一、前言
根据前面博文 使用lenet模型训练及预测自己的图片数据 可得到训练得的caffemodel及其他相关的文件,回顾下My_FIle文件夹如下,predictPic文件夹中保存的是名为“0“~“9“的文件夹,分别保存相应的0~9的多张字符图片:

使用classification.bin只能预测单张图片,或者使用caffe.bin test ***.prototxt ***.caffemodel -iterations n的方法可以预测多张图片,这里则使用pyhton接口预测多张图片的类别。需要使用My_File中的deploy.prototxt、caffemodel文件,均值文件mean.binaryproto。首先需要将mean.binaryproto转换为python接口需要的.npy文件,可参考博文http://blog.csdn.net/hyman_yx/article/details/51732656,转换的mean.npy保存于My_File/Mean/。在caffe/python/下新建python文件predict_all.py,输入以下内容。
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import cv2
import numpy as np
import sys,os
import caffe
def GetFileList(dir, fileList):
newDir = dir
if os.path.isfile(dir):
fileList.append(dir.decode('gbk'))
elif os.path.isdir(dir):
for s in os.listdir(dir):
newDir=os.path.join(dir,s)
GetFileList(newDir, fileList)
return fileList
if __name__=='__main__':
caffe_root='/home/jyang/caffe/'
sys.path.insert(0,caffe_root+'python')
os.chdir(caffe_root)
net_file=caffe_root+'My_File/Deploy/deploy.prototxt'
caffe_model=caffe_root+'My_File/lenet_iter_10000.caffemodel'
mean_file=caffe_root+'My_File/Mean/mean.npy'
net=caffe.Net(net_file,caffe_model,caffe.TEST)
transformer=caffe.io.Transformer({'data':net.blobs['data'].data.shape})
transformer.set_transpose('data',(2,0,1))
transformer.set_mean('data',np.load(mean_file).mean(1).mean(1))
transformer.set_raw_scale('data',225)
transformer.set_channel_swap('data',(2,1,0))
imagenet_labels_filename=caffe_root+'My_File/Synset/synset_words.txt'
labels=np.loadtxt(imagenet_labels_filename,str,delimiter='\t')
MyPicList=GetFileList('My_File/predictPic',[])
f=open('My_File/res.txt','w')
for imgPath in MyPicList:
img=caffe.io.load_image(caffe_root+imgPath)
img=img[...,::-1]
net.blobs['data'].data[...]=transformer.preprocess('data',img)
out=net.forward()
top_k=net.blobs['prob'].data[0].flatten().argsort()[-1:-5:-1]
f.writelines(imgPath+' '+labels[top_k[0]]+'\n' )
f.close()
二、结果
将所有的预测结果保存至res.txt文件,准确率没计算出来,最右边为该图片的预测分类
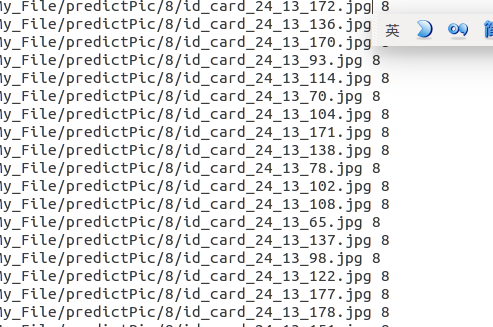
正确率很高,训练和测试的数字图片都是身份证图片上切分下来的号码字符,当然也有错分的情况,如下3被误判为1了:

三、参考博文
http://blog.csdn.net/u010142666/article/details/60469393