声明:
本博客是本人在学习《Java 编程的逻辑》后整理的笔记,旨在方便复习和回顾,并非用作商业用途。
本博客已标明出处,如有侵权请告知,马上删除。
7.2 剖析 String
字符串操作是计算机程序中最常见的操作之一。Java 中处理字符串的主要类是 String 和 StringBuilder,本节介绍 String。先介绍基本用法,然后介绍实现原理,随后介绍编码转换,分析 String 的不可变性、常量字符串、hashCode 和正则表达式。
7.2.1 基本用法
可以通过常量定义 String 变量:
String name = "老马说编程";
也可以通过 new 创建 String 变量:
String name = new String("老马说编程");
String 可以直接使用 + 和 += 运算符,如:
String name = "老马";
name+= "说编程";
String descritpion = ",探索编程本质";
System.out.println(name+descritpion);
输出为:老马说编程,探索编程本质
String 类包括很多方法,以方便操作字符串,比如:
public boolean isEmpty() // 判断字符串是否为空
public int length() // 获取字符串长度
public String substring(int beginIndex) // 取子字符串
public String substring(int beginIndex, int endIndex) // 取子字符串
public int indexOf(int ch) // 在字符串中查找字符,返回第一个找到的索引位置,没找到返回-1
public int indexOf(String str) // 在字符串中查找子字符串,返回第一个找到的索引位置,没找到返回-1
public int lastIndexOf(int ch) // 从后面查找字符,返回从后面数的第一个索引位置,没找到返回-1
public int lastIndexOf(String str) // 从后面查找子字符串,返回从后面数的第一个索引位置,没找到返回-1
public boolean contains(CharSequence s) // 判断字符串中是否包含指定的字符序列
public boolean startsWith(String prefix) // 判断字符串是否以给定子字符串开头
public boolean endsWith(String suffix) // 判断字符串是否以给定子字符串结尾
public boolean equals(Object anObject) // 与其他字符串比较,看内容是否相同
public boolean equalsIgnoreCase(String anotherString) // 忽略大小写,与其他字符串进行比较,看内容是否相同
public int compareTo(String anotherString) // 比较字符串大小
public int compareToIgnoreCase(String str) // 忽略大小写比较
public String toUpperCase() // 所有字符转换为大写字符,返回新字符串,原字符串不变
public String toLowerCase() // 所有字符转换为小写字符,返回新字符串,原字符串不变
public String concat(String str) // 字符串连接,返回当前字符串和参数字符串合并后的字符串,原字符串不变
public String replace(char oldChar, char newChar) // 字符串替换,替换单个字符,返回新字符串,原字符串不变
public String replace(CharSequence target, CharSequence replacement) // 字符串替换,替换字符序列,返回新字符串,原字符串不变
public String trim() // 删掉开头和结尾的空格,返回新字符串,原字符串不变
public String[] split(String regex) // 分隔字符串,返回分隔后的子字符串数组,原字符串不变
看个 String 的简单例子,按逗号分隔 “hello,world”:
String str = "hello,world";
String[] arr = str.split(",");
arr[0] 为 “hello”, arr[1] 为 “world”。
从调用者的角度理解了 String 的基本用法,下面我们进一步来理解 String 的内部。
7.2.2 走进 String 内部
7.2.2.1 封装字符数组
String 类内部用一个字符数组表示字符串,实例变量定义为:
private final char value[];
String 有两个构造方法,可以根据 char 数组创建 String
public String(char value[])
public String(char value[], int offset, int count)
需要说明的是,String 会根据参数新创建一个数组,并拷贝内容,而不会直接用参数中的字符数组。
String 中的大部分方法,内部也都是操作的这个字符数组。比如说:
- length() 方法返回的就是这个数组的长度
- substring() 方法就是根据参数,调用构造方法 String(char value[], int offset, int count) 新建了一个字符串
- indexOf 查找字符或子字符串时就是在这个数组中进行查找
这些方法的实现大多比较直接,我们就不赘述了。
String 中还有一些方法,与这个 char 数组有关:
返回指定索引位置的 char
public char charAt(int index)
返回字符串对应的 char 数组
public char[] toCharArray()
注意,返回的是一个拷贝后的数组,而不是原数组。
将 char 数组中指定范围的字符拷贝入目标数组指定位置
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin)
7.2.2.2 按 Code Point 处理字符
与 Character 类似,String 类也提供了一些方法,按 Code Point 对字符串进行处理。
public int codePointAt(int index)
public int codePointBefore(int index)
public int codePointCount(int beginIndex, int endIndex)
public int offsetByCodePoints(int index, int codePointOffset)
7.2.3 编码转换
String 内部是按 UTF-16BE 处理字符的,对 BMP 字符,使用一个 char,两个字节,对于增补字符,使用两个 char,四个字节。我们在 2.3 节介绍过各种编码,不同编码可能用于不同的字符集,使用不同的字节数目,和不同的二进制表示。如何处理这些不同的编码呢?这些编码与 Java 内部表示之间如何相互转换呢?
