全文共4925字,预计学习时长13分钟

图源:unsplash
本文中,笔者将分享如何开发一个语音输入情感识别系统,并使用对比预测编码(CPC)训练的自我监督演示提升性能。使用CPC时,结果准确性从基线的71%提高到80%。这是显著的相对减低率,误差在30%。
此外,笔者对使用这些演示训练模型的各种体系结构进行了基准测试,包括简单多层感知器(MLPs)、递归神经网络(RNNs)和使用扩展卷积的WaveNet类型模型。
笔者发现,使用预先训练的CPC演示作为输入特征的双向RNN模型是最高性能的设置,在RAVDESS数据库集中分类八种情绪时,其帧精度达到79.6%。据笔者所知,与接受过这方面培训的其他系统相比,此系统十分具有竞争力。

引言
语音情感识别包括从快乐、忧伤、愤怒等一系列组别中预测情感,在电话服务中心、医疗保健和人力资源等业务中有许多潜在的应用。例如,在电话服务中心,可以自动发现潜在客户的情绪,引导销售代表采取更好的销售方式。
通过音频预测情绪是很有挑战性的,因为不同的人对情绪的感知不同,并且往往很难解释。此外,许多情感线索来自与言语无关的领域,如面部表情、特定心态和互动背景。做出最终判断之前,我们会自然而然考虑所有这些信号以及我们过去的交流经验。
一些研究者使用音频结合文本或音频结合视频的多模式方法来提升性能。理想情况下,会训练理解这些领域和社会互动之间联系的世界模型来完成这项任务。然而,这是一个进行中的研究领域,目前还不清楚如何从社会互动中学习,而不仅仅是从数据本身研究趋势。在此实验中,我通过使用对比预测编码框架的自我监督演示表示训练代替多模式训练来提高性能。
在语音表征学习领域,语音识别和说话人识别分别对语音中的局部结构和全局结构进行评估,因此被广泛应用于评估自监督学习技术产生的特征。本文证明了情感识别可以作为下游任务衡量演示质量。此外,对情绪进行分类补充了电话和说话者的识别,因为情绪在很大程度上只取决于说话内容或声音效果。
情感识别
大多数情感识别系统使用梅尔频率倒谱系数(MFCCs)进行训练,该系数是基于频谱图的流行音频特征。Fbanks,也称Mel波谱图,与MFCCs类似,应用广泛。两者都捕捉人类敏感的频率内容。
情感识别任务中,通过自我监督学习来使用机器学习的特征时,很少有工作显示出性能的提高。值得注意的是,MFCCs和Fbanks仍然可以用作自我监督任务的输入,而不是原始音频,并且在提取更丰富演示时通常是一个很好的起点。
自我监督学习
有多种自我监督的语音技术。自我监督学习是“无监督的”,利用数据的固有结构生成标签。其动机是能够在互联网上使用大量未标记的音频数据,以类似于语言模型从未标记文本数据中学习的方式生成一般演示。
理想情况下,与完全监督的方法相比,这导致在下游任务中获得相同性能所需的人工标记数据更少。较少人为标记的数据意味着,例如,公司可以避免使用昂贵的转录器获得自动语音识别(ASR)的准确音频转录。
