这些 awk 的例子都是我在工作中遇到的,使用 awk 可以达到事半功倍的效果。大家也许可以参考一下。
1. 去掉每一行首尾空格,并编号
文件格式如下:
o ne
two
three
four
five
six
seven
eight
nine
ten
使用awk '{print "[",$0,"]"}' one.txt 查看,有的行还有空格:
[ o ne ]
[ two ]
[ three ]
[ four ]
[ five ]
[ six ]
[ seven ]
[ eight ]
[ nine ]
[ ten ]
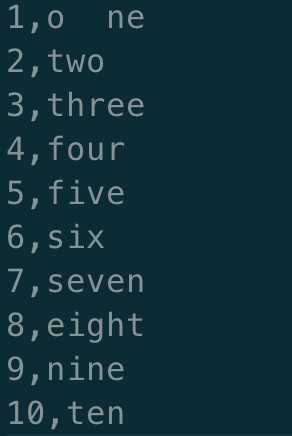
对每一行编号并逗号拼接,且将空格、制表符去掉,如 「one」 变成 「1,one」。
# 首先将空格给替换了,
# ^[ \t]+ 匹配行首一个或多个空格
# [ \t]+$ 匹配行末一个或多个空格
# ^[ \t]+|[ \t]+$ 同时匹配行首或者行末的空格
awk '{gsub(/^[ \t]+|[ \t]+$/,"");print $0}' one.txt
# 使用内建变量 OFS 和 NR 打印逗号和行号
awk -v OFS=',' '{gsub(/^[ \t]+|[ \t]+$/,"");print NR,$0}' one.txt > one_re.txt
最后输出结果:
2. 将文件中每一行的数字 id 使用逗号拼接,并合共成一行
文件内容格式如下:
124
432
3252
4634
654
76
3453
57546
3453
45645
34535
3463
3453
456345
# printf 类似于 C语言printf函数
awk '{printf "%s,",$1}' ids.txt
结果如下:
124,432,3252,4634,654,76,3453,57546,3453,45645,34535,3463,3453,456345,%
3. 比较两个文件,找出两个文件中的 diff 数据
文件 1:region_prod.txt 如下:
"北京",
"上海",
"重庆",
"天津",
"三沙",
"长沙",
"四川"
文件 2:region_test.txt 如下:
"上海",
"重庆",
"四川",
"北京",
"天津"
执行下面的 awk 代码,如果 region_prod.txt 中的数据在 region_test.txt 中不存在,则会进行打印。
awk -F, 'NR==FNR{a[$1];next}!($1 in a)' region_test.txt region_prod.txt
输出结果:
"三沙",
"长沙",
交换两个文件的位置,反之亦然:
awk -F, 'NR==FNR{a[$1];next}!($1 in a)' region_prod.txt region_test.txt
具体的细节描述,可参考:awk之in的运用实例
如何使用 awk 的 ‘next’ 命令
4.匹配文件中数字的行,并打印出前10行出现数字的行号
文件格式:
dfdddgds,
1231,
-2352,
fgd,
dfgfd,
awk -F, '{if($1 ~ /^[ ]*-?[0-9]+$/) print NR}' main.log | head -n 10
-F,:指定每行的列分隔符为,
if($1 ~ /^[ ]*-?[0-9]+$/):判断第一个记录 $1 是否能和正则表达式匹配
~:匹配操作符,用于对记录或字段的表达式进行匹配
/^[ ]*-?[0-9]+$/:匹配数字的行的正则表达式
NR:已经读出的记录数,行号