Java 使用 Charset 这个类表示各种编码,它有两个常用静态方法:
public static Charset defaultCharset()
public static Charset forName(String charsetName)
第一个方法返回系统的默认编码,比如,在我的电脑上,执行如下语句:
System.out.println(Charset.defaultCharset().name());
输出为 UTF-8
第二方法返回给定编码名称的 Charset 对象,与我们在 2.3 节介绍的编码相对应,其 charset 名称可以是 US-ASCII, ISO-8859-1, windows-1252, GB2312, GBK, GB18030, Big5, UTF-8,比如:
Charset charset = Charset.forName("GB18030");
String 类提供了如下方法,返回字符串按给定编码的字节表示:
public byte[] getBytes()
public byte[] getBytes(String charsetName)
public byte[] getBytes(Charset charset)
第一个方法没有编码参数,使用系统默认编码,第二方法参数为编码名称,第三个为 Charset。
String 类有如下构造方法,可以根据字节和编码创建字符串,也就是说,根据给定编码的字节表示,创建 Java 的内部表示。
public String(byte bytes[])
public String(byte bytes[], int offset, int length)
public String(byte bytes[], int offset, int length, String charsetName)
public String(byte bytes[], int offset, int length, Charset charset)
public String(byte bytes[], String charsetName)
public String(byte bytes[], Charset charset)
除了通过 String 中的方法进行编码转换,Charset 类中也有一些方法进行编码/解码,本节就不介绍了。重要的是认识到,Java 的内部表示与各种编码是不同的,但可以相互转换。
7.2.4 不可变性
与包装类类似,String 类也是不可变类,即对象一旦创建,就没有办法修改了。String 类也声明为了 final,不能被继承,内部 char 数组 value 也是 final 的,初始化后就不能再变了。
String 类中提供了很多看似修改的方法,其实是通过创建新的 String 对象来实现的,原来的 String 对象不会被修改。比如说,我们来看 concat() 方法的代码:
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
通过 Arrays.copyOf 方法创建了一块新的字符数组,拷贝原内容,然后通过 new 创建了一个新的 String。关于 Arrays 类,我们将在后续章节详细介绍。
与包装类类似,定义为不可变类,程序可以更为简单、安全、容易理解。但如果频繁修改字符串,而每次修改都新建一个字符串,性能太低,这时,应该考虑 Java 中的另两个类 StringBuilder 和 StringBuffer,我们在下节介绍它们。
7.2.5 常量字符串
Java 中的字符串常量是非常特殊的,除了可以直接赋值给 String 变量外,它自己就像一个 String 类型的对象一样,可以直接调用 String 的各种方法。我们来看代码:
System.out.println("老马说编程".length());
System.out.println("老马说编程".contains("老马"));
System.out.println("老马说编程".indexOf("编程"));
实际上,这些常量就是 String 类型的对象,在内存中,它们被放在一个共享的地方,这个地方称为字符串常量池,它保存所有的常量字符串,每个常量只会保存一份,被所有使用者共享。当通过常量的形式使用一个字符串的时候,使用的就是常量池中的那个对应的 String 类型的对象。
比如说,我们来看代码:
String name1 = "老马说编程";
String name2 = "老马说编程";
System.out.println(name1==name2);
输出为 true,为什么呢?可以认为,“老马说编程” 在常量池中有一个对应的 String 类型的对象,我们假定名称为 laoma,上面代码实际上就类似于:
String laoma = new String(new char[]{
'老','马','说','编','程'});
String name1 = laoma;
String name2 = laoma;
System.out.println(name1==name2);
实际上只有一个 String 对象,三个变量都指向这个对象,name1==name2 也就不言而喻了。
需要注意的是,如果不是通过常量直接赋值,而是通过 new 创建的,== 就不会返回 true 了,看下面代码:
String name1 = new String("老马说编程");
String name2 = new String("老马说编程");
System.out.println(name1==name2);
输出为 false,为什么呢?上面代码类似于:
String laoma = new String(new char[]{
'老','马','说','编','程'});
