作者:小羊子说
前言
正直2020金九银十,第一次换工作或是面试候选人,我们都会对面试知识做一次总结梳理,毕竟开发技术无边界,不同人对技术的解读不同。文章总结了最近大半年中的面试考查点V1.0,希望对你有所帮助。
注:整理中有重复的知识点,说明频率较高,同时也是有不同角度的回答,也同时帮你更全面的认识。
面试建议:算法、基础是敲门砖,项目是试金石,良好的面试形象是加分项。
推荐:厚积方能薄发,通往Android封神之路的知识体系
字节4轮面试,3轮都问了RecyclerView
面试官:3年Android还不懂性能优化?谁给你的自信出来混
一、Java基础
1.synchronized的修饰对象
当synchronized用来修饰静态方法或者类时,将会使得这个类的所有对象都是共享一把类锁,导致线程阻塞,所以这种写法一定要 规避
无论synchronized关键字加在方法上还是对象上,如果它作用的对象是非静态的,则它取得的锁是对象;如果synchronized作用的对象是一个静态方法或一个类,则它取得的锁是对类,该类所有的对象同一把锁。
每个对象只有一个锁(lock)与之相关联,谁拿到这个锁谁就可以运行它所控制的那段代码。
实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
2. try{}catch{}finally中的执行顺序
任何执行try 或者catch中的return语句之前,都会先执行finally语句,如果finally存在的话。
如果finally中有return语句,那么程序就return了,所以finally中的return是一定会被return的,
编译器把finally中的return实现为一个warning。
下面是个测试程序
public class FinallyTest
{
public static void main(String[] args) {
System.out.println(test());;
}
static int test()
{
int x = 1;
try
{
x++;
return x;
}
finally
{
++x;
}
}
}运行结果:2
说明:在try语句中,在执行return语句时,要返回的结果已经准备好了,就在此时,程序转到finally执行了。
在转去之前,try中先把要返回的结果存放到不同于x的局部变量中去,执行完finally之后,在从中取出返回结果,
因此,即使finally中对变量x进行了改变,但是不会影响返回结果。
它应该使用栈保存返回值。
3. Java中的死锁
- Java中的ArrayList是否是线程安全
- 为什么ArrayList线程不安全?不安全为什么要使用?如何解决线程不安全?
首先说一下什么是线程不安全:线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。
不会出现数据不一致或者数据污染。线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。
List接口下面有两个实现,一个是ArrayList,另外一个是vector。
从源码的角度来看,因为Vector的方法前加了,synchronized 关键字,也就是同步的意思,sun公司希望Vector是线程安全的,而希望arraylist是高效的,缺点就是另外的优点。
说下原理:一个 ArrayList ,在添加一个元素的时候,它可能会有两步来完成:在 Items[Size] 的位置存放此元素;增大 Size 的值。
在单线程运行的情况下,如果 Size = 0,添加一个元素后,此元素在位置 0,而且 Size=1;而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置 0。
但是此时 CPU 调度线程A暂停,线程 B 得到运行的机会。线程B也向此 ArrayList 添加元素,因为此时 Size 仍然等于 0 (注意哦,我们假设的是添加一个元素是要两个步骤哦,而线程A仅仅完成了步骤1),所以线程B也将元素存放在位置0。
然后线程A和线程B都继续运行,都增加 Size 的值。那好,现在我们来看看 ArrayList 的情况,元素实际上只有一个,存放在位置 0,而 Size 却等于 2。这就是“线程不安全”了。
不安全为什么要使用?
这个ArrayList比线程安全的Vector效率高。
如何解决线程不安全
使用synchronized关键字,这个大家应该都很熟悉了,不解释了;
二:使用Collections.synchronizedList();使用方法如下:
假如你创建的代码如下:
List<Map<String,Object>>data=new ArrayList<Map<String,Object>>();
那么为了解决这个线程安全问题你可以这么使用Collections.synchronizedList(),如:
List<Map<String,Object>> data=Collections.synchronizedList(newArrayList<Map<String,Object>>());
其他的都没变,使用的方法也几乎与ArrayList一样,大家可以参考下api文档;
额外说下 ArrayList与LinkedList;这两个都是接口List下的一个实现,用法都一样,但用的场所的有点不同,ArrayList适合于进行大量的随机访问的情况下使用,LinkedList适合在表中进行插入、删除时使用,二者都是非线程安全,解决方法同上(为了避免线程安全,以上采取的方法,特别是第二种,其实是非常损耗性能的)。
- Java和Vector的区别
首先看这两类都实现List接口,而List接口一共有三个实现类,分别是ArrayList、Vector和LinkedList。List用于存放多个元素,能够维护元素的次序,并且允许元素的重复。3个具体实现类的相关区别如下:
1.ArrayList是最常用的List实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要讲已经有数组的数据复制到新的存储空间中。当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
2.Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢。
3.LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
4.vector是线程(Thread)同步(Synchronized)的,所以它也是线程安全的,而Arraylist是线程异步(ASynchronized)的,是不安全的。
5.如果不考虑到线程的安全因素,一般用Arraylist效率比较高。如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度
的50%.如果在集合中使用数据量比较大的数据,用vector有一定的优势。
6.如果查找一个指定位置的数据,vector和arraylist使用的时间是相同的,都是0(1),这个时候使用vector和arraylist都可以。而
如果移动一个指定位置的数据花费的时间为0(n-i)n为总长度,这个时候就应该考虑到使用Linkedlist,因为它移动一个指定位置的数据 所花费的时间为0(1),而查询一个指定位置的数据时花费的时间为0(i)。
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,
都允许直接序号索引元素,但是插入数据要设计到数组元素移动 等内存操作,所以索引数据快插入数据慢,
Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差
,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快!