单纯依靠监督学习有特定任务解决方案的危险,在这种情况下,模型可能难以在不同的领域(如电视广播和电话)或不同的噪声环境中进行推广。此外,监督学习倾向于忽略音频丰富的底层结构,这正是自我监督学习的优势所在。
自我监督学习有两种主要形式:
· 生成式——专注于最小化重建误差,因此,在输出空间测算损耗。
· 对比式——致力于从一组对应不同音频片段的干扰物中挑选出一个阳性样本。在演示空间中测算损耗。
热门的生成式自我监督方法是自回归预测编码(APC)。一旦原始音频转换为Fbanks,任务就是在给定时间步长之前的特征的情况下预测未来的特征向量N个时间步长,其中范围1≤N≤10演示良好。
过去的语境由递归神经网络(RNN)或变换器总结,并且激活最终层后将用于演示。损失是相对于参考值的均方误差。近期增加了矢量量化层,以进一步改善电话/说话人的识别结果。
CPC式对比自我监督学习的一种形式,也是本文使用的一种。将原始数据编码到潜在空间,在此空间中对正负样本进行恰当分类。此处损耗名为InfoNCE。下一节将对产品总分类进行更详细地概述。其他热门方法包括动量对比(MoCo)和问题不可知的语音编码器。后者利用情绪识别推动演示的相关信息。
对比预测编码
图1给出了产品总分类的概述,本节描述其运行方式。笔者提供了PyTorch代码的截图进行说明——所示代码与项目库中给出的完整代码相比有所简化。
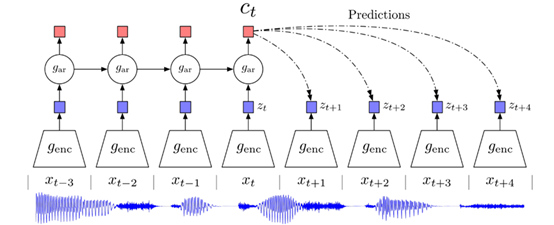
图1:CPC作为音频代表性学习方法的概述。
首先,原始音频样本x在16kHz时通过编码器(g_enc),该编码器使用多个卷积层对音频进行160倍的下采样。因此,编码器的输出频率是100Hz。或者,编码器可以替换为多层感知器,该多层感知器对已经处于100赫兹的Fbank特征进行操作。本实验涉及到第二种方式,因为笔者发现当将所学的功能用于下游任务时,性能会略有提高。
潜在空间中编码器的输出z被传送到自回归模型g_ar(例如RNN)中。该阶段在每一时间步长输出c,结合所有先前延迟的信息。图2中的正向方法说明了PyTorch中如何实现这一步。
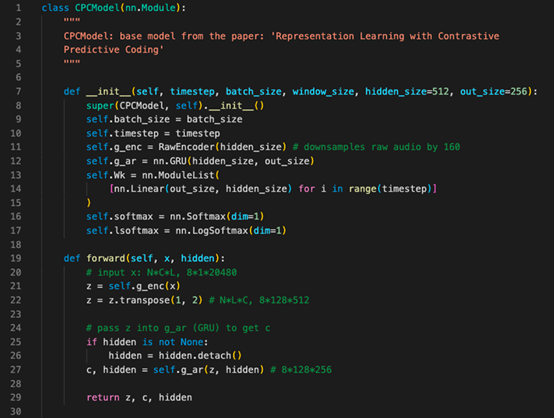
图2:CPC模型的初始化和传递。
现在,在一个特定的时间步长t,应用c的线性变换和预测的前方距离相关的权重矩阵(如图1中的虚线和图3中第36行的代码所示)。接下来,将这些线性变换乘以实际的未来潜在z,得到对数密度比。密度比由以下等式定义:
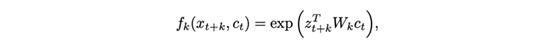
Softmax层应用于正样本和许多负样本的对数密度比,以增加阳性样本的概率,换言之,能够理解阳性潜在样本历史相关性最强,重复k次,如图3中每个时间步长上的循环所示“训练目标要求在一组干扰物中识别出正确的量化潜在语音演示。”
CPC中的损失就是下述等式中的InfoNCE,它与正确分类阳性样本的分类交叉熵相同。
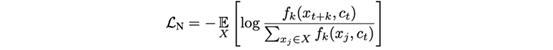
