)的时间判重
这时候用个 s e t set set岂不美哉?
用到这俩函数:
s e t . c o u n t ( a ) set.count(a) set.count(a)出现过 a a a返回 t r u e true true反之返回 f a l s e false false
s e t . i n s e r t ( a ) set.insert(a) set.insert(a)向 s e t set set中加入元素 a a a
注意个细节就是子串可以正反两个方向 所以我们算一次正哈希算一次倒着的哈希然后给他们乘起来用作这个字符串的 h a s h hash hash值
代码:
#include<bits/stdc++.h>
using namespace std;
#define N 200020
#define reg register
typedef unsigned long long ll;
const ll bas=1553915539;
inline void read(int &x){
int s=0,w=1;char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-')w=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){
s=(s<<3)+(s<<1)+(ch&15);ch=getchar();}
x=s*w;
}
int n,cnt,num,tot,s[N],ans[N];
ll pw[N],s1[N],s2[N];
set<ll> st;
int main(){
read(n);pw[0]=1;
for(reg int i=1;i<=n;i++)read(s[i]),pw[i]=pw[i-1]*bas,s1[i]=s1[i-1]*bas+ll(s[i]);
for(reg int i=n;i;i--)s2[i]=s2[i+1]*bas+ll(s[i]);
for(reg int k=1;k<=n;k++){
st.clear();cnt=0;
for(reg int i=k;i<=n;i+=k){
ll n1=s1[i]-s1[i-k]*pw[k],n2=s2[i-k+1]-s2[i+1]*pw[k];
ll now=n1*n2;
if(st.count(now))continue;
st.insert(now);
cnt++;
}
if(cnt>tot)tot=cnt,num=1,ans[1]=k;
else if(cnt==tot)ans[++num]=k;
}
printf("%d %d\n",tot,num);
for(reg int i=1;i<=num;i++)printf("%d ",ans[i]);
putchar(10);
}
Antisymmetry
题面
S o l u t i o n : Solution: Solution:首先显然只有偶数长度的字符串才可以满足反对称
我们只需要对每个位置做二分,求出这个位置向两边扩展能得到最大的反对称字符串,这个字符串对答案的贡献为 l e n 2 \frac{len}{2} 2len
调二分调了十分钟… …注意答案不开 l o n g l o n g long\,\,long longlong见祖宗
#include<bits/stdc++.h>
using namespace std;
#define N 500050
#define reg register
typedef unsigned long long ll;
const ll bas=1553915539;
int n,l,r,mid,mx;
ll pw[N],s1[N],s2[N],ans;
char s[N];
inline bool check(int l, int r){
if(r-l==1&&s[l]!=s[r])return true;
if(s1[r]-s1[l-1]*pw[r-l+1]==s2[l]-s2[r+1]*pw[r-l+1])return true;
return false;
}
int main(){
scanf("%d%s",&n,s+1);pw[0]=1;
for(reg int i=1;i<=n;i++)pw[i]=pw[i-1]*bas,s1[i]=s1[i-1]*bas+ll(s[i]-'0');
for(reg int i=n;i;i--)s2[i]=s2[i+1]*bas+ll((s[i]-'0'+1)%2);
for(reg int i=2;i<=n;i++){
if(s[i]-'0'+s[i-1]-'0'==1){
l=0,r=min(i-2,n-i),mx=0;
while(l<=r){
mid=l+r>>1;
if(check(i-1-mid,i+mid))mx=max(mx,mid),l=mid+1;
else r=mid-1;
}
ans+=ll(mx+1);
}
}
printf("%llu\n",ans);
}