距离国庆假期还有3天,作为一年里难得的长假,你肯定不想白白浪费,得给自己安排一次愉快的远行。但是去哪里玩成了头大的事情,瞬间想到小红书(https://www.xiaohongshu.com/),号称拥有超过一亿用户的生活方式分享社区,其用户笔记内容涵盖吃穿玩乐买,涉及时尚、护肤、彩妆、美食、旅行、影视、读书、健身等各个生活方式领域,再加上社区每天产生数十亿次的笔记曝光,正如客户所言,其平台是集social和commerce于一体的,其数据价值可想而知。
-----难度指数 ✩✩
-----阅读本文大概需20分钟
爬虫案例100篇栏目的第二篇

开始抓包
由于小红书web版关闭了,我们只好从微信小程序入手。
打开小程序搜索“国庆旅游”关键词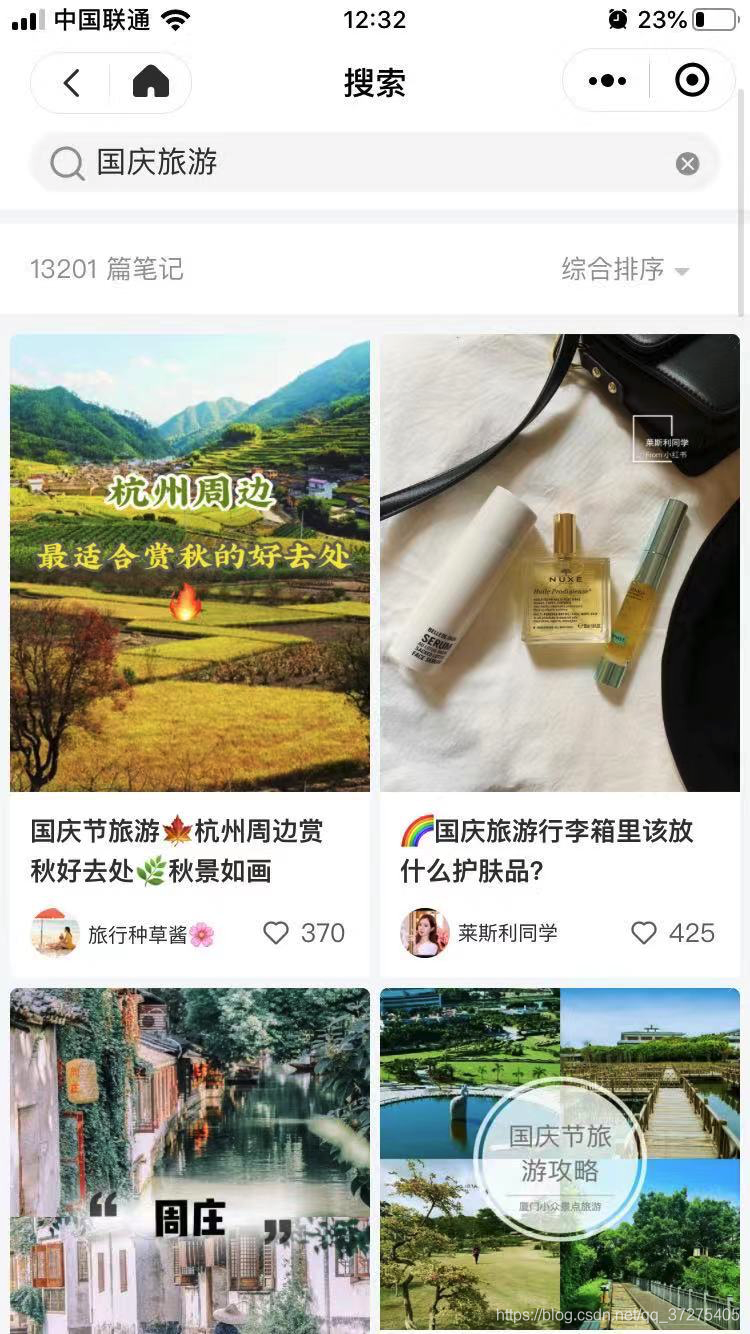
打开charles开始抓包,搜索“国庆节旅游”,也就是小红书搜索结果的第一条标题。
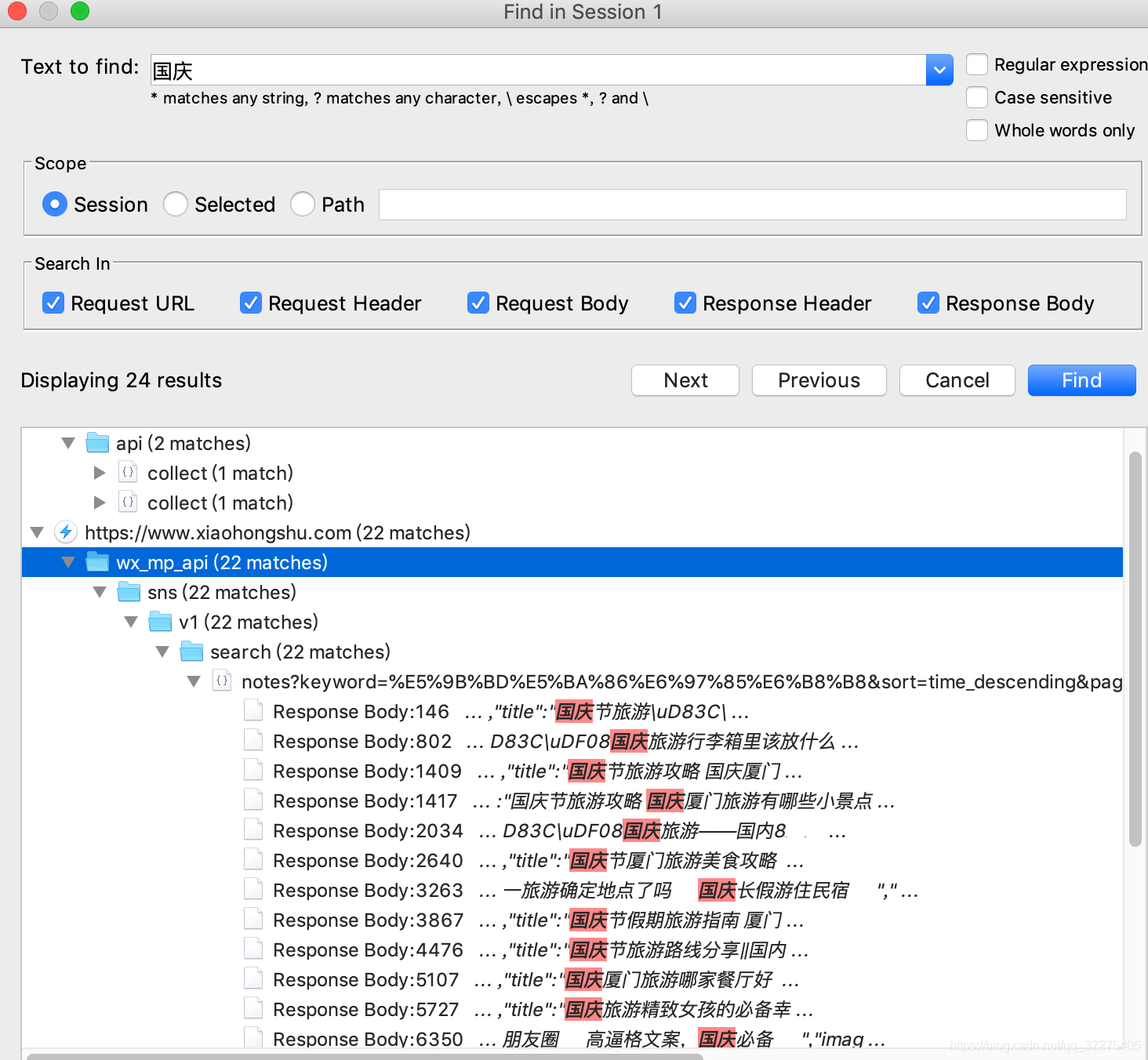
找到了!就是这个请求;看了一下是一个get请求,复制链接输入到浏览器中提示登陆已过期。嗯~,打开pycharm,写了一个简单带headers的requests请求发现数据获取到了。

大致调试了一下请求头,是authorization在控制是否登陆过期。所以请求的时候记得带上它哦
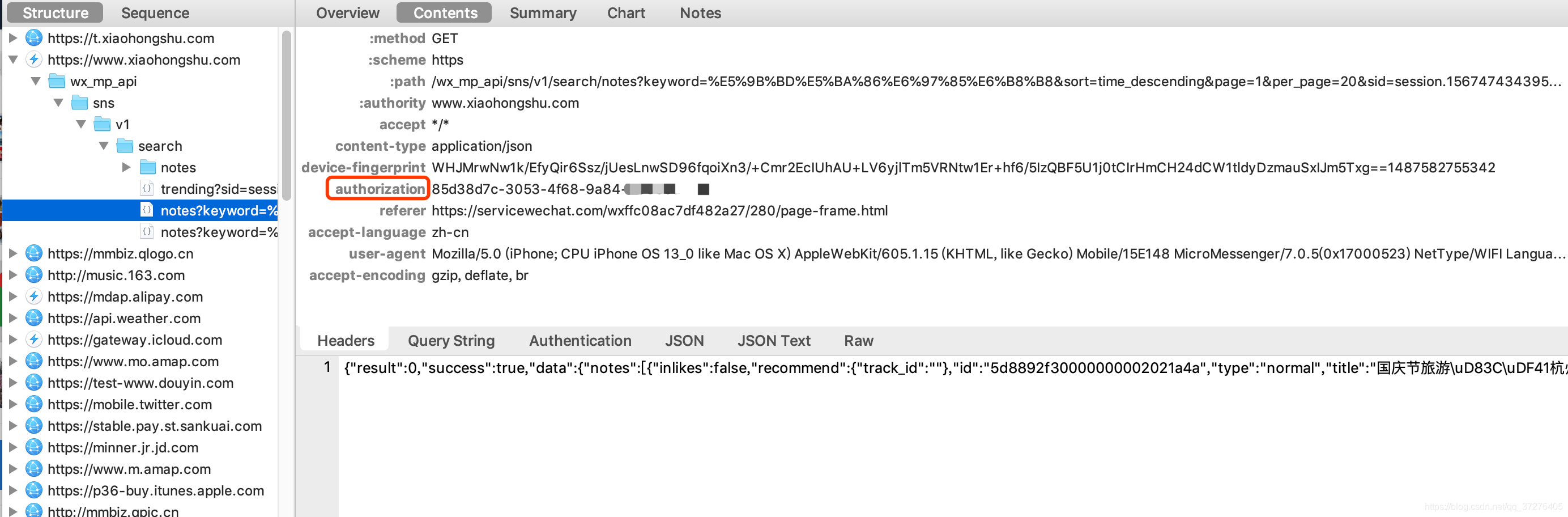
获取列表也的代码(由于小红书比较谨慎,所以只能看到50页数据):
def get_list(url, page):
'''
获取列表页
'''