7.笼统来说:LinkedList:增删改快
ArrayList:查询快(有索引的存在)
4.synchronized和volatile关键字的区别
1.volatile 本质是在告诉 jvm 当前变量在寄存器(工作内存)中的值是不确定的, 需要从主存中读取;
synchronized 则是锁定当前变量,只有当前线程可以访问该 变量,其他线程被阻塞住。
2.volatile 仅能使用在变量级别;synchronized 则可以使用在变量、方法、和类级 别的
3.volatile 仅能实现变量的修改可见性,不能保证原子性;而 synchronized 则可以 保证变量的修改可见性和原子性
4.volatile 不会造成线程的阻塞;synchronized 可能会造成线程的阻塞。
5.volatile 标记的变量不会被编译器优化;synchronized 标记的变量可以被编译器优化
5.Java中的自动装箱和自动拆箱
所以,当 “==”运算符的两个操作数都是 包装器类型的引用,则是比较指向的是否是同一个对象,而如果其中有一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。
通过上面的分析我们需要知道两点:
1、什么时候会引发装箱和拆箱
2、装箱操作会创建对象,频繁的装箱操作会消耗许多内存,影响性能,所以可以避免装箱的时候应该尽量避免。
6.Java中的乐观锁和悲观锁
- 悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中 synchronized 和 ReentrantLock 等独占锁就是悲观锁思想的实现。
- 乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中 java.util.concurrent.atomic 包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
- 两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
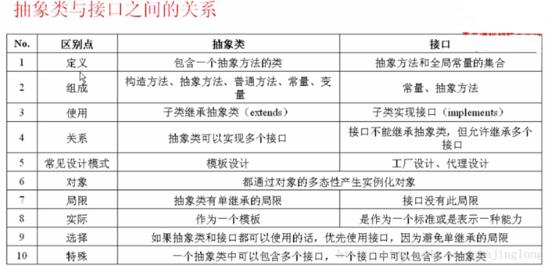
7.抽象类和接口
如何理解与记忆:
1.抽象类–>像xxx一样
接 口–>能xxx这样
2.接口是设计的结果,抽象类是重构的结果。
8.JAVA内存模型
jmm内存分配的概念:
- 堆heap: 优点:运行时数据区,动态分配内存大小,有gc;,缺点:因为要在运行时动态分配,所以存取速度慢,对象存储在堆上,静态类型的变量跟着类的定义一起存储在堆上。栈stack:存取速度快,仅次于寄存器,缺点:数据大小与生存期必须是确定的,缺乏灵活性,栈中主要存放基本类型变量(比如,int,shot,byte,char,double,foalt,boolean和对象句柄),jmm要求,调用栈和本地变量存放在线程栈上
当一个线程可以访问一个对象时,也可以访问对象的成员变量,如果有两个线程访问对象的成员变量,则每个线程都有对象的成员变量的私有拷贝。
- 处理器(cpu): 寄存器:每个cpu都包含一系列寄存器,他们是cpu的基础,寄存器执行的速度,远大于在主存上执行的速度
- cpu高速缓存:由于处理器与内存访问速度差距非常大,所以添加了读写速度尽可能接近处理器的高速缓存,来作为内存与处理器之间的缓冲,将数据读到缓存中,让运算快速进行,当运算结束,再从缓存同步到主存中,就无须等待缓慢的内存读写了。处理器访问缓存的速度快与访问主存的速度,但比访问内部寄存器的速度还是要慢点,每个cpu有一个cpu的缓存层,一个cpu含有多层缓存,,某一时刻,一个或者多个缓存行可能同时被读取到缓存取,也可能同时被刷新到主存中,同一时刻,可能存在多个操作,
- 内存:一个计算机包含一个主存,所有cpu都可以访问主存,主存通常远大于cpu中的缓存,
运作原理: 通常,当一个cpu需要读取主存时,他会将主存的内容读取到缓存中,将缓存中的内容读取到内部寄存器中,在寄存器中执行操作,当cpu需要将结果回写到主存中时,他会将内部寄存器的值刷新到缓存中,然后会在某个时间点将值刷新回主存。 - ……
9. GC Roots如何确定?哪些对象可以作为GC Roots?
- 判断对象是否可以被回收之引用计数法:
Java中,引用和对象是有关联的。如果要操作对象则必须用引用进行。
因此,很显然一个简单的办法是通过引用计数来判断一个对象是否可以回收。简单说,给对象中添加一个引用计数器,每当有一个地方引用它,计数器值加1,每当有一个引用失效时,计数器值减1。
任何时刻计数器值为零的对象就是不可能再被使用的,那么这个对象就是可回收对象。
那为什么主流的Java虚拟机里面都没有选用这种算法呢?其中最主要的原因是它很难解决对象之间相互循环引用的问题。
-
判断对象是否可以被回收之枚举根节点可达性分析
为了解决引用计数法的循环引用问题,Java使用了可达性分析的方法。所谓"GC roots,或者说tracing GC的“根集合”就是一组必须活跃的引用。基本思路就是通过一系列名为”GCRoots”的对象作为起始点,从这个被称为GC Roots的对象开始向下搜索,如果一个对象到GCRoots没有任何引用链相连时,则说明此对象不可用。也即给定一个集合的引用作为根出发,通过引用关系遍历对象图,能被遍历到的(可到达的)对象就被判定为存活,没有被遍历到的就自然被判定为死亡。 -
Java中可以作为GC Roots的对象:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI(即一般说的native方法)中引用的对象
抽象类和接口的区别
四种引用的区别

二、Android方面
1.热修复的原理
我们知道Java虚拟机 —— JVM 是加载类的class文件的,而Android虚拟机——Dalvik/ART VM 是加载类的dex文件,
而他们加载类的时候都需要ClassLoader,ClassLoader有一个子类BaseDexClassLoader,
而BaseDexClassLoader下有一个数组——DexPathList,是用来存放dex文件,当BaseDexClassLoader通过调用findClass方法时,实际上就是遍历数组,找到相应的dex文件,找到则直接将它return。
而热修复的解决方法就是将新的dex添加到该集合中,并且是在旧的dex的前面,
所以就会优先被取出来并且return返回。
2.Android中跨进程通讯的几种方式
Android 跨进程通信,像intent,contentProvider,广播,service都可以跨进程通信。
intent:这种跨进程方式并不是访问内存的形式,它需要传递一个uri,比如说打电话。
contentProvider:这种形式,是使用数据共享的形式进行数据共享。
service:远程服务,aidl
3.AIDL理解
此处延伸:简述Binder
AIDL:
每一个进程都有自己的Dalvik VM实例,都有自己的一块独立的内存,都在自己的内存上存储自己的数据,执行着自己的操作,都在自己的那片狭小的空间里过完自己的一生。而aidl就类似与两个进程之间的桥梁,使得两个进程之间可以进行数据的传输,跨进程通信有多种选择,比如 BroadcastReceiver , Messenger 等,但是 BroadcastReceiver 占用的系统资源比较多,如果是频繁的跨进程通信的话显然是不可取的;Messenger 进行跨进程通信时请求队列是同步进行的,无法并发执行。
Binde机制简单理解:
在Android系统的Binder机制中,是有Client,Service,ServiceManager,Binder驱动程序组成的,其中Client,service,Service Manager运行在用户空间,Binder驱动程序是运行在内核空间的。而Binder就是把这4种组件粘合在一块的粘合剂,其中核心的组件就是Binder驱动程序,Service Manager提供辅助管理的功能,而Client和Service正是在Binder驱动程序和Service Manager提供的基础设施上实现C/S 之间的通信。其中Binder驱动程序提供设备文件/dev/binder与用户控件进行交互,
Client、Service,Service Manager通过open和ioctl文件操作相应的方法与Binder驱动程序进行通信。而Client和Service之间的进程间通信是通过Binder驱动程序间接实现的。而Binder Manager是一个守护进程,用来管理Service,并向Client提供查询Service接口的能力。
4.Android内存泄露及管理 (深度延伸下去)
(1)内存溢出(OOM)和内存泄露(对象无法被回收)的区别。
(2)引起内存泄露的原因
(3)内存泄露检测工具 ------>LeakCanary
内存溢出 out of memory:是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出。内存溢出通俗的讲就是内存不够用。
内存泄露 memory leak:是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光
内存泄露原因:
一、Handler 引起的内存泄漏。
解决:将Handler声明为静态内部类,就不会持有外部类SecondActivity的引用,其生命周期就和外部类无关,
如果Handler里面需要context的话,可以通过弱引用方式引用外部类
二、单例模式引起的内存泄漏。
解决:Context是ApplicationContext,由于ApplicationContext的生命周期是和app一致的,不会导致内存泄漏
三、非静态内部类创建静态实例引起的内存泄漏。
解决:把内部类修改为静态的就可以避免内存泄漏了
四、非静态匿名内部类引起的内存泄漏。
解决:将匿名内部类设置为静态的。
五、注册/反注册未成对使用引起的内存泄漏。
注册广播接受器、EventBus等,记得解绑。
六、资源对象没有关闭引起的内存泄漏。
在这些资源不使用的时候,记得调用相应的类似close()、destroy()、recycler()、release()等方法释放。
5.Java虚拟机和Dalvik虚拟机的区别
Java虚拟机:
1、java虚拟机基于栈。 基于栈的机器必须使用指令来载入和操作栈上数据,所需指令更多更多。
2、java虚拟机运行的是java字节码。(java类会被编译成一个或多个字节码.class文件)
Dalvik虚拟机:
1、dalvik虚拟机是基于寄存器的
2、Dalvik运行的是自定义的.dex字节码格式。(java类被编译成.class文件后,会通过一个dx工具将所有的.class文件转换成一个.dex文件,然后dalvik虚拟机会从其中读取指令和数据
3、常量池已被修改为只使用32位的索引,以 简化解释器。
4、一个应用,一个虚拟机实例,一个进程(所有android应用的线程都是对应一个linux线程,都运行在自己的沙盒中,不同的应用在不同的进程中运行。每个android dalvik应用程序都被赋予了一个独立的linux PID(app_*))
6.四种LaunchMode及其使用场景(结合书中上场景再总结)
standard 模式
这是默认模式,每次激活Activity时都会创建Activity实例,并放入任务栈中。使用场景:大多数Activity。
singleTop 模式
如果在任务的栈顶正好存在该Activity的实例,就重用该实例( 会调用实例的 onNewIntent() ),否则就会创建新的实例并放入栈顶,即使栈中已经存在该Activity的实例,只要不在栈顶,都会创建新的实例。使用场景如新闻类或者阅读类App的内容页面。
singleTask 模式
如果在栈中已经有该Activity的实例,就重用该实例(会调用实例的 onNewIntent() )。重用时,会让该实例回到栈顶,因此在它上面的实例将会被移出栈。如果栈中不存在该实例,将会创建新的实例放入栈中。使用场景如浏览器的主界面。不管从多少个应用启动浏览器,只会启动主界面一次,其余情况都会走onNewIntent,并且会清空主界面上面的其他页面。
singleInstance 模式
在一个新栈中创建该Activity的实例,并让多个应用共享该栈中的该Activity实例。一旦该模式的Activity实例已经存在于某个栈中,任何应用再激活该Activity时都会重用该栈中的实例( 会调用实例的 onNewIntent() )。其效果相当于多个应用共享一个应用,不管谁激活该 Activity 都会进入同一个应用中。使用场景如闹铃提醒,将闹铃提醒与闹铃设置分离。singleInstance不要用于中间页面,如果用于中间页面,跳转会有问题,比如:A -> B (singleInstance) -> C,完全退出后,在此启动,首先打开的是B。
7.启动模式 (其他应用场景)
- standard 标准模式
- singleTop 栈顶复用模式 (例如:推送点击消息界面)
- singleTask 栈内复用模式 (例如:首页)
- singleInstance 单例模式 (单独位于一个任务栈中,例如:拨打电话界面)
8. 进程 IPC 进程通讯方式
- Intent 、Bundle : 要求传递数据能被序列化,实现 Parcelable、Serializable ,适用于四大组件通信。
- 文件共享 :适用于交换简单的数据实时性不高的场景。
- AIDL:AIDL 接口实质上是系统提供给我们可以方便实现 BInder 的工具
- Messenger:基于 AIDL 实现,服务端串行处理,主要用于传递消息,适用于低并发一对多通信
- ContentProvider:基于 Binder 实现,适用于一对多进程间数据共享(通讯录 短信 等)
- Socket:TCP、UDP,适用于网络数据交换
9.为什么要用Binder?(有什么优势?)