String name1 = new String(laoma);
String name2 = new String(laoma);
System.out.println(name1==name2);
String 类中以 String 为参数的构造方法代码如下:
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
hash 是 String 类中另一个实例变量,表示缓存的 hashCode 值,我们待会介绍。
可以看出,name1 和 name2 指向两个不同的 String 对象,只是这两个对象内部的 value 值指向相同的 char 数组。其内存布局如图 7-1 所示。
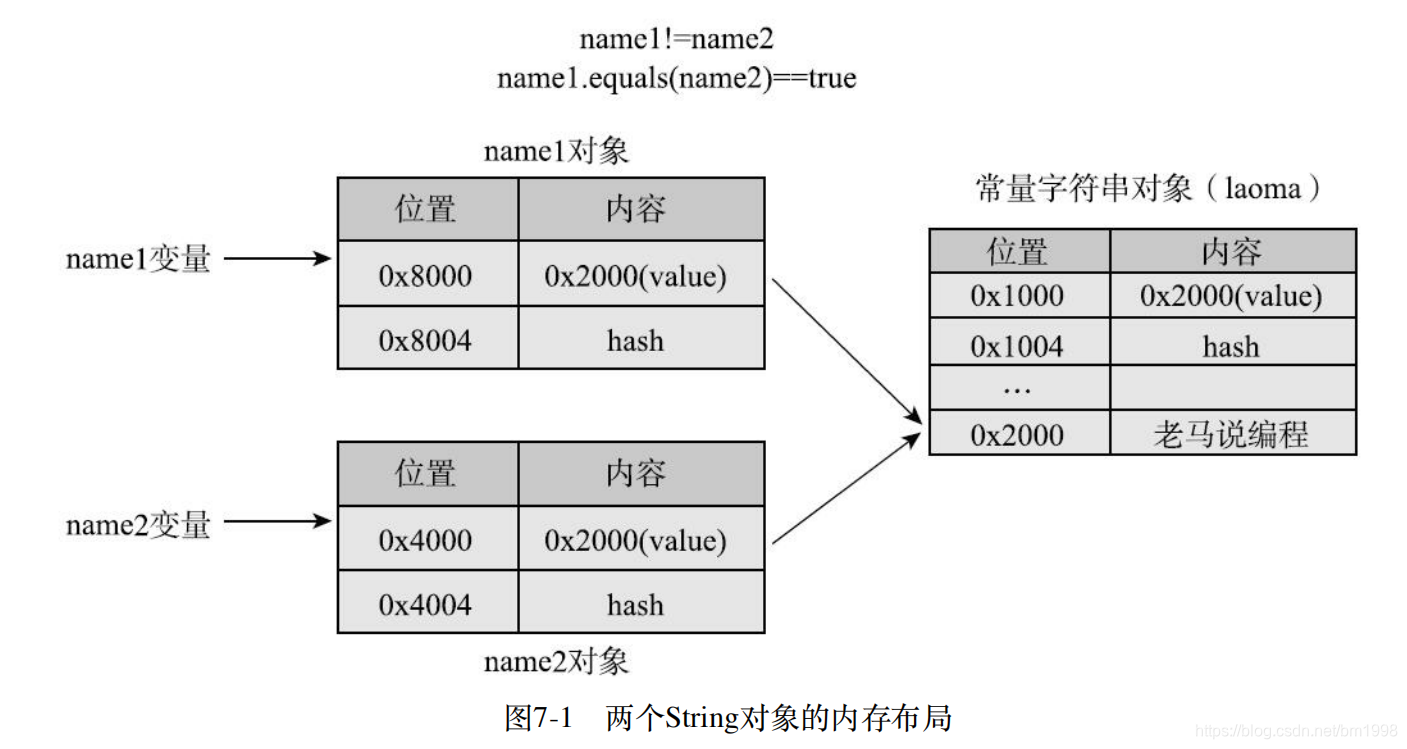
所以,name1==name2 是不成立的,但 name1.equals(name2) 是 true。
7.2.6 hashCode
我们刚刚提到 hash 这个实例变量,它的定义如下:
private int hash; // Default to 0
它缓存了 hashCode() 方法的值,也就是说,第一次调用 hashCode() 的时候,会把结果保存在 hash 这个变量中,以后再调用就直接返回保存的值。
我们来看下 String 类的 hashCode 方法,代码如下:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
如果缓存的 hash 不为 0,就直接返回了,否则根据字符数组中的内容计算 hash,计算方法是:
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
s 表示字符串,s[0] 表示第一个字符,n 表示字符串长度,s[0] * 31^(n-1) 表示 31 的 n-1 次方再乘以第一个字符的值。
为什么要用这个计算方法呢?这个式子中,hash 值与每个字符的值有关,每个位置乘以不同的值,hash 值与每个字符的位置也有关。使用 31 大概是因为两个原因,一方面可以产生更分散的散列,即不同字符串 hash 值也一般不同,另一方面计算效率比较高,31h 与 32h-h 即 (h<<5)-h 等价,可以用更高效率的移位和减法操作代替乘法操作。
在 Java 中,普遍采用以上思路来实现 hashCode。
7.2.7 正则表达式
String 类中,有一些方法接受的不是普通的字符串参数,而是正则表达式,什么是正则表达式呢?它可以理解为一个字符串,但表达的是一个规则,一般用于文本的匹配、查找、替换等,正则表达式有着丰富和强大的功能,是一个比较庞大的话题,我们将在后续章节单独介绍。
Java 中有专门的类如 Pattern 和 Matcher 用于正则表达式,但对于简单的情况,String 类提供了更为简洁的操作,String 中接受正则表达式的方法有:
分隔字符串
public String[] split(String regex)
检查是否匹配
public boolean matches(String regex)
字符串替换
public String replaceFirst(String regex, String replacement)
public String replaceAll(String regex, String replacement)
7.3 剖析 StringBuilder
7.2.4 节提到,如果字符串修改操作比较频繁,应该采用 StringBuilder 和 StringBuffer 类,这两个类的方法基本是完全一样的,它们的实现代码也几乎一样,唯一的不同就在于,StringBuffer 是线程安全的,而 StringBuilder 不是。
线程以及线程安全的概念,我们在后续章节再详细介绍。这里需要知道的就是,线程安全是有成本的,影响性能,而字符串对象及操作,大部分情况下,没有线程安全的问题,适合使用 StringBuilder。
所以,本节就只讨论 StringBuilder,包括基本用法和基本原理。
7.3.1 基本用法
创建 StringBuilder
StringBuilder sb = new StringBuilder();
添加字符串,通过 append 方法
sb.append("老马说编程");
sb.append(",探索编程本质");
获取构建后的字符串,通过 toString 方法
System.out.println(sb.toString());
输出为:
老马说编程,探索编程本质
大部分情况,使用就这么简单,通过 new 新建 StringBuilder,通过 append 添加字符串,然后通过 toString 获取构建完成的字符串。
7.3.2 基本实现原理
7.3.2.1 内部组成和构造方法
与 String 类似,StringBuilder 类也封装了一个字符数组,定义如下:
char[] value;
与 String 不同,它不是 final 的,可以修改。另外,与 String 不同,字符数组中不一定所有位置都已经被使用,它有一个实例变量,表示数组中已经使用的字符个数,定义如下:
int count;
StringBuilder 继承自 AbstractStringBuilder,它的默认构造方法是:
public StringBuilder() {
super(16);
}
调用父类的构造方法,父类对应的构造方法是:
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
也就是说,new StringBuilder() 这句代码,内部会创建一个长度为 16 的字符数组,count 的默认值为 0。
