这里假设读者还是有点Linux 基础(敲过一些linux 命令).haha...
awk是一个强大的文本分析工具,生产中,我们也会经常用到,这里我就列举一下作为开发人员,常用的一些操作
开发人员在开发过程中,其实很要在Linux环境下操作,更多的是上线后的一些分析协查,就比如我们经常会分析程序导出,下载的一些文件有没有问题,本文也是基于这么一个场景,列举一些常用操作
举例中用到的文件我上传了,大家可自己下载,以下命令可以直接执行查看结果(记得文件要到执行的目录下)。
假设我们的文件“awk_demo.txt” 是一个订单的明细文件,第一行是汇总,第二列是订单号,第四列是金额
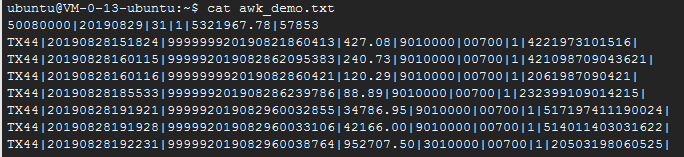
举例1: 要统计一下总金额
awk -F '|' '{print sum+=$4}end{printf sum}' awk_demo.txt结果如下:
金额累加了没问题,但第一行不对,第一行是汇总,不应该被统计进去
知识点分析:
-F '|' 这里是把文件里的行用“|”分割,如果你的文件不是以“|”分割,你就可以替换成相应的分割符
$4 是个变量,这里就是我们想要取的列,如果是第一列就可以$1,以此类推,有些程序猿的思维觉得第一列不应该是$0么?
确实有$0 但它不是第一列,它是awk的内置变量 ,代表的是当前记录(这里表一整行记录),感兴趣的同学自己尝试
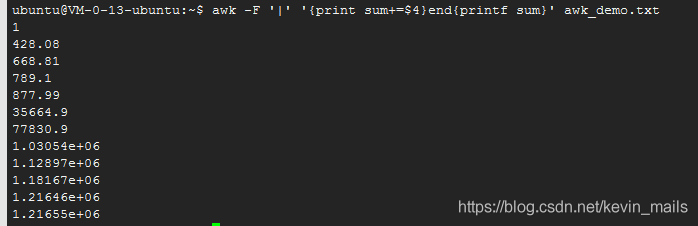
修改如下:
awk -F '|' '{if(NR>1){print sum+=$4}}end{printf sum}' awk_demo.txt结果如下:
第一行被排除了,但是最后5行显示的有点问题(是科学计数法),看不懂啊。。。。
知识点分析:
这里排除第一行我们用了一个if(NR>1), NR 也是awk的内置变量 NR是行号,代表当前处理的文本行的行号
还有一些常见的内置变量
FS:输入字段分隔符, 默认为空白字符
OFS:输出字段分隔符, 默认为空白字符
RS:输入记录分隔符(输入换行符), 指定输入时的换行符
ORS:输出记录分隔符(输出换行符),输出时用指定符号代替换行符
NF:number of Field,当前行的字段的个数(即当前行被分割成了几列),字段数量
FNR:各文件分别计数的行号
FILENAME:当前文件名
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数
感兴趣的同学自己尝试
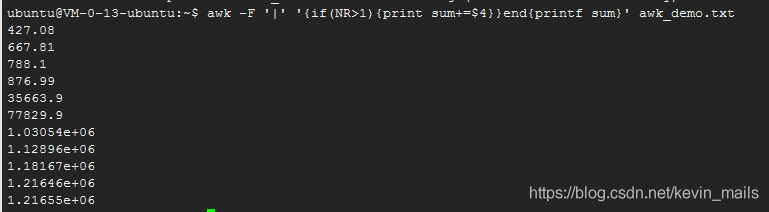
再修改下:
awk -F '|' '{if(NR>1){printf "%.2f\n", sum+=$4}}end{printf sum}' awk_demo.txt结果如下:
这次最终得到了我们想要的数据(最后一行)
知识点分析:
这里用了printf 命令格式化输出,"%.2f\n" 指定为浮点数显示,保留两位小数,因为printf不会换行需显式指定换行控制符,\n
这里还有一些其它常用格式符:
%c:显示字符的ASCII码
%d, %i:显示十进制整数
%e, %E:显示科学计数法数值
%f:显示为浮点数
%g, %G:以科学计数法或浮点形式显示数值
%s:显示字符串
%u:无符号整数
%%:显示%自身
输入的字的颜色样式都可以格式化,感兴趣的同学自己尝试
举例2: 找出文件中重复的订单
awk -F '|' '{if(NR>1){print $2}}' awk_demo.txt |sort|uniq -dc结果如下:

第一列为重复的数量,第二列为订单号
知识点分析:
这里需要借助sort uniq 两个命令才能完成操作 ,sort 是结果排序 uniq 是去重 ,uniq只能对相邻(连续)的行去重,所以一般情情况下会跟sort配合使用
-c 统计出现的次数,-d 只展示重复的行
其实awk 能干的事情要比我说的多太多,这里只只说了几个常用的用法,希望对大家有用!