# 1:按热度排序 2:按时间排序 3:综合排序
sort = {
"1": "popularity_descending", "2": "time_descending", "3": "general"}
for page in range(25, 51):
url = 'https://www.xiaohongshu.com/wx_mp_api/sns/v1/search/notes?keyword={}&sort={}&page={}&per_page=30&sid=session.1567474343950544022616'.format(
keyword, sort["1"], page)
authorization = 'you authorization'
head = {
"accept": "*/*",
"content-type": "application/json",
"device-fingerprint": "WC39ZUyXRgdFrJLIl36pz6dYNcrGscYZZWqJlPTC2v9Zkrt3jCwWKSyDu9wYQhprJgZD8KTs1jiM0/jeT0GYQI+Xx06PQ2kgctL/WmrP2Tauiuo9Z2Nzm4Q==1487577677129",
"authorization": authorization,
"referer": "https://servicewechat.com/wxffc08ac7df482a27/270/page-frame.html",
"accept-language": "zh-cn",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 12_3_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.5(0x17000523) NetType/WIFI Language/zh_CN",
"accept-encoding": "br, gzip, deflate"
}
return requests.get(url, headers=head).json()
列表页json中没有带每条笔记的content,只有一个ID。通过分析发现了另一个API接口。

将这个ID换掉你想获取的笔记的ID就大功告成了,记得带上headers哦
获取content代码:
def get_content(info):
'''
:param info:列表页的单条数据
:return: 加入content后的item
'''
head = {
"accept": "*/*",
"content-type": "application/json",
"device-fingerprint": "WC39ZUyXRgdFrJLIl36pz6dYNcrGscYZZWqJlPTC2v9Zkrt3jCwWKSyDu9wYQhprJgZD8KTs1jiM0/jeT0GYQI+Xx06PQ2kgctL/WmrP2Tauiuo9Z2Nzm4Q==1487577677129",
"authorization": authorization,
"referer": "https://servicewechat.com/wxffc08ac7df482a27/270/page-frame.html",