- Android使用的Linux内核 拥有有着非常多的跨进程通信机制
- 性能
- 安全
10.View 工作流程
通过 SetContentView(),调用 到PhoneWindow ,后实例DecorView ,通过 LoadXmlResourceParser() 进行IO操作 解析xml文件 通过反射 创建出View,并将View绘制在 DecorView上,这里的绘制则交给了ViewRootImpl 来完成,通过performTraversals() 触发绘制流程,performMeasure 方法获取View的尺寸,performLayout 方法获取View的位置 ,然后通过 performDraw 方法遍历View 进行绘制。
11.事件分发
一个 MotionEvent 产生后,按 Activity -> Window -> DecorView(ViewGroup) -> View 顺序传递,View 传递过程就是事件分发,因为开发过程中存在事件冲突,所以需要熟悉流程:
- dispatchTouchEvent :用于分发事件,只要接受到点击事件就会被调用,返回结果表示是否消耗了当前事件
- onInterceptTouchEvent :用于判断是否拦截事件(只有ViewGroup中存在),当 ViewGroup 确定要拦截事件后,该事件序列都不会再触发调用此 ViewGroup 的 onIntercept
- onTouchEvent :用于处理事件,返回结果表示是否处理了当前事件,未处理则传递给父容器处理。(事件顺序是:OnTouchListener -> OnTouchEvent -> OnClick)
12. Handler机制整体流程
IdHandler(闲时机制);
postDelay()的具体实现;
post()与sendMessage()区别;
使用Handler需要注意什么问题,怎么解决的?
问题很细,能准备多详细就准备多详细。人家自己封装了一套 Handler 来避免内存泄漏问题
13.Looper.loop()为什么不会阻塞主线程
主线程Looper从消息队列读取消息,当读完所有消息时,主线程阻塞。子线程往消息队列发送消息,并且往管道文件写数据,主线程即被唤醒,从管道文件读取数据,主线程被唤醒只是为了读取消息,当消息读取完毕,再次睡眠。因此 loop的循环并不会对CPU性能有过多的消耗 。
主线程中如果没有looper进行循环,那么主线程一运行完毕就会退出。那么我们还能运行APP吗,显然,这是不可能的,Looper主要就是做消息循环,然后由Handler进行消息分发处理,一旦退出消息循环,那么你的应用也就退出了。
总结:Looper的无限循环必不可少。
补充说明:
我看有一部分人理解”Looper.loop()的阻塞“和”UI线程上执行耗时操作卡死“的区别时还一脸懵逼的状况,简单回答一波:
- 首先这两之间一点联系都没有,完全两码事。
- Looper上的阻塞, 前提是没有输入事件 ,MsgQ为空,Looper空闲状态,线程进入阻塞,释放CPU执行权,等待唤醒。
- UI耗时导致卡死, 前提是要有输入事件, MsgQ不为空,Looper正常轮询,线程并没有阻塞,但是该事件执行时间过长(5秒?),而且与此期间其他的事件(按键按下,屏幕点击…)都没办法处理(卡死),然后就ANR异常了。
14 . Android – Looper.prepare()和Looper.loop() —深入版
Android中的Looper类,是用来封装消息循环和消息队列的一个类,用于在android线程中进行消息处理。handler其实可以看做是一个工具类,用来向消息队列中插入消息的。
(1) Looper类用来为一个线程开启一个消息循环。 默认情况下android中新诞生的线程是没有开启消息循环的。(主线程除外,主线程系统会自动为其创建Looper对象,开启消息循环。) Looper对象通过MessageQueue来存放消息和事件。一个线程只能有一个Looper,对应一个MessageQueue。
(2) 通常是通过Handler对象来与Looper进行交互的。Handler可看做是Looper的一个接口,用来向指定的Looper发送消息及定义处理方法。 默认情况下Handler会与其被定义时所在线程的Looper绑定,比如,Handler在主线程中定义,那么它是与主线程的Looper绑定。 mainHandler = new Handler() 等价于new Handler(Looper.myLooper()). Looper.myLooper():获取当前进程的looper对象,类似的 Looper.getMainLooper() 用于获取主线程的Looper对象。
(3) 在非主线程中直接new Handler() 会报如下的错误:
E/AndroidRuntime( 6173): Uncaught handler: thread Thread-8 exiting due to uncaught exception E/AndroidRuntime( 6173): java.lang.RuntimeException: Can’t create handler inside thread that has not called Looper.prepare()
原因是非主线程中默认没有创建Looper对象,需要先调用Looper.prepare()启用Looper。
(4) Looper.loop();
让Looper开始工作,从消息队列里取消息,处理消息。
注意:写在Looper.loop()之后的代码不会被执行,这个函数内部应该是一个循环,当调用mHandler.getLooper().quit()后,loop才会中止,其后的代码才能得以运行。
(5) 基于以上知识,可实现主线程给子线程(非主线程)发送消息。
15.线程的切换又是怎么回事?
那么 线程的切换又是怎么回事 呢?
