AV1基于机器学习的变换块快速划分
在上一篇文章《AV1基于机器学习的快速变换模式选择》中讲解了AV1如何使用机器学习技术为每个变换块选择合适的变换模式,本节将讲解AV1如何利用机器学习技术对变换块进行划分。
AV1无需像VP9中那样强制固定变换单元大小,而是允许编码块进行递归划分。并且支持从4×4到64×64的正方形,2:1/1:2和4:1/1:4比例也都可以。

如上图所示,一个编码块可以按多种方式划分为更小的TU(变换单元),每个小的TU还可以进一步划分。为了寻找最好的划分模式,编码器不得不为每个TU计算其划分和不话费的RD cost,从中选择RD cost最小的模式。
为了使用ML加速上述过程,可以将上面的问题转化为一个二元分类问题。目标就是构建一个ML模型,预测每个编码块是否进行TU划分。
ML模型的输入是残差块像素计算得到的一些特征。这些特征包括两个层级的均值和标准差。第一级是整个残差块的均值和标准差。第二级是每个1/4子块(对于正方形块和1:4矩形块)或每个1/2子块(对于1:2矩形块)的均值和标准差。同时还有计算第二级标准差的均值和均值的标准差。所以对于正方形块和1:4矩形块有12个特征,对于1:2矩形块有8个特征。(注:AV1代码中1:4矩形块其实使用了8个特征)为了预测更准确,对不同尺寸的块分别构建模型。所有模型的结构都如下图所示:

模型通过全连接神经网络实现,隐藏层使用ReLU作为激活函数。
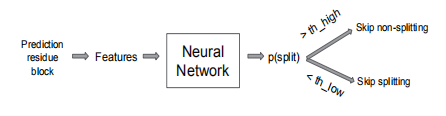
模型使用方式如上图所示,对每个预测残差块提取特征,将特征输入模型获取输出。根据模型输出结果选择划分模型,如果模型认为很大概率不划分结果最优则不划分,如果模型认为很大概率划分结果最优则划分。其中预定义的阈值控制最终选择(AV1阈值默认为4000)。
具体模型结构
下面介绍两种具体的模型结构定义:
1、4x8块的模型
由前面知4x8模型输入8个特征,即输入单元数为8。它只有1个隐藏层,隐藏层单元数为16。模型参数如下:
//输入层到隐藏层间的权重weight
static const float av1_tx_split_nn_weights_4x8_layer0[8 * 16] = {
0.068650f, -0.732073f, -0.040361f, 0.322550f, -0.021123f, 0.212518f,
-0.350546f, 0.435987f, -0.111756f, -0.401568f, 0.069548f, -0.313000f,
0.073918f, -0.373805f, -0.775810f, -0.124753f, 0.181094f, -0.602641f,
-0.026219f, -0.350112f, 0.020599f, -0.311752f, -0.476482f, -0.669465f,
-0.310921f, 0.348869f, -0.115984f, 0.154250f, 0.200485f, -0.016689f,
0.020392f, 0.413810f, 0.634064f, -0.627530f, 0.399178f, -0.012284f,
0.472030f, 0.091087f, -0.706100f, -0.447944f, -0.274226f, 0.445656f,
0.309339f, 0.505522f, 0.038496f, -0.152809f, 0.408684f, -0.068151f,
0.271612f, 0.353233f, -0.150365f, 0.075212f, -0.035096f, 0.346615f,
0.124382f, 0.477072f, 0.216288f, 0.070548f, -0.106362f, 0.681613f,
-0.145502f, -0.218631f, -0.099248f, -0.001983f, -0.196819f, -0.969045f,
0.063009f, -0.123053f, 0.104875f, -0.137581f, -0.282933f, -0.003624f,
-0.315659f, -0.333523f, -0.503000f, -0.100063f, -0.536711f, -0.059978f,
-0.670248f, -0.353762f, 0.181109f, 0.289715f, -0.071206f, 0.261141f,
0.052796f, -0.114554f, -0.139214f, -0.261380f, 0.075984f, -0.647925f,
-0.099528f, -0.677814f, 0.015712f, -0.389385f, -0.095622f, -0.165117f,
-0.109454f, -0.175240f, -0.393914f, 0.212330f, 0.037822f, 0.248280f,
0.180197f, 0.110493f, -0.525727f, -0.092329f, -0.524029f, -0.407364f,
-0.542373f, -0.435626f, -0.912194f, 0.062794f, 0.160433f, 0.741485f,
-0.103659f, -0.119327f, -0.055275f, 0.334358f, 0.014713f, 0.046327f,
0.831114f, -0.576682f, 0.354369f, -0.082088f, 0.452331f, 0.039730f,
-0.792429f, -0.385862f,
};
//输入层到隐藏层间的偏置值bias
static const float av1_tx_split_nn_bias_4x8_layer0[16] = {
0.238621f, 2.186830f, 1.383035f, -0.867139f, 1.257119f, -0.351571f,
-0.240650f, -0.971692f, 2.744843f, 1.116991f, 0.139062f, -0.165332f,
0.262171f, -1.598153f, -1.427340f, -1.602306f,
};
//隐藏层到输出层的权重
static const float av1_tx_split_nn_weights_4x8_layer1[16] = {
