题目 / 应用场景:
前阵子在12333平台打印社保证明,无法一次性打印出完整页数的PDF,于是分成5个PDF下载,再将它们合并起来。起初使用微信小程序中的PDF合并功能,但是会出现PDF文件被压缩、不清晰的现象。学Python正好学到结构化文本文件PDF的处理,本文讲述用第三方库PyPDF2来处理合并多个PDF文件的问题。
IDE:
Thonny
代码:
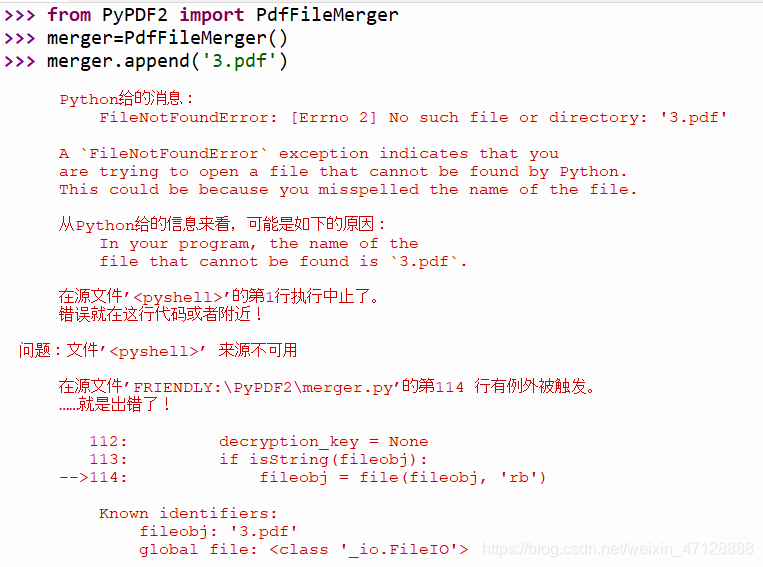
from PyPDF2 import PdfFileMerger
merger=PdfFileMerger()
input1=open('C:/Users/Jocelyn/Desktop/社保证明/3.pdf','rb')
input2=open('C:/Users/Jocelyn/Desktop/社保证明/4.pdf','rb')
input3=open('C:/Users/Jocelyn/Desktop/社保证明/5.pdf','rb')
input4=open('C:/Users/Jocelyn/Desktop/社保证明/6.pdf','rb')
input5=open('C:/Users/Jocelyn/Desktop/社保证明/7.pdf','rb')
merger.append(fileobj=input1)
merger.append(fileobj=input2)
merger.append(fileobj=input3)
merger.append(fileobj=input4)
merger.append(fileobj=input5)
merger.write('merge.pdf')
遇到的问题:
-
引用模块后调用函数的格式:<模块>.<名称>

模块引用的方式有两种:
① import <模块> [as <别名> ]
用此方法,后续调用模块中函数,需要加上模块的命名空间。如import PyPDF2后接merger=PyPDF2.PdfFileMerger()
② from <模块> import <函数>
用此方法,直接引入模块中的某个函数,调用该函数的时候不需要再加上命名空间。如from PyPDF2 import PdfFileMerger
懒得麻烦,直接用方法二。 -
要先读取文件后合并,并且读取文件要加上该文件的路径。
在Windows文件属性中查看的路径是“ \ ”,Python将“ / ”识别为转义字符,解决方法有三种:①用正斜杠“ / ”;②用双反斜杠(进行斜杠转义)③在路径前加r,让路径变为原始字符串如r'c:\Users\...',详情可见https://blog.csdn.net/weixin_42899627/article/details/108032987?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2allfirst_rank_v2~rank_v25-2-108032987.nonecase&utm_term=python%E8%B7%AF%E5%BE%84%E7%9A%84%E6%96%9C%E6%9D%A0%E4%B8%BA%E4%BB%80%E4%B9%88%E6%98%AF%E5%8F%8D%E7%9A%84
思考(待解决):
如何将合并的PDF文档生成到指定位置
(目前会生成到Thonny的默认位置)