很多人搞不懂这个原理,但是其实非常简单,我们将所涉及的方法调用栈画出来,如下:
Thread.foo(){
Looper.loop()
-> MessageQueue.next()
-> Message.target.dispatchMessage()
-> Handler.handleMessage()
}
显而易见,Handler.handleMessage() 所在的线程最终由调用 Looper.loop() 的线程所决定。
平时我们用的时候从异步线程发送消息到 Handler,这个 Handler 的 handleMessage() 方法是在主线程调用的,所以消息就从异步线程切换到了主线程。
16. Handler是如何实现线程之间的切换的
Handler是如何实现线程之间的切换的呢?例如现在有A、B两个线程,在A线程中有创建了handler,然后在B线程中调用handler发送一个message。
通过上面的分析我们可以知道,当在A线程中创建handler的时候,同时创建了MessageQueue与Looper,Looper在A线程中调用loop进入一个无限的for循环从MessageQueue中取消息,当B线程调用handler发送一个message的时候,会通过msg.target.dispatchMessage(msg);将message插入到handler对应的MessageQueue中,Looper发现有message插入到MessageQueue中,便取出message执行相应的逻辑,因为Looper.loop()是在A线程中启动的,所以则回到了A线程,达到了从B线程切换到A线程的目的。

小结:
1.Handler初始化之前,Looper必须初始化完成。UI线程之所以不用初始化,因为在ActivityThread已经初始化,其他子线程初始化Handler时,必须先调用Looper.prepare()。
2.通过Handler发送消息时,消息会回到Handler初始化的线程,而不一定是主线程。
3.使用ThreadLocal时,需要注意内存泄漏的问题。
通俗点的说法Handler机制其实就是借助共享变量来进行线程切换的.
妙用 Looper 机制
我们可以利用 Looper 的机制来帮助我们做一些事情:
- 将 Runnable post 到主线程执行;
- 利用 Looper 判断当前线程是否是主线程。
完整示例代码如下:
public final class MainThread {
private MainThread() {
}
private static final Handler HANDLER = new Handler(Looper.getMainLooper());
public static void run(@NonNull Runnable runnable) {
if (isMainThread()) {
runnable.run();
}else{
HANDLER.post(runnable);
}
}
public static boolean isMainThread() {
return Looper.myLooper() == Looper.getMainLooper();
}
}
能够省去不少样板代码。
先明确我们的问题:
- Handler 是如何与线程关联的?
- Handler 发出去的消息是谁管理的?
- 消息又是怎么回到 handleMessage() 方法的?
- 线程的切换是怎么回事?
回答:Handler 发送的消息由 MessageQueue 存储管理,并由 Loopler 负责回调消息到 handleMessage()。
线程的转换由 Looper 完成,handleMessage() 所在线程由 Looper.loop() 调用者所在线程决定。
10.Android为什么推荐使用SparseArray来替代HashMap?
SparseArray有两个优点:
1.避免了自动装箱(auto-boxing)
2.数据结构不会依赖于外部对象映射。我们知道HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置,存放的都是数组元素的引用,通过每个对象的hash值来映射对象。而SparseArray则是用数组数据结构来保存映射,然后通过折半查找来找到对象。但其实一般来说,SparseArray执行效率比HashMap要慢一点,因为查找需要折半查找,而添加删除则需要在数组中执行,而HashMap都是通过外部映射。但相对来说影响不大,最主要是SparseArray不需要开辟内存空间来额外存储外部映射,从而节省内存。
11.Glide缓存机制
12.Binder机制
13.内存泄漏
查找内存泄漏可以使用Android Studio 自带的AndroidProfiler工具或MAT,也可以使用Square产品的 LeakCanary.
14.类的初始化顺序依次是?
(静态变量、静态代码块)>(变量、代码块)>构造方法
15.Retrofit库的核心实现原理是什么?如果让你实现这个库的某些核心功能,你会考虑怎么去实现?
Retrofit主要是在create方法中采用 动态代理 模式(通过访问代理对象的方式来间接访问目标对象)实 现接口方法,这个过程构建了一个ServiceMethod对象,根据方法注解获取请求方式,参数类型和参数 注解拼接请求的链接,当一切都准备好之后会把数据添加到Retrofit的RequestBuilder中。然后当我们 主动发起网络请求的时候会调用okhttp发起网络请求,okhttp的配置包括请求方式,URL等在Retrofit 的RequestBuilder的build()方法中实现,并发起真正的网络请求。
16.ARouter路由原理:
ARouter维护了一个路由表Warehouse,其中保存着全部的模块跳转关系,ARouter路由跳转实际上还 是调用了startActivity的跳转,使用了原生的Framework机制,只是通过apt注解的形式制造出跳转规 则,并人为地拦截跳转和设置跳转条件。
17.Glide中的动态代理
代理模式的介绍
18.服务的两种启动方式和使用场景(两次都问到)
19. 内存抖动
Gc 引起卡顿+OOM,怎么优化
Gson反序列化导致产生大量对象
解决思考:对象池
20.LeakCanary原理
它的基本工作原理如下:
RefWatcher.watch() 创建一个 KeyedWeakReference 到要被监控的对象。
然后在后台线程检查引用是否被清除,如果没有,调用GC。
如果引用还是未被清除,把 heap 内存 dump 到 APP 对应的文件系统中的一个 .hprof 文件中。
在另外一个进程中的 HeapAnalyzerService 有一个 HeapAnalyzer 使用HAHA 解析这个文件。
得益于唯一的 reference key, HeapAnalyzer 找到 KeyedWeakReference,定位内存泄漏。
HeapAnalyzer 计算 到 GC roots 的最短强引用路径,并确定是否是泄漏。如果是的话,建立导致泄漏的引用链。
引用链传递到 APP 进程中的 DisplayLeakService, 并以通知的形式展示出来。
总的来说,LeakCanary有如下几个明显优点:
针对Android Activity组件完全自动化的内存泄漏检查。
可定制一些行为(dump文件和leaktrace对象的数量、自定义例外、分析结果的自定义处理等)。
集成到自己工程并使用的成本很低。
友好的界面展示和通知。
22.ArrayMap和HashMap的区别
HashMap和ArrayMap各自的优势
1.查找效率:
HashMap因为其根据hashcode的值直接算出index,所以其查找效率是随着数组长度增大而增加的。
ArrayMap使用的是二分法查找,所以当数组长度每增加一倍时,就需要多进行一次判断,效率下降。
所以对于Map数量比较大的情况下,推荐使用
2.扩容数量:
HashMap初始值16个长度,每次扩容的时候,直接申请双倍的数组空间。
ArrayMap每次扩容的时候,如果size长度大于8时申请size*1.5个长度,大于4小于8时申请8个,小于4时申请4个。这样比较ArrayMap其实是申请了更少的内存空间,但是扩容的频率会更高。