实际上,损失是对批次内阳性样本的对数概率求和计算得出(图3中的第57行)。损失最大化时,编码器、RNN矩阵和权重矩阵采取并行训练。
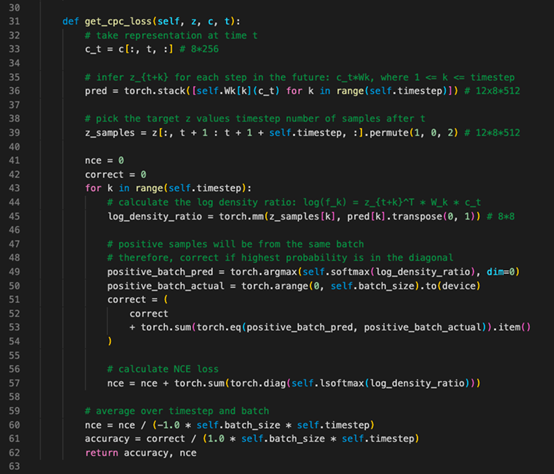
图3:在给定z和c的情况下,计算NCE损耗的图示。
图4代码展现了初始化模型中数据传递方式,以及在序列中多次计算InfoNCE。需要理解的是,可以从序列中时间“t”的循环进行预测,也可以预测时间步长“k”的数量。
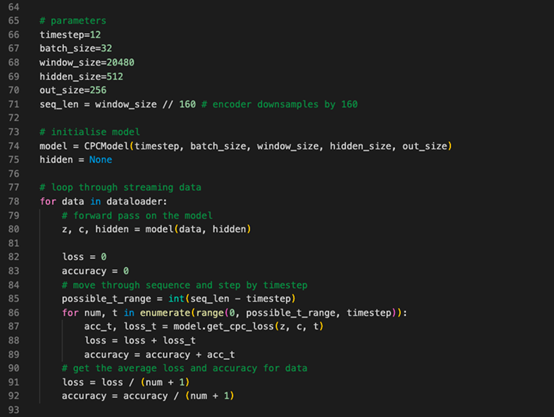
图4:通过模型传递数据并计算最终损失
数据集
CPC预训练是在100小时的Librispeech数据集子集上进行的,该数据集由16千赫英语语音组成。
用于情感识别任务的数据集名为“瑞尔森情感语音和歌曲视听数据库”(RAVDESS)。笔者的研究中只考虑语音数据集。该数据集由24位演讲者组成,男女演员比例均等。用八种情绪读出特定的句子,即:中性、平静、快乐、悲伤、愤怒、恐惧、惊讶和厌恶。
笔者选择在验证集和测试集之间平均分配最后两个演员。此外,音频文件是从其他演员中随机选择并添加的,以确保80%的数据用于训练集,实现经典的80:10:10分割。本次研究中,笔者忠实于原始数据,因此训练模型以分类八种情绪。
方法
· CPC系统
标准的80维Fbanks作为输入特征,通过一个隐藏大小为512的3层MLP编码器、批量标准和ReLU激活。特征编码器(z)的输出通过输出大小为256的单个GRU层馈送,生成上下文特征向量(c),用于展示训练情绪识别模型。
CPC系统的训练窗口大小为128(相当于1.28秒,因为Fbanks为100赫兹),批量大小为64和50万步。这相当于图书馆100小时数据集的114个纪元左右。RAdam优化器在余弦退火到1e-6之前的前三分之二的训练中,以4e-4的平坦学习率使用。使用了未来12个时间步长的总范围(k),因为其显示出CPC任务中区分阳性样本和阴性样本的最高准确性。
· 情感识别系统
此外,为了研究演示的可访问性,以及提升系统的性能,笔者使用了多种情感识别模型的体系结构。下面的列表给出了所使用的7种架构的更多细节,所有模型都已对输入特征应用全球标准化。
· 线性—单一线性层。
· MLP-2—2块多层感知器。每块包含一个线性层(隐藏大小为1024)、批处理范数、ReLU激活和丢失(概率 0.1)。
· MLP-4—同上,但有4块。
· RNN(单向)—2层,非双向,隐藏尺寸512,丢失概率0.1。
· 卷积—带6个卷积层,ReLU激活,丢失概率0.1和最大池层。
· 波网—扩张的卷积结构,呈指数增长。超参数隐藏大小64,膨胀深度6,重复次数5,内核大小2。
· RNN(双向)—与RNN相同,但是双向的。
模型以1024(10.24秒)的窗口大小,8批量大小和总共40k个步骤进行训练。框架式交叉熵损失用于八种情绪。与CPC训练相比,优化器和学习速率保持不变,但是,学习速率计划被关闭。笔者分析过程中,使用了无CPC预训练的基线情绪识别模型,该模型以Fbanks作为特征向量进行比较。