-0.367134f, 1.373058f, -0.897039f, -0.326819f, -0.734030f, -0.290413f,
-0.501249f, 0.505321f, -0.537692f, -0.767893f, 0.268697f, 0.278987f,
0.085082f, 0.614986f, 0.847904f, 0.637578f,
};
//隐藏层到输出层的偏置
static const float av1_tx_split_nn_bias_4x8_layer1[1] = {
0.20586078f,
};2、8x8块的模型
由前面知4x8模型输入12个特征,即输入单元数为12。它只有1个隐藏层,隐藏层单元数为12。模型参数如下:
//输入层到隐藏层间的权重weight
static const float av1_tx_split_nn_weights_8x8_layer0[144] = {
0.177983f, -0.938386f, -0.074460f, -0.221843f, -0.073182f, -0.295155f,
-0.098202f, -0.279510f, 0.001054f, -0.119319f, -1.835282f, -0.581507f,
-1.222222f, -1.049006f, -0.807508f, -0.454252f, -0.774879f, -0.180607f,
-0.886976f, -0.231971f, -0.824677f, -0.351872f, -1.323819f, 0.235378f,
0.015331f, -0.341818f, 0.145549f, -0.348362f, 0.147647f, -0.323400f,
0.047558f, -0.553025f, -0.295485f, -0.330368f, -0.530605f, -0.407516f,
0.447740f, 0.782381f, -0.179164f, -0.584675f, -0.052645f, 0.038656f,
-0.096783f, 0.038342f, -0.170762f, -0.405844f, -0.552665f, -0.509866f,
0.757204f, -1.296465f, 0.631015f, 0.009265f, 0.646192f, 0.044523f,
0.653161f, 0.033820f, 0.849639f, -0.068555f, -1.036085f, -0.511652f,
0.104693f, -1.458690f, 0.286051f, -0.089800f, 0.381564f, -0.302640f,
0.304465f, -0.268706f, 0.432603f, -0.117914f, -2.070031f, -0.565696f,
-0.073027f, -1.783570f, -0.318144f, -0.320990f, -0.343966f, -0.140996f,
-0.322977f, -0.232147f, -0.373210f, -0.158266f, -1.922305f, -0.634373f,
0.101894f, -0.221847f, 0.018412f, -0.423887f, -0.266684f, -0.444930f,
-0.196237f, 0.106638f, -0.065834f, -0.538401f, -0.280772f, -0.620348f,
1.089957f, -0.799928f, 0.504112f, -0.165763f, 0.578741f, -0.172653f,
0.547316f, -0.143484f, 0.717220f, -0.297190f, -1.237854f, -0.074819f,
-0.977304f, -0.484092f, -0.646427f, -0.451443f, -0.612126f, -0.224475f,
-0.731608f, -0.257077f, -0.665857f, -0.346742f, -1.216372f, 0.227267f,
0.231249f, -1.693073f, -0.035899f, 0.380845f, -0.058476f, 0.409405f,
-0.066679f, 0.406731f, -0.068501f, 0.396748f, 0.639462f, 0.150834f,
-0.418659f, -1.421931f, 0.101889f, 0.083573f, 0.129746f, 0.134460f,
0.081185f, 0.127420f, 0.083664f, 0.051096f, 1.361688f, 0.386093f,
};
//输入层到隐藏层间的偏置值bias
static const float av1_tx_split_nn_bias_8x8_layer0[12] = {
4.280443f, 2.218902f, -0.256953f, 3.161431f, 2.082548f, 2.506052f,
2.563224f, 1.421976f, -1.627813f, -1.436085f, 2.297265f, 1.500469f,
};
//隐藏层到输出层的权重
static const float av1_tx_split_nn_weights_8x8_layer1[12] = {
1.178833f, -0.428527f, -0.078737f, 0.381434f, -0.466895f, -0.901745f,
-0.766968f, -0.356663f, 0.450146f, 0.509370f, -0.356604f, -0.443506f,
};
//隐藏层到输出层的偏置
static const float av1_tx_split_nn_bias_8x8_layer1[1] = {
-0.156294f,
};训练集构建
在AV1中这些模型已经训练好了,训练模型的数据集也很好构建。选择不同类型、不同分辨率的序列,使用不同QP编码,在编码过程中计算输入特征(两级均值和标准差)及对应标签(RD cost)。
感兴趣的请关注微信公众号Video Coding