因此,如果当数据量比较大的时候,还是使用HashMap更合适,因为其扩容的次数要比ArrayMap少很多。
3.扩容效率:
HashMap每次扩容的时候时重新计算每个数组成员的位置,然后放到新的位置。
ArrayMap则是直接使用System.arraycopy。
所以效率上肯定是ArrayMap更占优势。这里需要说明一下,网上有一种传闻说因为ArrayMap使用System.arraycopy更省内存空间,这一点我真的没有看出来。arraycopy也是把老的数组的对象一个一个的赋给新的数组。当然效率上肯定arraycopy更高,因为是直接调用的c层的代码。
4.内存耗费:
以ArrayMap采用了一种独特的方式,能够重复的利用因为数据扩容而遗留下来的数组空间,方便下一个ArrayMap的使用。而HashMap没有这种设计。由于ArrayMap只缓存了长度是4和8的时候,所以如果频繁的使用到Map,而且数据量都比较小的时候,ArrayMap无疑是相当的节省内存的。
5.总结:
综上所述,数据量比较小,并且需要频繁的使用Map存储数据的时候,推荐使用ArrayMap。
而数据量比较大的时候,则推荐使用HashMap。
23.HashMap原理
数据结构和算法思考
1.为什么选择数组和链表结构?
①数组内存连续块分配,效率体现查询更快。HashMap中用作查找数组桶的位置,利用元素的key的hash值对数组长度取模得到。
②链表效率体现增加和删除。HashMap中链表是用来解决hash冲突,增删空间消耗平衡。
扩展:为什么不是ArrayList而是使用Node<K,V>[] tab?因为ArrayList的扩容机制是1.5倍扩容,而HashMap扩容是2的次幂。
2.HashMap出现线程问题
①多线程扩容,引起的死循环问题(jdk1.8中,死循环问题已经解决)。
②多线程put的时候可能导致元素丢失
③put非null元素后get出来的却是null
3.使用线程安全Map
①HashMap并不是线程安全,要实现线程安全可以用Collections.synchronizedMap(m)获取一个线程安全的HashMap。
②CurrentHashMap和HashTable是线程安全的。CurrentHashMap使用分段锁技术,要操作节点先获取段锁,在修改节点。
4.Android提倡使用ArrayMap
①ArrayMap数据结构是两个数组,一个存放hash值,另一个存放key和value。
②根据key的hash值利用二分查找在hash数组中找出index。
③根据index在key-value数组中对应位置查找,如果不相等认为冲突了,会以key为中心,分别上下展开,逐一查找。
优势,数据量少时(少于1000)相比HashMap更节省内存。劣势,删除和插入时效率要比HashMap要低。
kotlin协程的使用与原理
24.多线程间通信和多进程之间通信有什么不同,分别怎么实现?
1、进程间的通信方式
- 管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- 有名管道 (namedpipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 信号量(semophore ) : 信号量是一个计数器,可以用来控制多个进程对 共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其 他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的 同步手段。
- 消息队列( messagequeue ) : 消息队列是由消息的链表,存放在内核中 并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 信号 (sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个 事件已经发生。
- 共享内存(shared memory ) :共享内存就是映射一段能被其他进程所访问 的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是 最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。 它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
- 套接字(socket ) : 套解口也是一种进程间通信机制,与其他通信机制不同 的是,它可用于不同及其间的进程通信。
2 . 线程间的通信方式
- 锁机制:包括互斥锁、条件变量、读写锁互斥锁提供了以排他方式防止数据结构被并发修改的方法。读写锁允许多个线程同时读共享数据,而对写操作是互斥的。条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条 件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
- 信号量机制(Semaphore):包括无名线程信号量和命名线程信号量
- 信号机制(Signal):类似进程间的信号处理线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于 数据交换的通信机制。
25.为什么在子线程中创建 Handler 会抛异常
Handler 的工作是依赖于 Looper 的,而 Looper(与消息队列)又是属于某一 个线程(ThreadLocal 是线程内部的数据存储类,通过它可以在指定线程中存储 数据,其他线程则无法获取到),其他线程不能访问。因此 Handler 就是间接 跟线程是绑定在一起了。因此要使用 Handler 必须要保证 Handler 所创建的线 程中有 Looper 对象并且启动循环。因为子线程中默认是没有 Looper 的,所以 会报错。 正确的使用方法是:
public class WorkThread extends Thread {
private Handler mHander;
public Handler getHander() {
return mHander;
}
public void quit(){
mHander.getLooper().quit();
}
@Override
public void run() {
super.run();
//创建该线程对应的 Looper,
// 内部实现
// 1。new Looper()
// 2。将 1 步中的 lopper 放在 ThreadLocal 里,ThreadLocal 是保存数据的, 主要应用场景是:线程间数据互不影响的情况
// 3。在 1 步中的 Looper 的构造函数中 new MessageQueue();
//对消息机制不懂得同学可以查阅资料,网上很多也讲的很不错。
Looper.myLooper();
mHander = new Handler(){
@SuppressLint("HandlerLeak")
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
Log.d("WorkThread", (Looper.getMainLooper() == Looper.myLooper()) + "," + msg.what);
}
};
Looper.loop();
//注意这 3 个的顺序不能颠倒
Log.d("WorkThread", "end");
}
}26.谈谈Android的GC
Java 语言建立了垃圾收集机制,用以跟踪正在使用的对象和发现并回收不再 使用(引用)的对象。该机制可以有效防范动态内存分配中可能发生的两个危险: 因内存垃圾过多而引发的内存耗尽,以及不恰当的内存释放所造成的内存非法引用。
垃圾收集算法的核心思想是:对虚拟机可用内存空间,即堆空间中的对象进 行识别,如果对象正在被引用,那么称其为存活对象,反之,如果对象不再被引用,则为垃圾对象,可以回收其占据的空间,用于再分配。
垃圾收集算法的选择 和垃圾收集系统参数的合理调节直接影响着系统性能,因此需要开发人员做比较 深入的了解。
27.怎样保证App不被杀死?
