实例一
通过网址:10.1.1.11:81 进入web渗透测试实验打开

在后面加'%20and%20’1'%20=%20'1(%20是空格的编码)


可以看出左右两边不一样,说明存在注入,接下来开始猜测字段数目
在root后加‘%20order%20by%205%23(先猜测有5个字段,%23 是 # 的16位url编码,用来把后面的东西注释掉)
' order by 5%23
出现如下图,当把5改成6时出现空,说明有5个字段。
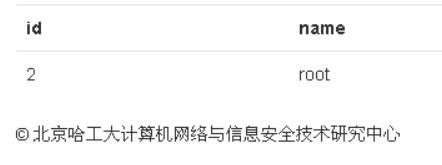
开始猜字段内容:
在root后加‘%20union%20select%201,name,passwd,4,5%20from%20users%23
' union select 1,name,passwd,4,5 from users%23

实例二
和实例一一样,只不过在说明书中有个这样的提示,少用空格,,使用正则,采用了绕过的方式,
在GET请求时,将URL的SQL注入关键字用%0a分隔,%0a是换行符,在mysql中可以正常执行。

把所有实例一添加的东西,中%20代表的空格,改成%0a即可。

实验三;

过滤了加号 空白字符,用内敛注释/**/掉空格,其他和实验一一样,

步骤一:判断是否有注入点
方法一:
在url后面加’ 从而让SQL语句出错,那么页面就会提示出错信息。这时候就可以判断从这里存在注入。当然还有可能加了’,和没加是一样的,这也有可能是注入。因为当把错误提示关闭时,它是不会在页面显示的。
方法二:
构造 and 1 = 1 和 and 1 = 2
如果两个页面显示不一样,那么就说明存在注入了。
步骤二:理解字段数目
方法:
order by 数字K /**意思是根据第K个字段的大小来排序, 比如如果只有3个字段, K = 4, 那么就会报错。所以通过这个可以知道有多少字段*/
步骤三: 使用联合查询获取信息
方法:
使用union语句
注意:
union 两边的select 语句必须具有相同数量的列,列也必须拥有相似的数据类型,同时,每条select语句中列的顺序必须相同。
MySQL学习小知识
#打开MySQL服务
sudo service mysql start
#使用root用户登录,密码为空
mysql -u root
#创建数据库
create database 数据库名字;
#显示数据库
show databases;
#确定当前为哪个数据库
use 数据库名字;(显示Database changed即为连接成功)
#查看当前数据库中有几张表
show tables;
#创建一个表
create table 表名;(
#详细创建方式
create table employee(id int(10),name char(20),phone int(10));
)
#查看表中内容
select *from 表名
#通过select 语句向表中插入数据
insert into 表名(id,name,phone) values(01,'tom',110110);
#删除数据库
drop database 数据库名
#把数据文件下载到本地
git clone 文件链接 /本地地址.git
#加载文件中的数据
source 文件所存路径
#查看一张表中的所有内容
select *from table_name;
#select语句的基本格式
select 要查询的列名 from 表名 where 限制条件;
[select 语句常常会有 where 限制条件,用于达到更加精确的查询。
where限制条件可以有数学符号 (=,<,>,>=,<=)
(1)限制条件 age>25 and age<30 ,如果需要包含25和30这两个数字的话,
可以替换为 age between 25 AND 30
select name,age from employee where age>25 AND age<30;
(2)关键词 IN 和 NOT IN 的作用和它们的名字一样明显,
用于筛选“在”或“不在”某个范围内的结果
select name,age,phone,in_dpt from employee where in_dpt IN ('dpt3','dpt4');
(3)关键字 LIKE 可用于实现模糊查询,常见于搜索功能中。
和 LIKE 联用的通常还有通配符,代表未知字符。SQL中的通配符是 _ 和 % 。
其中 _ 代表一个未指定字符,% 代表不定个未指定字符
比如,要只记得电话号码前四位数为1101,而后两位忘记了,则可以用两个 _ 通配符代替
select name,age,phone from employee where phone like '1101__';
另一种情况,比如只记名字的首字母,又不知道名字长度,则用 % 通配符代替不定个字符
select name,age,phone from employee where name like'J%';
(4)为了使查询结果看起来更顺眼,我们可能需要对结果按某一列来排序,
这就要用到 order by 排序关键词。默认情况下,order by的结果是升序排列,
而使用关键词 asc 和 desc 可指定升序或降序排序。
比如,我们按 salary 降序排列
select name,age,salary,phone from employee order by salary desc;]
(5)内置函数
1.count:计数(任何数据类型)
2.sum:求和3.AVG:求平均值(数字类型数据)
4.max:最大值5.min:最小值(数值,字符串,日期数据类型)
例:
计算出 salary 的最大、最小值,
SELECT MAX(salary) AS max_salary,MIN(salary) FROM employee;
使用 AS 关键词可以给值重命名,比如最大值被命名为了 max_salary
(6)子查询
有时必须处理多个表才能获得所需的信息。例如:想要知道名为 "Tom" 的员工所在部门做了几个工程。员工信息储存在 employee 表中,
但工程信息储存在 project 表中
SELECT of_dpt,COUNT(proj_name) AS count_project FROM project GROUP BY of_dpt
HAVING of_dpt IN
(SELECT in_dpt FROM employee WHERE name='Tom');
上面代码包含两个 SELECT 语句,第二个 SELECT 语句将返回一个集合的数据形式,然后被第一个 SELECT 语句用 in 进行判断。
HAVING 关键字可以的作用和 WHERE 是一样的,都是说明接下来要进行条件筛选操作。
区别在于 HAVING 用于对分组后的数据进行筛选
(7)连接查询
在处理多个表时,子查询只有在结果来自一个表时才有用。但如果需要显示两个表或多个表中的数据,这时就必须使用连接 (join) 操作。
连接的基本思想是把两个或多个表当作一个新的表来操作
SELECT id,name,people_num
FROM employee,department
WHERE employee.in_dpt = department.dpt_name
ORDER BY id;
这条语句查询出的是,各员工所在部门的人数,
其中员工的 id 和 name 来自 employee 表,people_num 来自 department 表:
另一个连接语句格式是使用 JOIN ON 语法,刚才的语句等同于:
SELECT id,name,people_num
FROM employee JOIN department
ON employee.in_dpt = department.dpt_name
ORDER BY id;
primary
不太懂的地方:
主键约束用于约束表中一行,作为这一行的标识符,在一张表中通过主键就可以准确定位到一行,行中的主键不能有重复且不能为空!!!
eg:create table example1
( id int(10) primary key
name char(20),
constraint dpt_pk primary key(dpt_name)
);
表示的就是主键约束,constraint dpt_pk primary key(dpt_name)这句代码是定义主键,dpt_pk是自定义的主键名。
还有复合主键定义eg: constrint proj_pk primary key(proj_num,proj_name)