结果
· CPC的影响
在自我监督的学习文献中,经常使用线性架构来说明演示的可获得性。本项研究中,笔者想说明,更复杂的结构也有提升空间,例如具有扩展卷积的WaveNet样式模型或双向RNN。表1显示了每种推荐架构使用Fbanks和CPC特性时的帧精度。在每种情况下,CPC特征在对语音中的情感进行分类时都会提升准确性,而与架构无关。相对误差平均下降21.7%,换句话说,消灭了超过五分之一的错误。
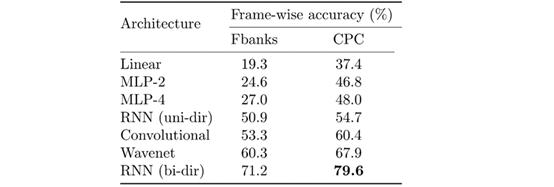
表1:使用CPC特征而不是Fbanks时,各种模型架构从RAVDESS数据集对八种情绪进行分类的帧级准确性。
值得注意的是,由于CPC演示比Fbanks具有更大的特征维数,以CPC训练的情感识别模型具有更高的参数计数。然而,运行了一些匹配参数计数的测试后,笔者发现Fbanks依然存在被超越的趋势,并且差距只缩小了一小部分。
· 架构的影响
表1中表现最差的三个模型没有利用跨时间的信息——试图在只给出一帧图像的情况下对情绪进行分类。使用单向RNN或卷积层的模型可以考虑额外语境,这会产生很大的不同,尤其是在使用Fbanks时。
与普通的卷积模型相比,WaveNet风格的模型具有更大的感受空间,这进一步提高了性能。原因之一可能是它可以展望未来,因为卷积不经掩蔽。与WaveNet模型类似,双向RNN可以使用来自未来的语境,并且当与CPC特征结合时,该架构可展现情感识别性能。RAVDESS测试集中,帧级精度为79.6%。据笔者所知,在对所有八种情绪进行分类的测试中,这是这项任务的最新技术。
· 个人情绪
表2显示了测试集中分类的每种情绪的框架式F1分数。这种模式最擅于识别声音中带有厌恶和惊讶情绪的演员,快乐和中立是其表现最差的情感。这可能是因为后者表达能力较低,模型难以分类。

表2:通过RNN(双向)模型获得的RAVDESS数据集中每种情绪的F1分数 · 今后工作
未来的工作可能包括用变压器替换CPC系统中的RNN。笔者能够借此扩大产品总分类模型,并利用来自Librispeech以外来源的更多未标记数据。此外,可以将数据强化添加到情感识别数据中,以提高数据质量,并进一步改善结果。
自我监督学习,如CPC,可以用来显著减少语音情感识别领域的误差。笔者实验中测试了各种架构,发现双向RNN——可以利用未来的环境——实现最佳性能模型。

图源:unsplash
这研究有助于对使用CPC训练的语音演示进行基准测试和改进,以及在对多种情绪进行分类时提高性能。这一切令人兴奋,它为能够更可靠地预测说话者情绪的系统提供了构建模块。例如,这可以显著提高电话服务中心分析工具的质量,这些工具用于帮助代理提高技能并改善客户体验。

一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)