7.3.2.2 append 的实现
来看 append 的代码:
public AbstractStringBuilder append(String str) {
if (str == null) str = "null";
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
append 会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展,实际使用的长度用 count 体现。具体来说,ensureCapacityInternal(count+len) 会确保数组的长度足以容纳新添加的字符,str.getChars 会拷贝新添加的字符到字符数组中,count+=len 会增加实际使用的长度。
ensureCapacityInternal 的代码如下:
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0)
expandCapacity(minimumCapacity);
}
如果字符数组的长度小于需要的长度,则调用 expandCapacity 进行扩展,expandCapacity 的代码是:
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}
扩展的逻辑是,分配一个足够长度的新数组,然后将原内容拷贝到这个新数组中,最后让内部的字符数组指向这个新数组,这个逻辑主要靠下面这句代码实现:
value = Arrays.copyOf(value, newCapacity);
下节我们讨论 Arrays 类,本节就不介绍了,我们主要看下 newCapacity 是怎么算出来的。
参数 minimumCapacity 表示需要的最小长度,需要多少分配多少不就行了吗?不行,因为那就跟 String 一样了,每 append 一次,都会进行一次内存分配,效率低下。这里的扩展策略,是跟当前长度相关的,当前长度乘以 2,再加上 2,如果这个长度不够最小需要的长度,才用 minimumCapacity。
比如说,默认长度为 16,长度不够时,会先扩展到 16 * 2 + 2 即 34,然后扩展到 34 * 2 + 2 即 70,然后是 70 * 2 + 2 即 142,这是一种指数扩展策略。为什么要加 2?大概是因为在原长度为 0 时也可以一样工作吧。
为什么要这么扩展呢?这是一种折中策略,一方面要减少内存分配的次数,另一方面也要避免空间浪费。在不知道最终需要多长的情况下,指数扩展是一种常见的策略,广泛应用于各种内存分配相关的计算机程序中。
那如果预先就知道大概需要多长呢?可以调用 StringBuilder 的另外一个构造方法:
public StringBuilder(int capacity)
7.3.2.3 toString 实现
字符串构建完后,我们来看 toString 代码:
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
基于内部数组新建了一个 String,注意,这个 String 构造方法不会直接用 value 数组,而会新建一个,以保证 String 的不可变性。
7.3.2.4 其他修改方法
除了 append 和 toString 方法,StringBuilder 还有很多其他方法,包括更多构造方法、更多 append 方法、
插入、删除、替换、翻转、长度有关的方法,限于篇幅,就不一一列举了。
主要看下插入方法。
public StringBuilder insert(int offset, String str)
在指定索引 offset 处插入字符串 str,原来的字符后移,offset 为 0 表示在开头插,为 length() 表示在结尾插,比如说:
StringBuilder sb = new StringBuilder();
sb.append("老马说编程");
sb.insert(0, "关注");
sb.insert(sb.length(), "老马和你一起探索编程本质");
sb.insert(7, ",");
System.out.println(sb.toString());
输出为:
关注老马说编程,老马和你一起探索编程本质
来看下 insert 的实现代码:
public AbstractStringBuilder insert(int offset, String str) {
if ((offset < 0) || (offset > length()))
throw new StringIndexOutOfBoundsException(offset);
if (str == null)
str = "null";
int len = str.length();
ensureCapacityInternal(count + len);
System.arraycopy(value, offset, value, offset + len, count - offset);
str.getChars(value, offset);
count += len;
return this;
}
这个实现思路是,在确保有足够长度后,首先将原数组中 offset 开始的内容向后挪动 n 个位置,n 为待插入字符串的长度,然后将待插入字符串拷贝进 offset 位置。
挪动位置调用了 System.arraycopy 方法,这是个比较常用的方法,它的声明如下:
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
将数组 src 中 srcPos 开始的 length 个元素拷贝到数组 dest 中 destPos 处。这个方法有个优点,即使 src 和 dest 是同一个数组,它也可以正确的处理,比如说,看下面代码:
int[] arr = new int[]{
1,2,3,4};
System.arraycopy(arr, 1, arr, 0, 3);
System.out.println(arr[0]+","+arr[1]+","+arr[2]);
这里,src 和 dest 都是 arr,srcPos 为 1,destPos 为 0,length 为 3,表示将第二个元素开始的三个元素移到开头,所以输出为:
2,3,4
arraycopy 的声明有个修饰符 native,表示它的实现是通过 Java 本地接口实现的,Java 本地接口是 Java 提供的一种技术,用于在 Java 中调用非 Java 语言实现的代码,实际上,arraycopy 是用 C++ 语言实现的。为什么要用 C++ 语言实现呢?因为这个功能非常常用,而 C++ 的实现效率要远高于 Java。
7.3.3 String 的 + 和 += 运算符
Java 中,String 可以直接使用 + 和 += 运算符,这是 Java 编译器提供的支持,背后,Java 编译器会生成 StringBuilder,+ 和 += 操作会转换为append。比如说,如下代码:
String hello = "hello";
hello+=",world";
System.out.println(hello);
背后,Java 编译器会转换为:
StringBuilder hello = new StringBuilder("hello");
hello.append(",world");
System.out.println(hello.toString());
既然直接使用 + 和 += 就相当于使用 StringBuilder 和 append,那还有什么必要直接使用 StringBuilder 呢?在简单的情况下,确实没必要。不过,在稍微复杂的情况下,Java 编译器没有那么智能,它可能会生成很多 StringBuilder,尤其是在有循环的情况下,比如说,如下代码:
String hello = "hello";
for(int i=0;i<3;i++){
hello+=",world";
}
System.out.println(hello);
Java编译器转换后的代码大概如下所示:
String hello = "hello";
for(int i=0;i<3;i++){
StringBuilder sb = new StringBuilder(hello);
sb.append(",world");
hello = sb.toString();
}
System.out.println(hello);
在循环内部,每一次 += 操作,都会生成一个 StringBuilder。
所以,结论是,对于简单的情况,可以直接使用 String 的 + 和 +=,对于复杂的情况,尤其是有循环的时候,应该直接使用 StringBuilder。
7.4 剖析 Arrays
数组是存储多个同类型元素的基本数据结构,数组中的元素在内存连续存放,可以通过数组下标直接定位任意元素,相比我们在后续章节介绍的其他容器,效率非常高。
数组操作是计算机程序中的常见基本操作,Java 中有一个类 Arrays,包含一些对数组操作的静态方法,本节主要就来讨论这些方法,我们先来看怎么用,然后再来看它们的实现原理。学习 Arrays 的用法,我们就可以避免重新发明轮子,直接使用,学习它的实现原理,我们就可以在需要的时候,自己实现它不具备的功能。
7.4.1 用法
7.4.1.1 toString
Arrays 的 toString 方法可以方便的输出一个数组的字符串形式,方便查看,它有九个重载的方法,包括八种基本类型数组和一个对象类型数组,这里列举两个:
public static String toString(int[] a)
public static String toString(Object[] a)
例如:
int[] arr = {
9,8,3,4};
System.out.println(Arrays.toString(arr));
String[] strArr = {
"hello", "world"};
System.out.println(Arrays.toString(strArr));
输出为
[9, 8, 3, 4]
[hello, world]
如果不使用 Arrays.toString,直接输出数组自身,即代码改为:
int[] arr = {
9,8,3,4};
System.out.println(arr);
String[] strArr = {
"hello", "world"};
System.out.println(strArr);
则输出会变为如下所示:
[I@1224b90
[Ljava.lang.String;@728edb84
这个输出就难以阅读了,@ 后面的数字表示的是内存的地址。
7.4.1.2 排序
基本类型
排序是一个非常常见的操作,同 toString 一样,对每种基本类型的数组,Arrays 都有 sort 方法(boolean 除外),如:
public static void sort(int[] a)
public static void sort(double[] a)
排序按照从小到大升序排,看个例子:
int[] arr = {
4, 9, 3, 6, 10};
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
输出为:
[3, 4, 6, 9, 10]
数组已经排好序了。
sort 还可以接受两个参数,对指定范围内的元素进行排序,如:
public static void sort(int[] a, int fromIndex, int toIndex)
包括 fromIndex 位置的元素,不包括 toIndex 位置的元素,如:
int[] arr = {
4, 9, 3, 6, 10};
Arrays.sort(arr,0,3);
System.out.println(Arrays.toString(arr));
输出为:
[3, 4, 9, 6, 10]
只对前三个元素排序。
对象类型
除了基本类型,sort 还可以直接接受对象类型,但对象需要实现 Comparable 接口。
public static void sort(Object[] a)
public static void sort(Object[] a, int fromIndex, int toIndex)
我们看个 String 数组的例子:
String[] arr = {
"hello","world", "Break","abc"};
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
输出为:
[Break, abc, hello, world]
"Break" 之所以排在最前面,是因为大写字母比小写字母都小。那如果排序的时候希望忽略大小写呢?
自定义比较器
sort 还有另外两个重载方法,可以接受一个比较器作为参数:
public static <T> void sort(T[] a, Comparator<? super T> c)
public static <T> void sort(T[] a, int fromIndex, int toIndex,
Comparator<? super T> c)
方法声明中的 T 表示泛型,泛型我们在后续章节再介绍,这里表示的是,这个方法可以支持所有对象类型,只要传递这个类型对应的比较器就可以了。Comparator 就是比较器,它是一个接口,定义是:
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
}
最主要的是 compare 这个方法,它比较两个对象,返回一个表示比较结果的值,-1 表示 o1 小于 o2,0 表示相等,1 表示 o1 大于 o2。
排序是通过比较来实现的,sort 方法在排序的过程中,需要对对象进行比较的时候,就调用比较器的 compare 方法。
String 类有一个 public 静态成员,表示忽略大小写的比较器:
public static final Comparator<String> CASE_INSENSITIVE_ORDER
= new CaseInsensitiveComparator();
我们通过这个比较器再来对上面的 String 数组排序:
String[] arr = {
"hello","world", "Break","abc"};
Arrays.sort(arr, String.CASE_INSENSITIVE_ORDER);
System.out.println(Arrays.toString(arr));
这样,大小写就忽略了,输出变为了:
[abc, Break, hello, world]
为进一步理解 Comparator,我们来看下 String 的这个比较器的主要实现代码:
private static class CaseInsensitiveComparator
implements Comparator<String> {
public int compare(String s1, String s2) {
int n1 = s1.length();
int n2 = s2.length();
int min = Math.min(n1, n2);
for (int i = 0; i < min; i++) {
char c1 = s1.charAt(i);
char c2 = s2.charAt(i);
if (c1 != c2) {
c1 = Character.toUpperCase(c1);
c2 = Character.toUpperCase(c2);
if (c1 != c2) {
c1 = Character.toLowerCase(c1);
c2 = Character.toLowerCase(c2);
if (c1 != c2) {
// No overflow because of numeric promotion
return c1 - c2;
}
}
}
}
return n1 - n2;
}
}
代码比较直接,就不解释了。
sort 默认都是从小到大排序,如果希望按照从大到小排呢?对于对象类型,可以指定一个不同的 Comparator,可以用匿名内部类来实现 Comparator,比如可以这样:
String[] arr = {
"hello","world", "Break","abc"};
Arrays.sort(arr, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareToIgnoreCase(o1);
}
});
System.out.println(Arrays.toString(arr));
程序输出为:
[world, hello, Break, abc]
以上代码使用一个匿名内部类实现 Comparator 接口,返回 o2 与 o1 进行忽略大小写比较的结果,这样就能实现,忽略大小写,且按从大到小排序。为什么 o2 与 o1 比就逆序了呢?因为默认情况下,是 o1 与 o2 比。
Collections 类中有两个静态方法,可以返回逆序的 Comparator,如:
public static <T> Comparator<T> reverseOrder()
