python实战1.0——爬取知乎某问题下的回复
- 确定问题
- 爬取
- 进行简单筛选
- 保存数据
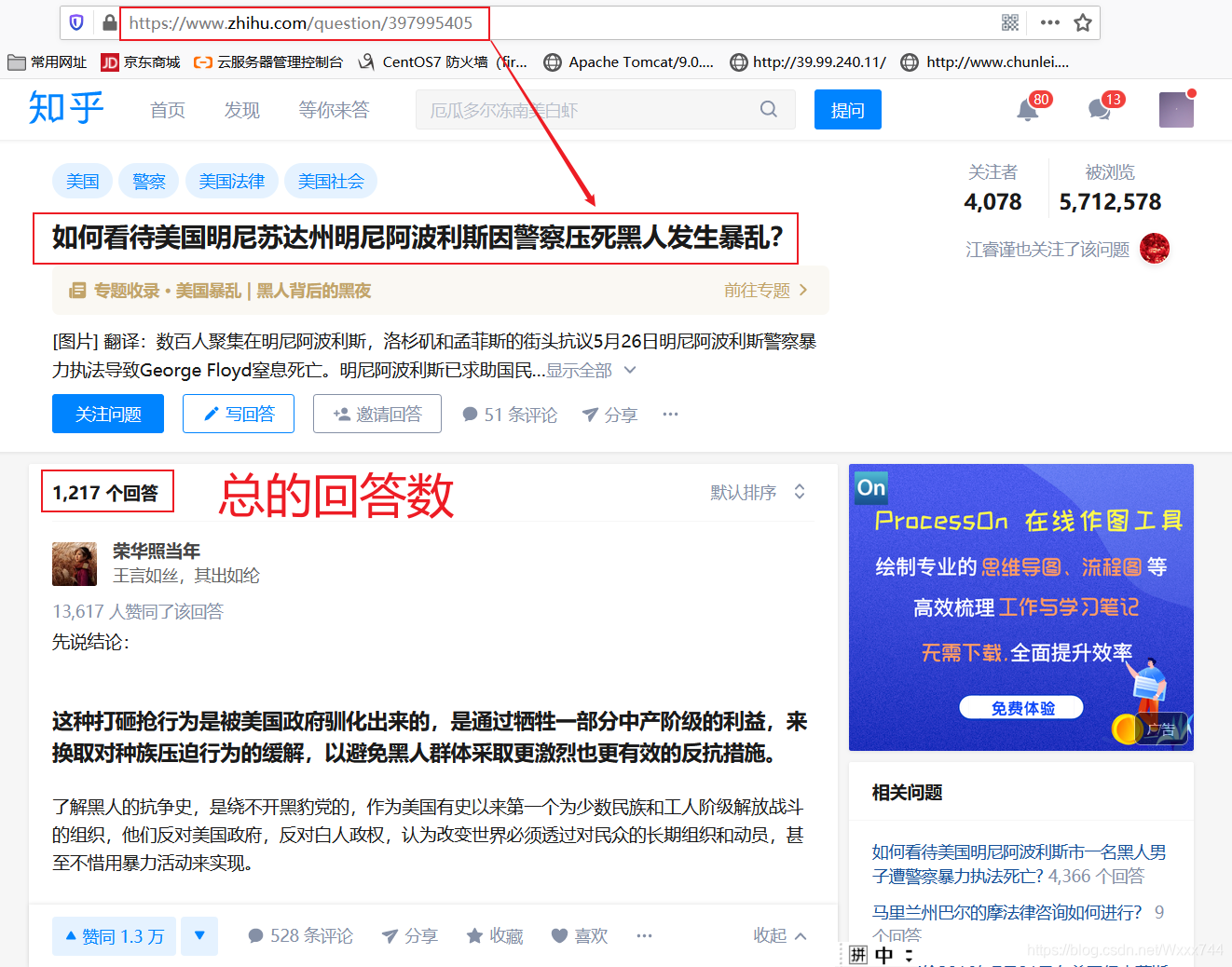
# 获取问题下的回复总数
def get_number():
url = 'https://www.zhihu.com/question/397995405'
kv = {
'User-Agent': 'Mozilla/5.0'} # 模拟登录
r = requests.get(url, headers=kv) # 获取网页
# print(r.status_code) 访问成功返回200
# print(r.text) #检查一下是否能打印出来
q = r.text
soup = BeautifulSoup(q, "html.parser")
all_answer = soup.find("h4", class_="List-headerText") # 获取总回答数的标签
all_answer2 = all_answer.find('span').get_text()
n = re.findall('(.+?)个', all_answer2) # 正则表达式->只获得数字,此时结果为 1,221
n1 = n[0].replace(',', '') # 去掉 1,221 中的 “ ,”
num = int(n1) # 强转为整型,用于后续遍历
# print(num) 此时结果为 1221
return num # 返回一个数值
动态爬取


# 获取问题下的所有回复
def get_content(i):
# 只改变offset的值,以获得不同人的回复
# limit是接收的条数,这里设置为1
# offset是回复的序号
json_url = "https://www.zhihu.com/api/v4/questions/397995405/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B*%5D.topics&offset=" + str(
i) + "&limit=1&sort_by=default&platform=desktop"
kv1 = {
'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
response = requests.get(json_url, headers=kv1)
time.sleep(0.5) # 防止被BAN
response_json = response.json() # 得到网页内容的json格式
response_data = response_json['data'] # 所需要的内容在json里的data中
m = response_data[0] # limit为1,用[0]取出
if more_than_300(m) >= 300:
n = m['content'] # 获得的views为字典类型,定位key值为‘content’获得回复内容,但此时为html形式
content = ''.join(re.findall(r'>(.*?)<', n)) # 提取回复的文本内容
return content
else:
pass
#获取赞同数
def more_than_300(m): # 筛选出 >300赞 的回复
num = m['voteup_count']
print(num)
return num

if __name__ == '__main__':
num = get_number()
for i in range(0, num): # 遍历每一个回复
content = get_content(i) # 得到每一个回复的文本内容
with open('D:\\pyhomework\\0516\\finalcontent.txt', 'a', encoding='utf-8') as f: # 将爬取的数据存入文档
if content is not None:
f.write(content + '\n' + '----------------------------------------------------' + '\n' + '\n')
else:
pass