"accept-language": "zh-cn",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 12_3_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.5(0x17000523) NetType/WIFI Language/zh_CN",
"accept-encoding": "br, gzip, deflate"
}
info_url = 'https://www.xiaohongshu.com/wx_mp_api/sns/v1/note/{}/single_feed?sid=session.1567474343950544022616'.format(info['id'])
return requests.get(info_url, headers=head).json()
抓取处理完的数据
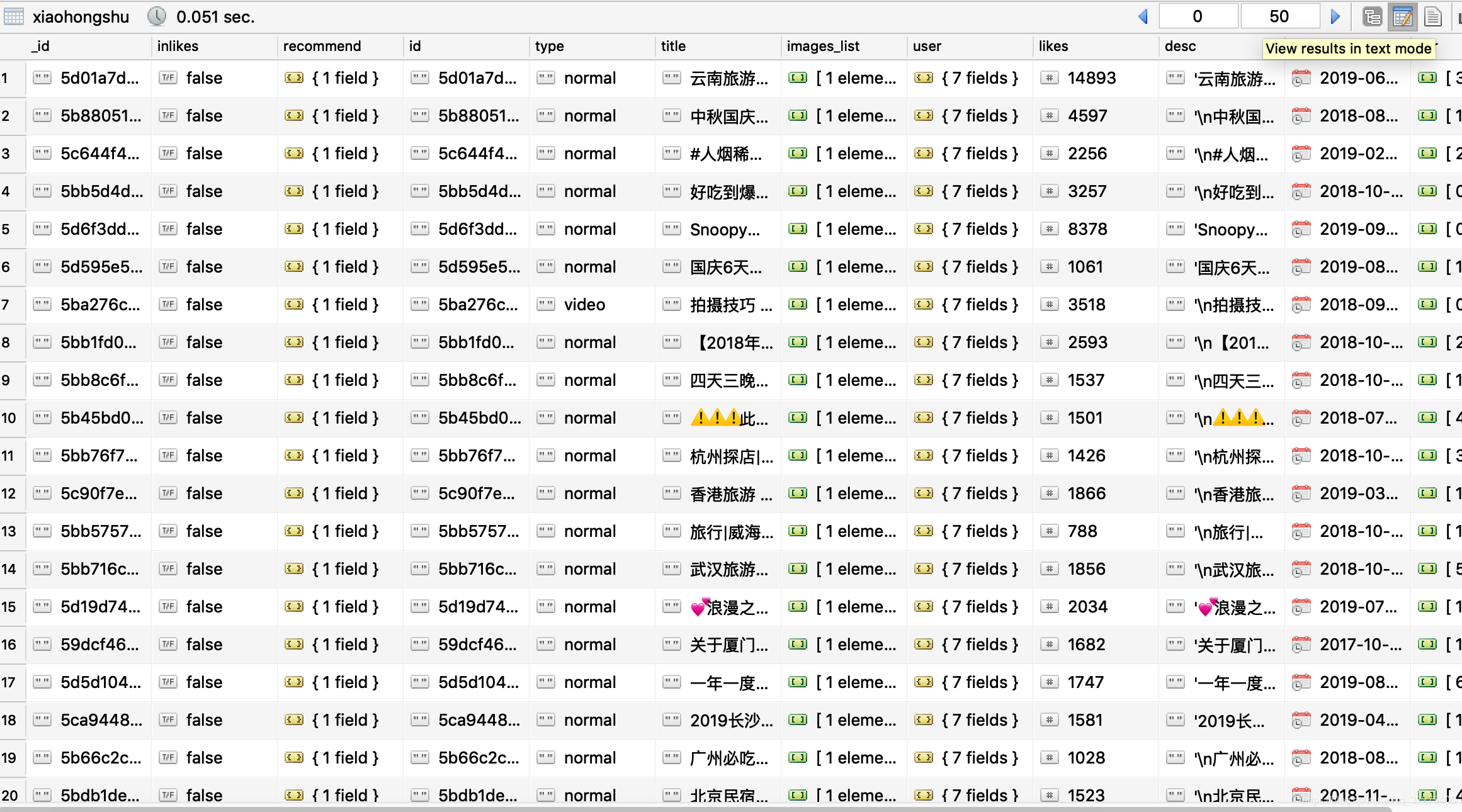
源代码:
import requests
import pymongo
from multiprocessing.dummy import Pool as mp
import datetime
db = pymongo.MongoClient()['ceis_nlp']['xiaohongshu']
def get_list(url, page):
'''
获取列表页
'''
return requests.get(url, headers=head).json()