public static <T> Comparator<T> reverseOrder(Comparator<T> cmp)
关于 Collections 类,我们在后续章节再详细介绍。
这样,上面字符串忽略大小写逆序排序的代码可以改为:
String[] arr = {
"hello","world", "Break","abc"};
Arrays.sort(arr, Collections.reverseOrder(String.CASE_INSENSITIVE_ORDER));
System.out.println(Arrays.toString(arr));
传递比较器 Comparator 给 sort 方法,体现了程序设计中一种重要的思维方式,将不变和变化相分离,排序的基本步骤和算法是不变的,但按什么排序是变化的,sort 方法将不变的算法设计为主体逻辑,而将变化的排序方式设计为参数,允许调用者动态指定,这也是一种常见的设计模式,它有一个名字,叫策略模式,不同的排序方式就是不同的策略。
7.4.1.3 查找
Arrays 包含很多与 sort 对应的查找方法,可以在已排序的数组中进行二分查找,所谓二分查找就是从中间开始找,如果小于中间元素,则在前半部分找,否则在后半部分找,每比较一次,要么找到,要么将查找范围缩小一半,所以查找效率非常高。
二分查找既可以针对基本类型数组,也可以针对对象数组,对对象数组,也可以传递 Comparator,也都可以指定查找范围,如下所示:
针对 int 数组
public static int binarySearch(int[] a, int key)
public static int binarySearch(int[] a, int fromIndex, int toIndex,
int key)
针对对象数组
public static int binarySearch(Object[] a, Object key)
自定义比较器
public static <T> int binarySearch(T[] a, T key, Comparator<? super T> c)
如果能找到,binarySearch 返回找到的元素索引,比如说:
int[] arr = {
3,5,7,13,21};
System.out.println(Arrays.binarySearch(arr, 13));
输出为 3。如果没找到,返回一个负数,这个负数等于:-(插入点+1),插入点表示,如果在这个位置插入没找到的元素,可以保持原数组有序,比如说:
int[] arr = {
3,5,7,13,21};
System.out.println(Arrays.binarySearch(arr, 11));
输出为 -4,表示插入点为 3,如果在 3 这个索引位置处插入 11,可以保持数组有序,即数组会变为:{3,5,7,11,13,21}
需要注意的是,binarySearch 针对的必须是已排序数组,如果指定了 Comparator,需要和排序时指定的 Comparator 保持一致,另外,如果数组中有多个匹配的元素,则返回哪一个是不确定的。
7.4.1.4 更多方法
数组拷贝
基于原数组,复制一个新数组,与 toString 一样,也有多种重载形式,如:
public static long[] copyOf(long[] original, int newLength)
public static <T> T[] copyOf(T[] original, int newLength)
数组比较
判断两个数组是否相同,支持基本类型和对象类型,如下所示:
public static boolean equals(boolean[] a, boolean[] a2)
public static boolean equals(double[] a, double[] a2)
public static boolean equals(Object[] a, Object[] a2)
只有数组长度相同,且每个元素都相同,才返回 true,否则返回 false。对于对象,相同是指 equals 返回 true。
填充值
Arrays 包含很多 fill 方法,可以给数组中的每个元素设置一个相同的值:
public static void fill(int[] a, int val)
也可以给数组中一个给定范围的每个元素设置一个相同的值:
public static void fill(int[] a, int fromIndex, int toIndex, int val)
哈希值
针对数组,计算一个数组的哈希值:
public static int hashCode(int a[])
计算 hashCode 的算法和 String 是类似的,我们看下代码:
public static int hashCode(int a[]) {
if (a == null)
return 0;
int result = 1;
for (int element : a)
result = 31 * result + element;
return result;
}
回顾一下,String 计算 hashCode 的算法也是类似的,数组中的每个元素都影响 hash 值,位置不同,影响也不同,使用 31 一方面产生的哈希值更分散,另一方面计算效率也比较高。
7.4.2 多维数组
之前我们介绍的数组都是一维的,数组还可以是多维的,先来看二维数组,比如:
int[][] arr = new int[2][3];
for(int i=0;i<arr.length;i++){
for(int j=0;j<arr[i].length;j++){
