自然语言具有广泛的语法结构,使用第八章中描述的简单方法很难处理。为了获得更大的灵活性,我们改变了对S,NP和V等语法范畴的处理。代替原子标签,我们将它们分解为像字典这样的结构,其中的特征可以采用一系列值。为了获得更大的灵活性,我们改变了对S,NP和V等语法范畴的处理。代替原子标签,我们将它们分解为像字典这样的结构,其中的特征可以采用一系列值。
本章的目标是回答以下问题:
我们如何扩展具有特征的上下文无关语法框架,以便对语法类别和制作进行更细粒度的控制?
特征结构的主要形式属性是什么?我们如何在计算中使用它们?
我们现在可以使用基于特征的语法捕获哪些语言模式和语法结构?
在此过程中,我们将涵盖更多英语语法主题,包括一致性,子分类和无界依赖构造等现象。
9.1语法特征
我们描述了如何构建依赖于检测文本特征的分类器。这些功能可能非常简单,例如提取单词的最后一个字母,或更复杂,例如,由分类器自己预测的词性标签。在本章中,我们将研究特征在构建基于规则的语法中的作用。特征提取器可以记录自动检测到的特征,与特征提取器相比,我们现在要宣布单词和短语的特征。我们从一个非常简单的例子开始,使用词典来存储功能及其值。

对象kim和chase都有几个共享功能,CAT(语法类别)和ORTH(拼写,即拼写)。此外,每个都有一个更加语义导向的功能:kim [‘REF’]旨在给出kim的指示物,chase [‘REL’]给出chase表达的关系。
在基于规则的语法的上下文中,这种特征和值的配对被称为特征结构,我们很快就会看到替代符号。
特征结构包含语法实体中很多信息,信息不必是详尽的,我们可能想要添加更多的属性,例如,在动词的情况下,动词起的语义作用是什么?在"chase"的情况下,主语扮演了"agent"的角色,宾语扮演了"patient"的角色,让我们把这个信息添加上,让我们用"sbj"和"obj"占位,等动词和语法的参数结合起来时再把它们填充。
agent:施事。表示执行动词动作的人或动物等
patient:受事。表示受动作影响的人或事等

如果我们现在处理一个句子" Kim chased Lee",我们想要绑定施事的角色到主语,绑定受事的角色到宾语,我们通过链接到相关NP的REF特征来实现这一点。在下面的例子中,我们做了一个简单的假设,即动词左边和右边的NP分别是主语和宾语。我们还为Lee添加了一个功能结构来完成示例
对于不同的动词可以采用相同的方法,说出惊讶,虽然在这种情况下,主体将扮演“源”(SRC)和对象,“经验者”(EXP)的角色:
我们在本章的下一个任务是展示如何扩展上下文无关语法和解析的框架以适应特征结构,以便我们可以以更通用和有原则的方式构建这样的分析。我们将从语法一致性现象开始; 我们将展示如何使用特征优雅地表达一致性约束,并用简单的语法说明它们的用法。
由于特征结构是用于表示任何类型信息的通用数据结构,因此我们将从更正式的角度简要介绍它们,并说明对NLTK提供的特征结构的支持。在本章的最后部分,我们证明了特征的额外表现力为描述语言结构的复杂方面开辟了广泛的可能性。
9.1.1语法的一致性
下面的例子展示了成对的单词序列,第一个符合语法,第二个不符合语法。(我们在单词序列的开头使用星号来表示它不符合语法。)

在英语中,名词通常被标记为单数或复数。示范的形式也各不相同:这(单数)和这些(复数)。例子(1b)和(2b)表明在名词短语中使用说明和名词存在限制:要么两者都是单数,要么两者都是复数。
主语和谓词之间存在类似的约束:

在这里我们可以看到动词的形态特征与主语名词短语的句法属性共同变化。这种共同变化称为一致性。如果我们进一步研究英语中的动词一致性,我们将看到现在时态动词通常有两种变形形式:一种用于第三人称单数形式,另一种用于人与数字的其他组合,如1.1所示。

我们可以使形态属性的作用更加明确,如ex-run和ex-run中所示。这些陈述表明该动词与其主题和人数一致。 (我们使用“3”作为第3人的缩写,“SG”作为单数,“PL”作为复数。)
让我们看看当我们在无上下文语法中编码这些一致性约束时会发生什么。我们将从(5)中的简单CFG开始。

语法(5)允许我们生成"this dog runs"的句子; 然而,我们真正想要做的是生成"these dogs run",同时阻止不需要的序列,如"*this dogs run"和"*these dog runs"最直接的方法是在语法中添加新的非终结符和产生式:

取代单个生产扩展S,我们现在有两种产生式,一种涵盖涉及单一主题NP和VP的句子,另一种涵盖具有多个主题NP和VP的句子。实际上,(5)中的每个生产在(6)中都有两个对应物。语法很小,虽然它在美学上没有吸引力,但这并不是一个真正的问题。然而,对于涵盖合理的英语结构子集的更大语法,将语法大小加倍的前景是非常不具吸引力的。我们现在假设我们使用相同的方法来处理第一,第二和第三人的一致性,无论是单数还是复数。这将导致原始语法乘以因子6,这是我们绝对想要避免的。我们能做得比这更好吗? 在下一节中,我们将展示捕获号码和人称一致性不需要以“搞砸”产生式数量为代价。
9.1.2使用属性和约束
我们非正式地谈论了具有属性的语言类别; 例如,名词具有复数属性。
让我们明确这样做:
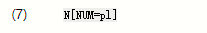
在(7)中,我们引入了一些新的符号,表示类别N具有称为NUM(“数字”的缩写)的(语法)特征,并且该特征的值是pl(“复数”的缩写)。我们可以向其他类别添加类似的注释,并在词法条目中使用它们:

这有帮助吗? 到目前为止,它看起来就像是(6)中指定的更冗长的替代方案。当我们允许变量超过特征值时,事情变得更有趣,并使用这些来约束状态:

我们使用?n作为NUM的值的变量;它可以在给定的产生方式中实例化为sg或pl。我们可以阅读第一个产生式,即无论NP对于特征NUM采用什么值,VP必须采用相同的值。
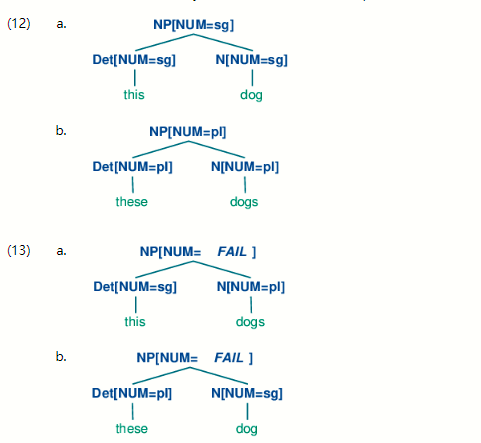
为了理解这些特征约束是如何工作的,考虑如何构建树是有帮助的。词汇作品将承认以下本地树(深度为一的树):

现在S - > NP [NUM =?n] VP [NUM =?n]表示无论N和Det的NUM值是什么,它们都必须相同。因此,NP [NUM =?n] - > Det [NUM =?n] N [NUM =?n]将允许(10a)和(11a)组合成NP,如(12a)所示它也将允许(10b)和(11b)组合,如(12b)中所示。相比之下,(13a)和(13b)被禁止,因为它们的子树的根在NUM特征的值上有所不同; 这些值的不兼容性通过顶部节点处的FAIL值非正式地指示。
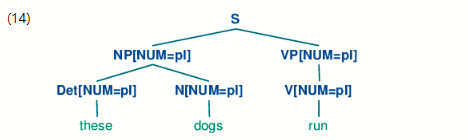
产生式VP [NUM =?n] - > V [NUM =?n]表示头部动词的NUM值必须与VP父级的NUM值相同。结合用于扩展S的产生式,我们推导出如果主题头名词的NUM值是pl,那么VP的头部动词的NUM值也是如此。
语法(8)说明了限定词的词汇产生式,如“this and these”,它们分别需要单数或复数头名词。然而,英语中的其他限定词并不是对它们所组合的名词的语法数字挑剔。描述这种情况的一种方法是在语法中添加两个词条,一个用于限定词的单数和复数形式,如“the”

但是,更优雅的解决方案是将NUM值保留为未指定,并使其与其组合的名词一致。 为NUM分配变量值是实现此结果的一种方法:

但实际上我们可以更加经济,并且在这样的制作中省略NUM的任何规范。
我们只需要在同一生产中的其他地方约束另一个值时显式输入变量值。
1.1中的语法说明了我们在本章中介绍的大部分想法,以及一些新的想法。
请注意,语法类别可以有多个功能;例如,V [TENSE = pres,NUM = pl]。通常,我们可以添加任意数量的功能。
关于1.1的最后细节是声明**%start S**.这个“指令”告诉解析器将S作为语法的起始符号。
通常,当我们尝试开发甚至非常小的语法时,将产生式放在可以编辑,测试和修改的文件中是很方便的。我们在NLTK数据分发中将1.1保存为名为 “feat0.fcfg”的文件。 您可以使用nltk.data.load()创建自己的副本以进行进一步的实验。
图1.2说明了具有基于特征的语法的图表解析器的操作。在对输入进行标记化之后,我们导入load_parser函数,该函数将语法文件名作为输入并返回图表解析器cp。调用解析器的parse()方法将迭代生成的解析树;
如果语法无法解析输入并且将包含一个或多个解析树,则树将为空,具体取决于输入是否在语法上不明确。
解析过程的细节对于当前目的而言并不重要。但是,有一个实现问题与我们之前对语法大小的讨论有关。解析包含特征约束的产品的一种可能方法是编译出所讨论的特征的所有可允许值,以便我们最终得到一个大的,完全指定的CFG(6)。相比之下,上面说明的解析器过程直接与语法给出的未指定的产生一起工作。特征值从词汇条目“向上流动”,然后变量值通过绑定(即字典)与这些值相关联,例如{?n:‘sg’,?t:‘pres’}。当解析器组装有关它正在构建的树的节点的信息时,这些变量绑定用于实例化这些节点中的值;因此,未指定的VP [NUM =?n,TENSE =?t] - > TV [NUM =?n,TENSE =?t] NP []变为实例化为VP [NUM =‘sg’,TENSE=‘pres’] - > TV [NUM =‘sg’,TENSE =‘pres’] NP []通过查找绑定中的?n和?t的值。
最后,我们可以检查生成的解析树(在这种情况下,只有一个)。
9.1.3 术语
到目前为止,我们只看到了像sg和pl这样的特征值。 这些简单的值通常称为原子 - 也就是说,它们不能分解为子部分。原子值的一个特例是布尔值,即只指定属性是true还是false的值。例如,我们可能想要区分辅助动词,例如can,may,will和do与布尔特征AUX。例如,生产V [TENSE = pres,AUX = +] - >'can’表示可以接收TENSE的值pres和+或AUX的真值。 有一种广泛采用的惯例,它缩写了布尔特征f的表示; 而不是AUX = +或AUX = - ,我们分别使用+ AUX和-AUX。然而,这些只是缩写,解析器将它们解释为+和 - 就像任何其他原子值一样。 (15)显示了一些代表性的产生式:
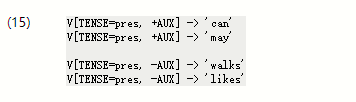
我们已经谈到将“特征注释”附加到句法类别。更激进的方法将整个类别(即非终端符号加注释)表示为一组特征。例如,N [NUM = sg]包含可以表示为POS = N的词性信息。 因此,该类别的替代符号是[POS = N,NUM = sg]。
除了原子值特征之外,特征还可以采用本身就是特征结构的值。例如,我们可以将一致性要素(例如,人,数量和性别)组合在一起作为类别的一个不同部分,将它们组合在一起作为AGR的值。在这种情况下,我们说AGR具有复杂的价值。 (16)以称为**属性值矩阵(AVM)**的格式描绘了该结构。
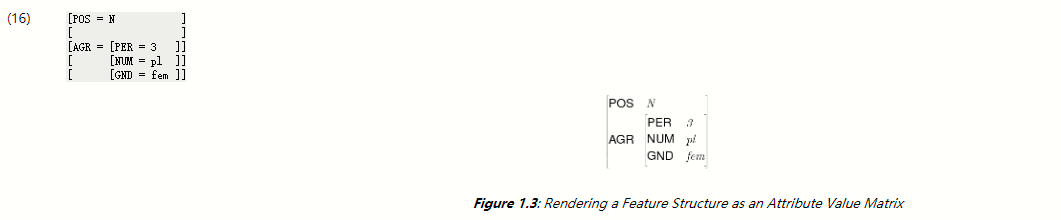
顺便说一句,我们应该指出,有其他方法可以显示AVM; 1.3显示了一个例子。尽管以(16)的风格呈现的特征结构在视觉上不那么令人愉悦,但我们将坚持使用这种格式,因为它对应于我们将从NLTK获得的输出。
关于表示的主题,我们还注意到特征结构,如字典,对特征的顺序没有特别的意义。 所以(16)相当于:

一旦我们有可能使用像AGR这样的功能,我们就可以重构像1.1这样的语法,以便将一致性功能捆绑在一起。
一个很小的语法说明了这个想法,如(18)所示。