强烈建议不要这么做,不仅仅从用户角度考虑,作为 Android 开发者也有责任去维护 Android 的生态环境。当然从可行性讲,谷歌也不会让容易的实现。同 时这样的 app 一般属于流氓应用
通常为了保证自己 app 避免被杀死,我们一般使用以下方法:
1.Service设置成START_STICKY,kill 后会被重启(等待5秒左右),重传Intent, 保持与重启前一样
2.通过 startForeground 将进程设置为前台进程,做前台服务,优先级和前台 应用一个级别,除非在系统内存非常缺,否则此进程不会被 kill
3…双进程 Service:让 2 个进程互相保护,其中一个 Service 被清理后,另外没 被清理的进程可以立即重启进程
4.QQ 黑科技:在应用退到后台后,另起一个只有 1 像素的页面停留在桌面上, 让自己保持前台状态,保护自己不被后台清理工具杀死
5.在已经 root 的设备下,修改相应的权限文件,将 App 伪装成系统级的应用 (Android4.0 系列的一个漏洞,已经确认可行)
6.Android 系统中当前进程(Process)fork 出来的子进程,被系统认为是两个不 同的进程。当父进程被杀死的时候,子进程仍然可以存活,并不受影响。鉴于目 前提到的在 Android-Service 层做双守护都会失败,我们可以 fork 出 c 进程多进程守护。死循环在那检查是否还存在,具体的思路如下(Android5.0 以下 可行):
- 1.用 C 编写守护进程(即子进程),守护进程做的事情就是循环检查目标进程是否 存在,不存在则启动它。
- 2.在 NDK 环境中将 1 中编写的 C 代码编译打包成可执行文件 (BUILD_EXECUTABLE)。
- 3.主进程启动时将守护进程放入私有目录下,赋予可执行权限,启动它即可。
7 联系厂商,加入白名单
28. 源码分析:Handler发送延时消息
总结:
handler发送延时消息是通过postDelayed()方法将Runnanle对象封装成Message,然后调用sendMessageAtTime(),设置的时间是当时的时间+延时的时间。
发送延时消息实际上是往messageQueue中加入一条Message。
Message在MessageQueue中实际是以单链表来存储的,且是按照时间顺序来插入的。时间顺序是以Message中的when属性来排序的。
重点:
postDelay并不是等待delayMillis延时时常后再加入消息队列,而是加入消息队列后阻塞(消息队列会按照阻塞时间排序)等待delayMillis后唤醒消息队列再执行。
sleep会阻塞线程
postDelayed不会阻塞线程
29.Android打包流程
熟悉Android打包编译的流程
- AAPT(Android Asset Packaging Tool)工具,Android资源打包工具。会打包资源文件(res文件夹下的文件),并生成R.java和resources.arsc文件。
- AIDL工具会将所有的.aidl文件编译成.java文件。
- JAVAC工具将R.java、AIDL接口生成的java文件、应用代码java文件编译成.class文件。
- dex脚本将很多.class文件转换打包成一个.dex文件。
- apkbuilder脚本将资源文件和.dex文件生成未签名的.apk文件。
- jarsigner对apk进行签名。
九、 面试自测题库
公司一
- 组件化和arouter原理
- recyclerview和listview区别
- glide流程,缓存前压缩,缓存命中
- APP性能优化,内存优化,布局优化,绘制优化,内存泄漏
- Http和Https区别
- socket心跳包
- jvm虚拟机,堆和栈的结构
- activity启动模式,有哪些不同
- stack栈的特点,自定义stack结构
- kotlin优劣势
公司二
- 自定义view,中英文字符串宽高测量显示,测量算法,可扩展性
- 事件分发机制
- Activity,view,window联系
- 热修复和插件化原理
- Synchronized底层原理,java锁机制
- java容器,hashmap和hashtable区别,hashmap原理,扩容流程,扰动算法的优势
- ArrayList和LinkendList区别,List泛型擦除, 为什么反射能够在ArrayList< String >中添加int类型
- Http和Https区别,SSL/TLS过程
- Android性能优化
- jvm虚拟机,堆和栈的结构,栈帧,JMM
- 组件化注意点,组件间通信机制
- 线程安全的单例模式有哪几种
- 熟悉的设计模式
公司三
- MVC,MVP,MVVM
- Activity和fragment生命周期区别,fragment正常添加和viewpager添加的区别,fragment懒加载原理,FragmentPagerAdapter 和 FragmentStatePagerAdapter
- 热修复和插件化
- 友盟bug统计,混淆后怎么定位bug。没接入热修复的APP中,上线后遇到bug怎么解决
- view绘制原理 (可以先说下基本view绘制,然后再说下屏幕刷新机制)
- 使用Analyze减少APK体积,原理
- Android 版本差异
公司四
- 基础类型字节,汉字占几个字节,线程和进程
- 四大组件,fileprovider和Contentprovide区别,activity启动流程
- MVC,MVP,MVVM
- TCP三次握手,四次挥手
- Eventbus,glide原理
- 性能优化,内存抖动,内存泄漏,内存溢出,handler机制,IntentService和handlerThread,子线程更新view内容的方法
- GC回收算法
- recyclerview和listview区别
- 组件化,模块化,插件化,热修复
- 工作中遇到的难题怎么解决的
- Kotlin Java优缺点,kotlin什么时候用分号,run,with,apply,内联函数,高阶函数
- APK体积优化
- 进程间通信
- 单例模式,哪些是安全的
- retrofit设计模式
- 自定义view
- 是否做过音视频和IM?