arr[i][j] = i+j;
}
}
arr 就是一个二维数组,第一维长度为 2,第二维长度为 3,类似于一个长方形矩阵,或者类似于一个表格,第一维表示行,第二维表示列。arr[i] 表示第 i 行,它本身还是一个数组,arri 表示第 i 行中的第 j 个元素。
除了二维,数组还可以是三维、四维等,但一般而言,很少用到三维以上的数组,有几维,就有几个 [],比如说,一个三维数组的声明为:
int[][][] arr = new int[10][10][10];
在创建数组时,除了第一维的长度需要指定外,其他维的长度不需要指定,甚至,第一维中,每个元素的第二维的长度可以不一样,看个例子:
int[][] arr = new int[2][];
arr[0] = new int[3];
arr[1] = new int[5];
arr 是一个二维数组,第一维的长度为 2,第一个元素的第二维长度为 3,而第二个为 5。
多维数组到底是什么呢?其实,可以认为,多维数组只是一个假象,只有一维数组,只是数组中的每个元素还可以是一个数组,这样就形成二维数组,如果其中每个元素还都是一个数组,那就是三维数组。
Arrays 中的 toString,equals,hashCode 都有对应的针对多维数组的方法:
public static String deepToString(Object[] a)
public static boolean deepEquals(Object[] a1, Object[] a2)
public static int deepHashCode(Object a[])
这些 deepXXX 方法,都会判断参数中的元素是否也为数组,如果是,会递归进行操作。
看个例子:
int[][] arr = new int[][]{
{
0,1},
{
2,3,4},
{
5,6,7,8}
};
System.out.println(Arrays.deepToString(arr));
输出为:
[[0, 1], [2, 3, 4], [5, 6, 7, 8]]
7.4.3 实现原理
下面介绍 Arrays 的方法的实现原理。hashCode 的实现我们已经介绍了,fill 和 equals 的实现都很简单,循环操作而已,就不赘述了。
7.4.3.1 二分查找
二分查找 binarySearch 的代码也比较直接,主要代码如下:
private static <T> int binarySearch0(T[] a, int fromIndex, int toIndex,
T key, Comparator<? super T> c) {
int low = fromIndex;
int high = toIndex - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
T midVal = a[mid];
int cmp = c.compare(midVal, key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}
有两个标志 low 和 high,表示查找范围,在 while 循环中,与中间值进行对比,大于则在后半部分找(提高 low),否则在前半部分找(降低 high)。
7.4.3.2 排序
最后,我们来看排序方法 sort,与前面这些简单直接的方法相比,sort 要复杂的多,排序是计算机程序中一个非常重要的方面,几十年来,计算机科学家和工程师们对此进行了大量的研究,设计实现了各种各样的算法和实现,进行了大量的优化。一般而言,没有一个所谓最好的算法,不同算法往往有不同的适用场合。
那 Arrays 的 sort 是如何实现的呢?
对于基本类型的数组,Java 采用的算法是双枢轴快速排序(Dual-Pivot Quicksort),这个算法是 Java 1.7 引入的,在此之前,Java 采用的算法是普通的快速排序,双枢轴快速排序是对快速排序的优化,新算法的实现代码位于类 java.util.DualPivotQuicksort 中。
对于对象类型,Java 采用的算法是 TimSort, TimSort 也是在 Java 1.7 引入的,在此之前,Java 采用的是归并排序,TimSort 实际上是对归并排序的一系列优化,TimSort 的实现代码位于类 java.util.TimSort 中。
在这些排序算法中,如果数组长度比较小,它们还会采用效率更高的插入排序。
为什么基本类型和对象类型的算法不一样呢?排序算法有一个稳定性的概念,所谓稳定性就是对值相同的元素,如果排序前和排序后,算法可以保证它们的相对顺序不变,那算法就是稳定的,否则就是不稳定的。
快速排序更快,但不稳定,而归并排序是稳定的。对于基本类型,值相同就是完全相同,所以稳定不稳定没有关系。但对于对象类型,相同只是比较结果一样,它们还是不同的对象,其他实例变量也不见得一样,稳定不稳定可能就很有关系了,所以采用归并排序。
这些算法的实现是比较复杂的,所幸的是,Java 给我们提供了很好的实现,绝大多数情况下,我们会用就可以了。
7.4.4 小结
其实,Arrays 中包含的数组方法是比较少的,很多常用的操作没有,比如,Arrays 的 binarySearch 只能针对已排序数组进行查找,那没有排序的数组怎么方便查找呢?
Apache 有一个开源包(http://commons.apache.org/proper/commons-lang/),里面有一个类 ArrayUtils (位于包 org.apache.commons.lang3),包含了更多的常用数组操作,这里就不列举了。
数组是计算机程序中的基本数据结构,Arrays 类以及 ArrayUtils 类封装了关于数组的常见操作,使用这些方法,避免“重新发明轮子”吧。