实际应用中,可能会涉及处理 pdf 文件,PyPDF2 就是这样一个库,使用它可以轻松的处理 pdf 文件,它提供了读,割,合并,文件转换等多种操作。
文档地址:http://pythonhosted.org/PyPDF2/
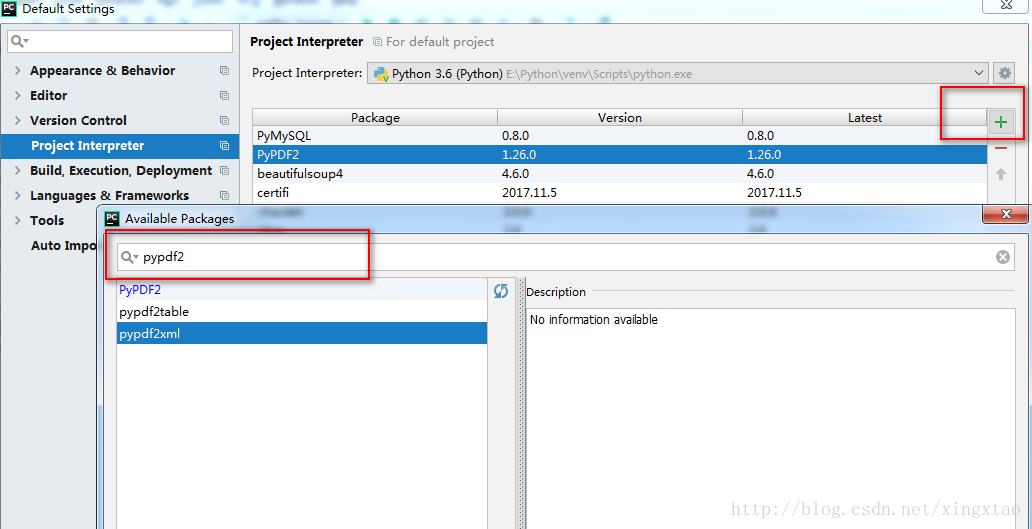
PyPDF2 安装
PyCharm 安装:File -> Default Settings -> Project Interpreter
PdfFileReader
构造方法:
PyPDF2.PdfFileReader(stream,strict = True,warndest = None,overwriteWarnings = True)初始化一个 PdfFileReader 对象,此操作可能需要一些时间,因为 PDF 流的交叉引用表被读入内存。
参数:
- stream:*File 对象或支持与 File 对象类似的标准读取和查找方法的对象,也可以是表示 PDF 文件路径的字符串。*
- strict(bool): 确定是否应该警告用户所用的问题,也导致一些可纠正的问题是致命的,默认是 True
- warndest : 记录警告的目标(默认是 sys.stderr)
- overwriteWarnings(bool):确定是否 warnings.py 用自定义实现覆盖 Python 模块(默认为 True)
PdfFileReader 对象的属性和方法
| 属性和方法 | 描述 |
|---|---|
| getDestinationPageNumber(destination) | 检索给定目标对象的页码 |
| getDocumentInfo() | 检索 PDF 文件的文档信息字典 |
| getFields(tree = None,retval = None,fileObj= None) | 如果此 PDF 包含交互式表单字段,则提取字段数据, |
| getFormTextFields() | 从文档中检索带有文本数据(输入,下拉列表)的表单域 |
| getNameDestinations(tree = None,retval= None) | 检索文档中的指定目标 |
| getNumPages() | 计算此 PDF 文件中的页数 |
| getOutlines(node = None,outline = None,) | 检索文档中出现的文档大纲 |
| getPage(pageNumber) | 从这个 PDF 文件中检索指定编号的页面 |
| getPageLayout() | 获取页面布局 |
| getPageMode() | 获取页面模式 |
| getPageNumber(pageObject) | 检索给定 pageObject 处于的页码 |
| getXmpMetadata() | 从 PDF 文档根目录中检索 XMP 数据 |
| isEncrypted | 显示 PDF 文件是否加密的只读布尔属性 |
| namedDestinations | 访问该getNamedDestinations()函数的只读属性 |
PDF 读取操作:
# encoding:utf-8
from PyPDF2 import PdfFileReader, PdfFileWriter
readFile = 'C:/Users/Administrator/Desktop/RxJava 完全解析.pdf'
# 获取 PdfFileReader 对象
pdfFileReader = PdfFileReader(readFile) # 或者这个方式:pdfFileReader = PdfFileReader(open(readFile, 'rb'))
# 获取 PDF 文件的文档信息
documentInfo = pdfFileReader.getDocumentInfo()
print('documentInfo = %s' % documentInfo)
# 获取页面布局
pageLayout = pdfFileReader.getPageLayout()
print('pageLayout = %s ' % pageLayout)
# 获取页模式
pageMode = pdfFileReader.getPageMode()
print('pageMode = %s' % pageMode)
xmpMetadata = pdfFileReader.getXmpMetadata()
print('xmpMetadata = %s ' % xmpMetadata)
# 获取 pdf 文件页数
pageCount = pdfFileReader.getNumPages()
print('pageCount = %s' % pageCount)
for index in range(0, pageCount):
# 返回指定页编号的 pageObject
pageObj = pdfFileReader.getPage(index)
print('index = %d , pageObj = %s' % (index, type(pageObj))) # <class 'PyPDF2.pdf.PageObject'>
# 获取 pageObject 在 PDF 文档中处于的页码
pageNumber = pdfFileReader.getPageNumber(pageObj)
print('pageNumber = %s ' % pageNumber)
输出结果:
documentInfo = {'/Title': IndirectObject(157, 0), '/Producer': IndirectObject(158, 0), '/Creator': IndirectObject(159, 0), '/CreationDate': IndirectObject(160, 0), '/ModDate': IndirectObject(160, 0), '/Keywords': IndirectObject(161, 0), '/AAPL:Keywords': IndirectObject(162, 0)}
pageLayout = None
pageMode = None
xmpMetadata = None
pageCount = 3
index = 0 , pageObj = <class 'PyPDF2.pdf.PageObject'>
pageNumber = 0
index = 1 , pageObj = <class 'PyPDF2.pdf.PageObject'>
pageNumber = 1
index = 2 , pageObj = <class 'PyPDF2.pdf.PageObject'>
pageNumber = 2 PdfFileWriter
这个类支持 PDF 文件,给出其他类生成的页面。
| 属性和方法 | 描述 |
|---|---|
| addAttachment(fname,fdata) | 在 PDF 中嵌入文件 |
| addBlankPage(width= None,height=None) | 追加一个空白页面到这个 PDF 文件并返回它 |