- APK性能优化
- CurrentHashMap1.7和1.8区别
- volatile关键字的作用,怎么保证原子性呢?
- 网络优化
- 对新技术的看法
- java泛型,协变和逆变
公司五
- HTTPS具体步骤
- 常用的设计模式,代理模式和装饰者模式区别
- 服务端返回错误的json数据,客户端怎么自定义model,避免出错
- Hook技术
- kotlin了解,协程
- 屏幕适配
- 抓包工具使用和原理
- 网络优化
- 未来期望,对公司的了解
- Okhttp,rxjava,glide,retrofit等原理,okhttp底层数据传输原理,http报文体结构
- APK体积优化
- Android jetpack使用和原理,新技术看法
- crashHandler获取应用crash信息
- recyclerview和listview缓存区别
- Android 常见崩溃问题分析及一般的解决方案
- NestedScrollView触摸机制,AOP相关知识
- 设计APP,整体架构选型
- Android沙盒和底层Linux通信
- ACTION_CANCLE什么时候触发
- 线程池原理
公司六
- 组件化,arouter,组件化UI,还有哪些路由框架。AS调试方法
- MVC,MVP,MVVM,Jetpack
- JVM,JMM,java加载对象的步骤,classLoader,GC回收算法
- 插件化和热修复
- 唯一安卓ID,安卓安全的知识,加密算法,判断activity前台进程
- TCP三次握手和四次挥手
- hash算法,hashmap,怎么解决hash冲突
- 加载大图,glide缓存机制,设计模式,双重检测的单例模式为什么要检查两次,自己设计图片加载框架思路
- 启动未注册的Activity
- AOP,蓝牙开发,IOT
- glide缓存清除:lrucache算法
- glide缓存文件太大,查找效率慢怎么优化?glide下载高清图片优化
- 最近研究的技术,遇到最难的事,对公司的期望
公司七
- 组件化, arouter优缺点
- MVC,MVP,MVVM
- 项目中的亮点,对架构的理解
- handler原理及相关知识点,message回收策略
- hashmap原理,arraymap原理,对比性能。
- hashmap为什么大于8才转化为红黑树,加载因子为什么是0.75
- Synchronized底层原理,java锁机制
- 服务和广播
- activity启动模式(给例子具体分析,A(标准)-》B(单例)-》C(singleTop)-》D(singleTask),分析有几个栈,每个栈内的activity)
- 常用设计模式,线程安全的单例模式
公司八
- static、final;继承与多态
- 组件化, arouter优缺点
- context相关知识点
- handler原理及相关知识点,handler缓存池大小。
- 性能优化,启动速度优化,架构
- java虚拟机与Dalvik和ART区别
- Kotlin协程,扩展函数和属性以及伴生对象
- 电商APP的首页,怎么设计一个APP架构
- MVP中数据请求为什么要和M一起,答:网络请求和javabean都是数据模型相关
- Glide的存储EngineKey是怎么保证唯一的。面试官答:有个队列会将EngineKey存储起来,每次生成后进行对比存储。这个我在源码中没找对位置,如果知道的同学,麻烦帮忙解释下。
- retrofit是怎么将service接口转化为我们需要的javabean的?
- 怎么做管理,新技术学习
公司九
- SqLite与contentProvider区别
- fragment周期,两个fragment切换周期变化,fragment通信
- https证书校验 ,加密相关,网络请求框架
- glide加载流程,大图显示,图片大小计算
- view绘制(从onSync()开始)
- 线程内存模型,线程间通信
- 获取view的宽高,更新view的方式,主线程消息机制
- OOM,内存泄漏,内存溢出,java引用类型,ANR分析
- APP性能优化,webview相关,webview优化,webview中Android与js互调
- 插件化和热修复
十二、 总结
简历上写的东西,一定要先搞懂,特别是简历上的 专业技能 。如果面试未通过,基础上可以归结为:基础知识不够扎实,技术深度不够。深度和广度是永远的考虑点。工作上了一定的年限,在面试时也得注意一下基础。对数据结构与算法来说,基础的数据结构的考查不会停止,对资深的要求岗位,对项目上的性能和效率工具的全面考查更是 巨大的考验。
平时工作是多做总结是必要的,对常用的技术和难点有意识做总结,在总结时同时查阅相应的资料有助于深度思考。
希望大家在和面试官PK时,都有自己的看法和态度。
珍惜每 一次和对面试官交流,都将是对自己技术的一次梳理。
最后在这里小编分享一份大佬收录整理的Android学习PDF+架构视频+源码笔记,高级架构技术进阶脑图、Android开发面试专题资料,高级进阶架构资料
这些都是我现在闲暇还会反复翻阅的精品资料。里面对近几年的大厂面试高频知识点都有详细的讲解。相信可以有效的帮助大家掌握知识、理解原理。
当然你也可以拿去查漏补缺,提升自身的竞争力。
相信它会给大家带来很多收获。如果你有需要的话,可以点击获取!
喜欢本文的话,不妨顺手给我点个赞、评论区留言或者转发支持一下呗~