转自知乎网

工具和环境
- 语言:python 2.7
- IDE: Pycharm
- 浏览器:Chrome
- 爬虫框架:Scrapy 1.2.1
正文
方法1
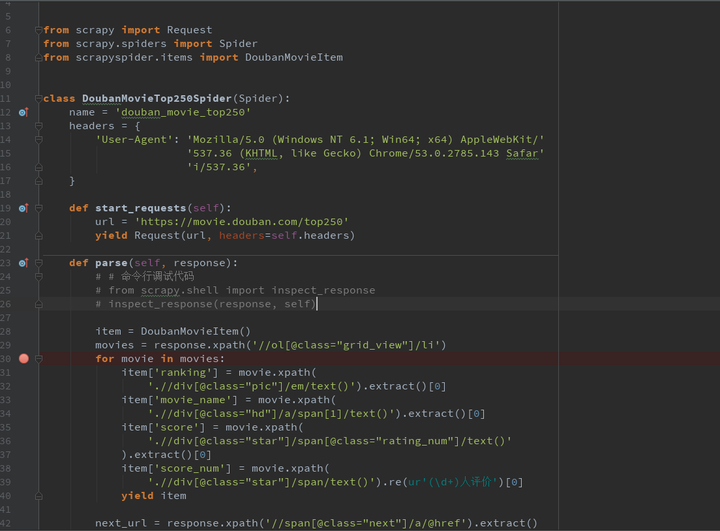
通过 scrapy.shell.inspect_response 函数来实现。以上一篇教程的爬虫为例:
# -*- coding: utf-8 -*-
# @Time : 2017/1/7 17:04
# @Author : woodenrobot
from scrapy import Request
from scrapy.spiders import Spider
from scrapyspider.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safar'
'i/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
def parse(self, response):
# 命令行调试代码
from scrapy.shell import inspect_response
inspect_response(response, self)
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath(
'.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath(
'.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath(
'.//div[@class="star"]/span[@class="rating_num"]/text()'
).extract()[0]
item['score_num'] = movie.xpath(
'.//div[@class="star"]/span/text()').re(ur'(\d+)人评价')[0]
yield item
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url, headers=self.headers)
我们在下载完网页源码进行解析前可以插入上述两句代码,在命令行运行爬虫出现以下效果:
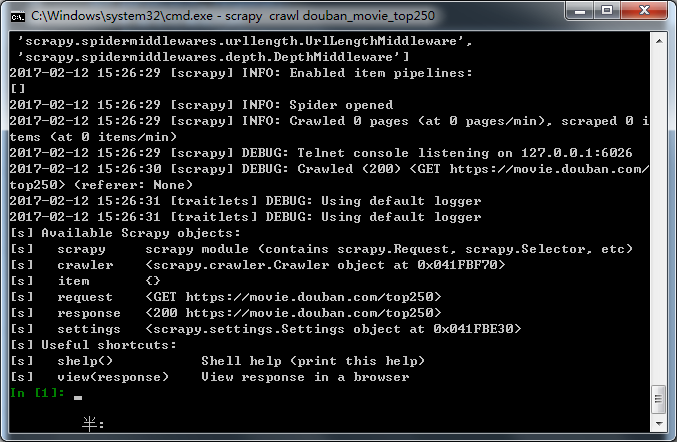 此时我们就可以在命令行中使用xpath规则对response进行操作提取相应的信息:
此时我们就可以在命令行中使用xpath规则对response进行操作提取相应的信息:
 有时候下载下来的网页结构和浏览器中看到的不一样,我们可以利用view(response)将爬虫下载到的网页源码在浏览器中打开:
有时候下载下来的网页结构和浏览器中看到的不一样,我们可以利用view(response)将爬虫下载到的网页源码在浏览器中打开:
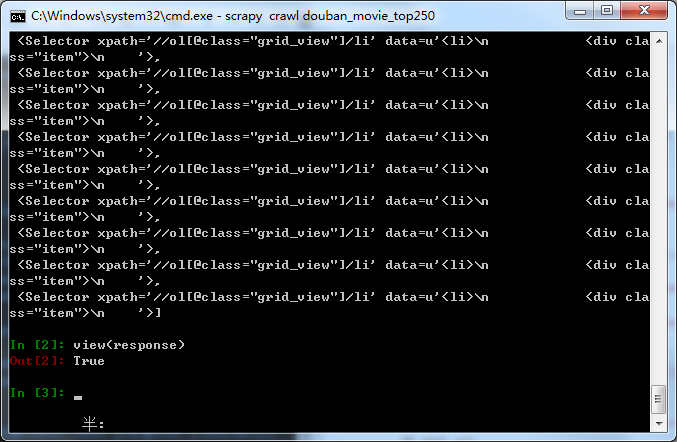 在命令行输入view(response)后默认浏览器会自动打开下载到的网页源码。
在命令行输入view(response)后默认浏览器会自动打开下载到的网页源码。
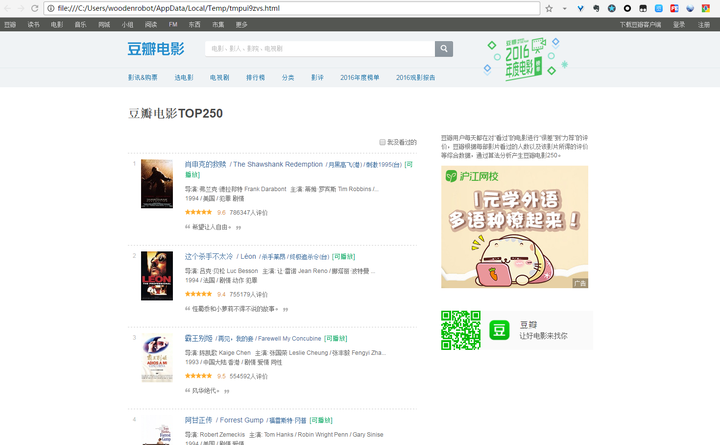 虽然scrapy自己提供了这个方式让我们调试自己的爬虫,但是这个方式有很大的局限性。如果能利用pycharm的Debug功能进行调试就太好了。下面我就为大家介绍这么用pycharm调试自己的爬虫。
虽然scrapy自己提供了这个方式让我们调试自己的爬虫,但是这个方式有很大的局限性。如果能利用pycharm的Debug功能进行调试就太好了。下面我就为大家介绍这么用pycharm调试自己的爬虫。
方法2
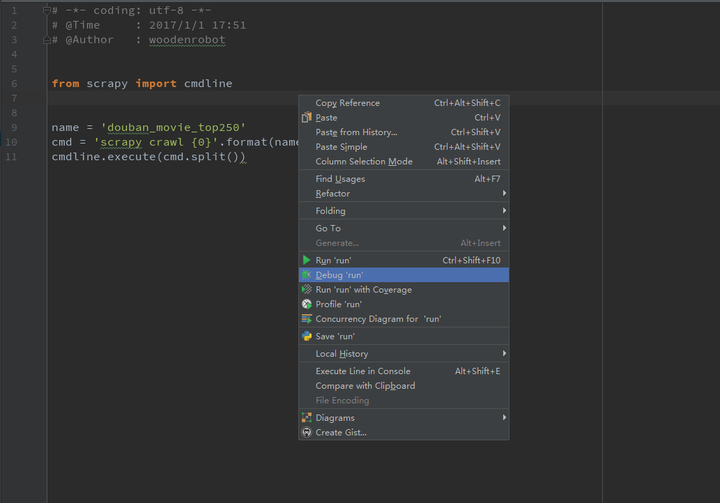
首先在setting.py同级目录下创建run.py文件。
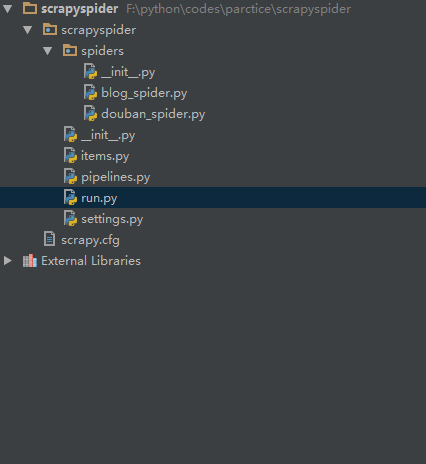
写入以下代码:
# -*- coding: utf-8 -*-
# @Time : 2017/1/1 17:51
# @Author : woodenrobot
from scrapy import cmdline
name = 'douban_movie_top250'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
其中name参数为spider的name。
接着在spider文件中设置断点。
 返回run.py文件中右键选择Debug。
返回run.py文件中右键选择Debug。
 最后程序就会在断点处暂停,我们就可以查看相应的内容从而进行调试 。
最后程序就会在断点处暂停,我们就可以查看相应的内容从而进行调试 。

结语
两种方法适合不同的场景,不过一般情况下肯定是方法2好用。