def save_mongo(item):
'''
:param item:需要保存的item
:return: 保存数据
'''
try:
res = db.save(item)
print(res)
except:
print('重复!')
def get_content(info):
'''
:param info:列表页的单条数据
:return: 加入content后的item
'''
info_url = 'https://www.xiaohongshu.com/wx_mp_api/sns/v1/note/{}/single_feed?sid=session.1567474343950544022616'.format(info['id'])
content_data = requests.get(info_url, headers=head).json()
info['desc'] = repr(content_data['data'][0]['note_list'][0]['desc'])
info['time'] = datetime.datetime.fromtimestamp(content_data['data'][0]['note_list'][0]['time'])
info["_id"] = info["id"]
save_mongo(info)
def read_data(listpage_json):
'''
:param listpage_json:列表页的json数据
:return: 单条详情数据
'''
info_data = listpage_json['data']['notes']
for info in info_data:
get_content(info)
def main(url, page):
print(page)
read_data(get_list(url, page))
if __name__ == '__main__':
authorization = '19bc4862-d820-481e-b83d-******'
head = {
"accept": "*/*",
"content-type": "application/json",
"device-fingerprint": "WC39ZUyXRgdFrJLIl36pz6dYNcrGscYZZWqJlPTC2v9Zkrt3jCwWKSyDu9wYQhprJgZD8KTs1jiM0/jeT0GYQI+Xx06PQ2kgctL/WmrP2Tauiuo9Z2Nzm4Q==1487577677129",
"authorization": authorization,
"referer": "https://servicewechat.com/wxffc08ac7df482a27/270/page-frame.html",
"accept-language": "zh-cn",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 12_3_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.5(0x17000523) NetType/WIFI Language/zh_CN",
