今年知乎网进行了改版,界面变成了这个样子
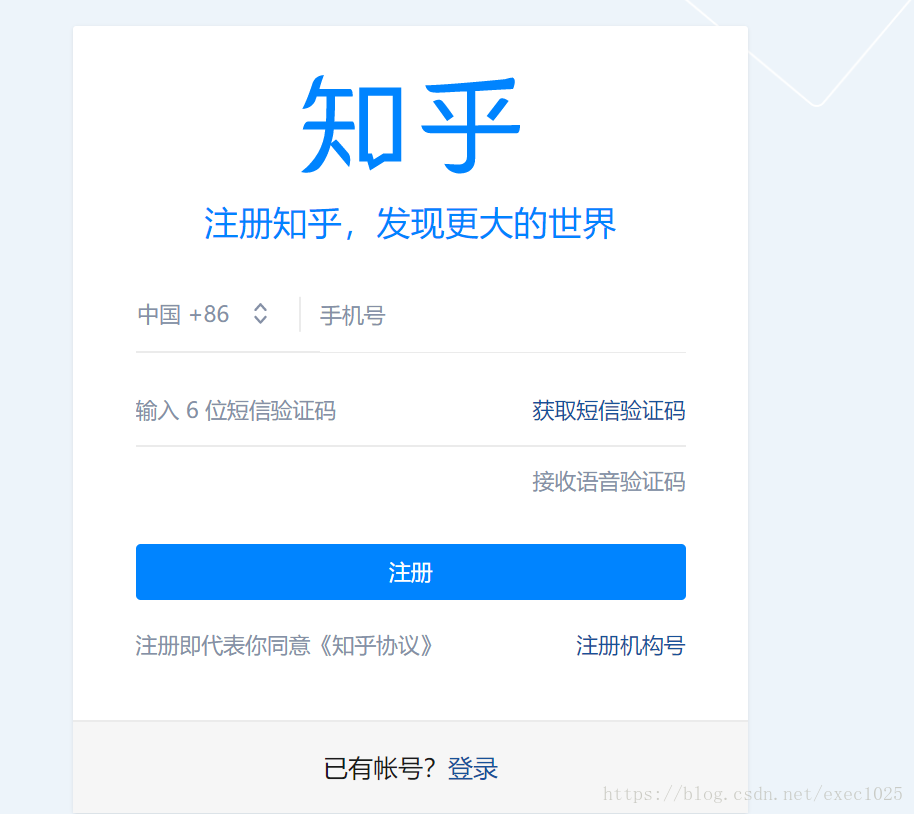
网站的源码也相应做了变化,很多博客上的登录方式已经不行了
有一种万能的办法就是用无头浏览器去模拟登陆,可是这样做的效率低下
经过一番查找,在git上找到了某位大神的解决办法,源码如下:
import requests, time
import hmac, json
from bs4 import BeautifulSoup
from hashlib import sha1
def get_captcha(data, need_cap):
''' 处理验证码 '''
if need_cap is False:
return
with open('captcha.gif', 'wb') as fb:
fb.write(data)
return input('captcha:')
def get_signature(grantType, clientId, source, timestamp):
''' 处理签名 '''
hm = hmac.new(b'd1b964811afb40118a12068ff74a12f4', None, sha1)
hm.update(str.encode(grantType))
hm.update(str.encode(clientId))
hm.update(str.encode(source))
hm.update(str.encode(timestamp))
return str(hm.hexdigest())
def login(username, password, oncaptcha, sessiona, headers):
''' 处理登录 '''
resp1 = sessiona.get('https://www.zhihu.com/signin', headers=headers) # 拿cookie:_xsrf
resp2 = sessiona.get('https://www.zhihu.com/api/v3/oauth/captcha?lang=cn',
headers=headers) # 拿cookie:capsion_ticket
need_cap = json.loads(resp2.text)["show_captcha"] # {"show_captcha":false} 表示不用验证码
grantType = 'password'
clientId = 'c3cef7c66a1843f8b3a9e6a1e3160e20'
source = 'com.zhihu.web'
timestamp = str((time.time() * 1000)).split('.')[0] # 签名只按这个时间戳变化
captcha_content = sessiona.get('https://www.zhihu.com/captcha.gif?r=%d&type=login' % (time.time() * 1000),
headers=headers).content
data = {
"client_id": clientId,
"grant_type": grantType,
"timestamp": timestamp,
"source": source,
"signature": get_signature(grantType, clientId, source, timestamp), # 获取签名
"username": username,
"password": password,
"lang": "cn",
"captcha": oncaptcha(captcha_content, need_cap), # 获取图片验证码
"ref_source": "other_",
"utm_source": ""
}
# print("**2**: " + str(data))
# print("-" * 50)
resp = sessiona.post('https://www.zhihu.com/api/v3/oauth/sign_in', data, headers=headers).content
# print(BeautifulSoup(resp, 'html.parser'))
# print("-" * 50)
return resp
if __name__ == "__main__":
sessiona = requests.Session()
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36',
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20'}
login('你的邮箱', '你的密码', get_captcha, sessiona, headers)
resp = sessiona.get('https://www.zhihu.com/inbox', headers=headers) # 登录进去了,可以看私信了
# print(BeautifulSoup(resp.content, 'html.parser'))
resp2 = sessiona.get("https://www.zhihu.com/people/mu-yu-50-79/following", headers=headers)
print(resp2.text)