| addBookmark(title,pagenum,parent=None, color=None,bold=False,italic=False,fit=’/fit,*args’) |
|
| addJS(javascript) | 添加将在打开此 PDF 是启动的 javascript |
| addLink(pagenum,pagedest,rect,border=None,fit=’/fit’,*args) | 从一个矩形区域添加一个内部链接到指定的页面 |
| addPage(page) | 添加一个页面到这个PDF 文件,该页面通常从 PdfFileReader 实例获取 |
| getNumpages() | 页数 |
| getPage(pageNumber) | 从这个 PDF 文件中检索一个编号的页面 |
| insertBlankPage(width=None,height=None,index=0) | 插入一个空白页面到这个 PDF 文件并返回它,如果没有指定页面大小,就使用最后一页的大小 |
| insertPage(page,index=0) | 在这个 PDF 文件中插入一个页面,该页面通常从 PdfFileReader 实例获取 |
| removeLinks() | 从次数出中删除连接盒注释 |
| removeText(ignoreByteStringObject = False) | 从这个输出中删除图像 |
| write(stream) | 将添加到此对象的页面集合写入 PDF 文件 |
PDF 写入操作:
def addBlankpage():
readFile = 'C:/Users/Administrator/Desktop/RxJava 完全解析.pdf'
outFile = 'C:/Users/Administrator/Desktop/copy.pdf'
pdfFileWriter = PdfFileWriter()
# 获取 PdfFileReader 对象
pdfFileReader = PdfFileReader(readFile) # 或者这个方式:pdfFileReader = PdfFileReader(open(readFile, 'rb'))
numPages = pdfFileReader.getNumPages()
for index in range(0, numPages):
pageObj = pdfFileReader.getPage(index)
pdfFileWriter.addPage(pageObj) # 根据每页返回的 PageObject,写入到文件
pdfFileWriter.write(open(outFile, 'wb'))
pdfFileWriter.addBlankPage() # 在文件的最后一页写入一个空白页,保存至文件中
pdfFileWriter.write(open(outFile,'wb'))结果是:在写入的 copy.pdf 文档的最后最后一页写入了一个空白页。
分割文档(取第五页之后的页面)
def splitPdf():
readFile = 'C:/Users/Administrator/Desktop/RxJava 完全解析.pdf'
outFile = 'C:/Users/Administrator/Desktop/copy.pdf'
pdfFileWriter = PdfFileWriter()
# 获取 PdfFileReader 对象
pdfFileReader = PdfFileReader(readFile) # 或者这个方式:pdfFileReader = PdfFileReader(open(readFile, 'rb'))
# 文档总页数
numPages = pdfFileReader.getNumPages()
if numPages > 5:
# 从第五页之后的页面,输出到一个新的文件中,即分割文档
for index in range(5, numPages):
pageObj = pdfFileReader.getPage(index)
pdfFileWriter.addPage(pageObj)
# 添加完每页,再一起保存至文件中
pdfFileWriter.write(open(outFile, 'wb'))合并文档
def mergePdf(inFileList, outFile):
'''
合并文档
:param inFileList: 要合并的文档的 list
:param outFile: 合并后的输出文件
:return:
'''
pdfFileWriter = PdfFileWriter()
for inFile in inFileList:
# 依次循环打开要合并文件
pdfReader = PdfFileReader(open(inFile, 'rb'))
numPages = pdfReader.getNumPages()
for index in range(0, numPages):
pageObj = pdfReader.getPage(index)
pdfFileWriter.addPage(pageObj)
# 最后,统一写入到输出文件中
pdfFileWriter.write(open(outFile, 'wb'))
PageObject
PageObject(pdf=None,indirectRef=None)此类表示 PDF 文件中的单个页面,通常这个对象是通过访问 PdfFileReader 对象的 getPage() 方法来得到的,也可以使用 createBlankPage() 静态方法创建一个空的页面。
参数:
- pdf : 页面所属的 PDF 文件。
- indirectRef:将源对象的原始间接引用存储在其源 PDF 中。
PageObject 对象的属性和方法
| 属性或方法 | 描述 |
|---|---|
| static createBlankPage(pdf=None,width=None,height=None) | 返回一个新的空白页面 |
| extractText() | 找到所有文本绘图命令,按照他们在内容流中提供的顺序,并提取文本 |
| getContents() | 访问页面内容,返回 Contents 对象或 None |
| rotateClockwise(angle) | 顺时针旋转 90 度 |
| scale(sx,sy) | 通过向其内容应用转换矩阵并更新页面大小 |
粗略读取 PDF 文本内容
def getPdfContent(filename):
pdf = PdfFileReader(open(filename, "rb"))
content = ""
for i in range(0, pdf.getNumPages()):
pageObj = pdf.getPage(i)
extractedText = pageObj.extractText()
content += extractedText + "\n"
# return content.encode("ascii", "ignore")
return content