"accept-encoding": "br, gzip, deflate"
}
pools = mp(16)
keyword = '国庆旅游'
# 1:按热度排序 2:按时间排序 3:综合排序
sort = {
"1": "popularity_descending", "2": "time_descending", "3": "general"}
for page in range(25, 51):
url = 'https://www.xiaohongshu.com/wx_mp_api/sns/v1/search/notes?keyword={}&sort={}&page={}&per_page=30&sid=session.1567474343950544022616'.format(keyword, sort["1"], page)
pools.apply_async(main, args=(url, page,))
# main(url, page)
pools.close()
pools.join()
统计分析
数据获取到了,接下来就是分析。数据不用起来就是费数据对吧~
我首先把获取的desc进行了命名实体识别(NER),没有自己写而是调用百度的句法分析API。

有了这个结果,就剩统计了。通过pandas三两下就出结果了。
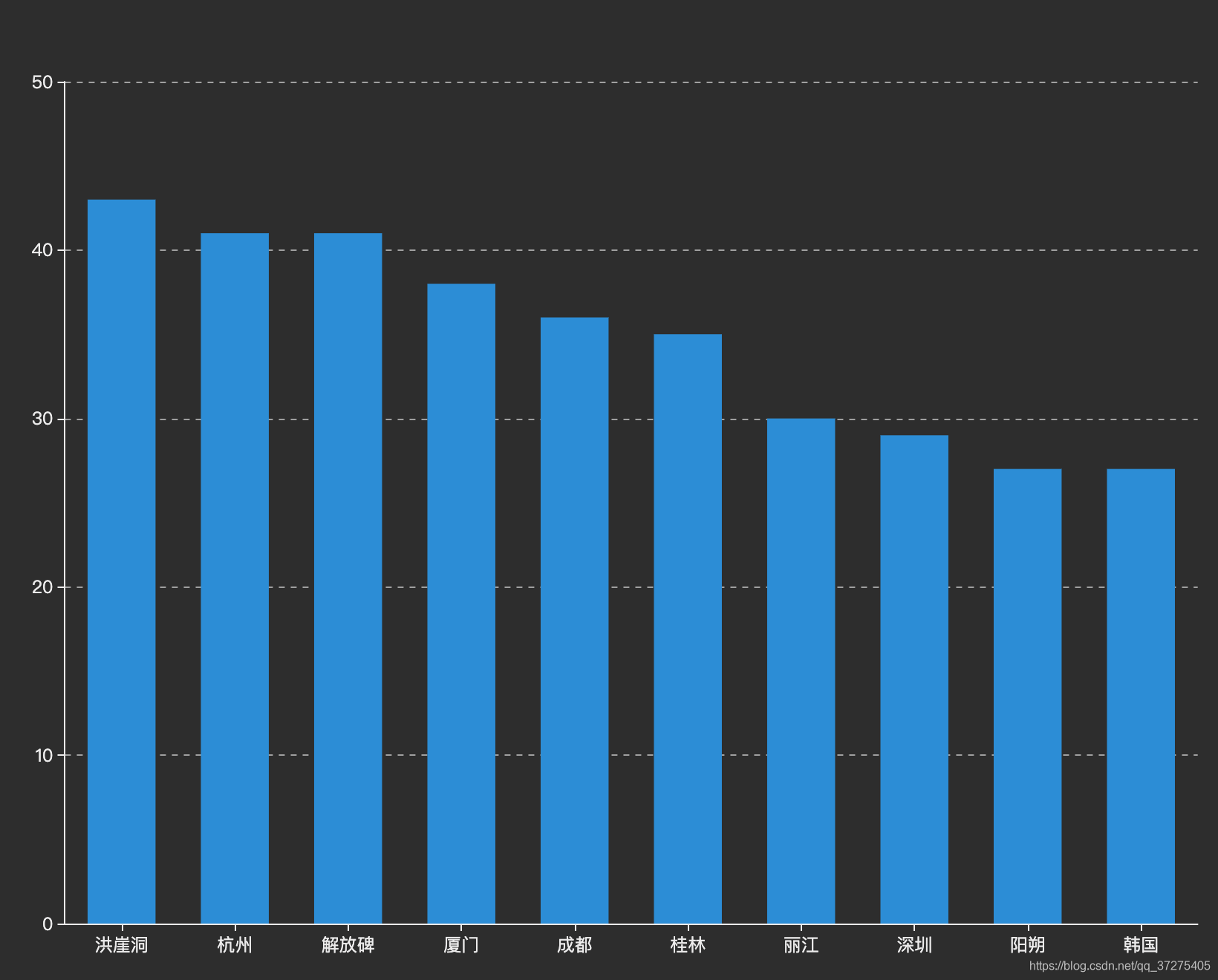
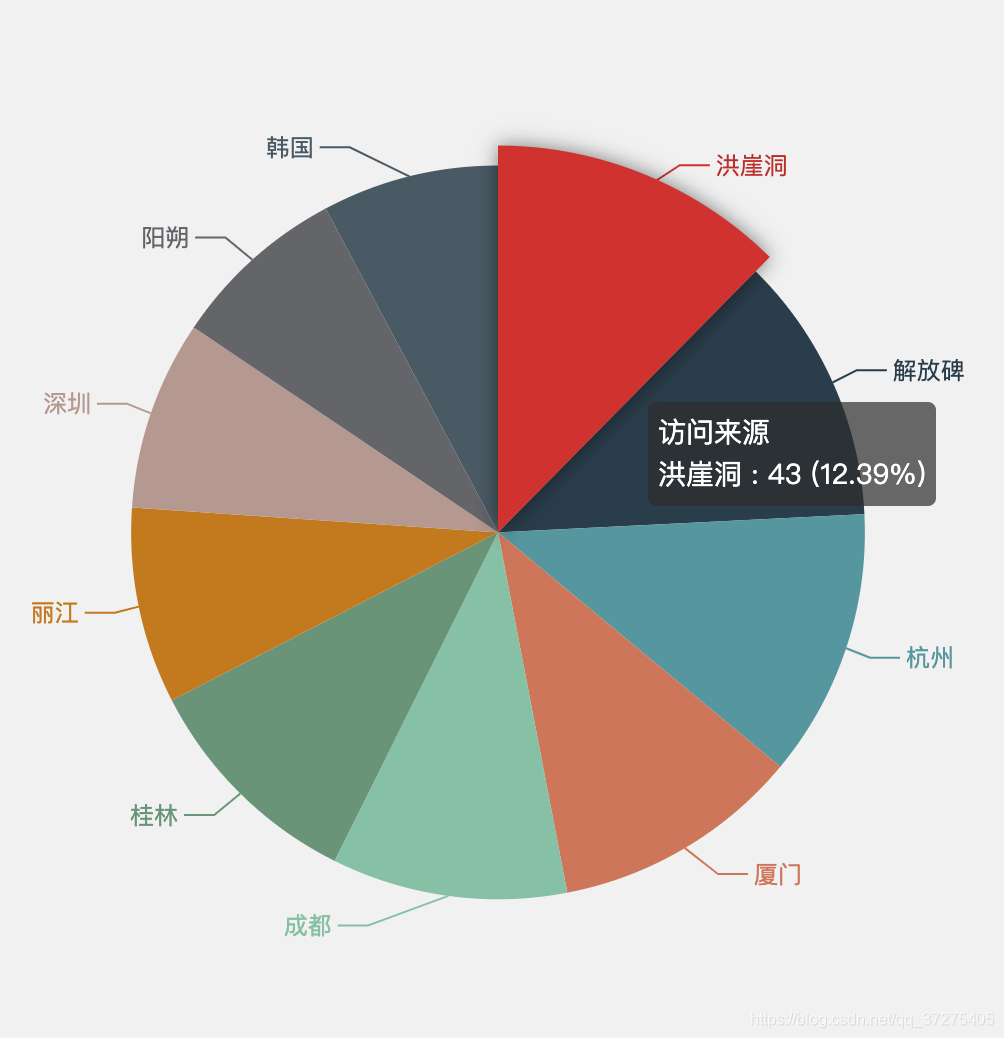

从统计结果中我们可以看出最热的景点是洪崖洞。最热的城市是重庆。
你是不是以为到这里这篇文章就结束了。
对没错~你猜对了。
