通过上一篇文章对 JMM 的学习,你一定掌握了,Java 内存模型就是规范了 JVM 如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括 volatile、synchronized 和 final 三个关键字,以及六项 Happens-Before 规则。
这篇文章,我们就来深入了解下 高频面试点 volatile 关键字的内存语义和实现。 同时搞清楚了volatile,对我们后续学习java并发包中的各种线程安全容器和一些开源框架源码也会有很大帮助,因为你会在实现中 频繁看到 volatile 的身影。 通过本篇文章的学习,能让你清楚的知道为什么在很多并发场景需要使用这个关键字,同时也能让你在一些大厂面试中,顺利通关。
volatile的表象是什么
学技术要通过现象看本质,那么问题来了,voaltile是什么? 表象是什么?具体有什么特性呢?

要理解 voaltile 特性,一个非常好的方法就是将 对 volatile 变量的单个 读或者写,看成是使用同一个锁对这些 单个的读写操作 做了同步。 这块可能光说是不好理解的,看一组代码,你一定会明白的。

假设有多个线程分别调用上面程序的3个方法,这个程序在语义上和下面程序等价。

通过上面的代码,我们可以看到对 volatile 修饰的共享变量做单个读写操作时,是和加锁效果一样的,也就意味着对一个volatile变量的读总是能看到对它的最后一次写入。 需要注意的是,如果是多个 voaltile 操作或者类似 volatile++ 这种操作是无法保证整体操作的原子性的。
总结下,volatile修饰的变量具有这两个特性:
- 可见性。对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写
入。 - 原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不
具有原子性。
看了表象后,你肯定会问,那么具体voaltile到底是如何保证对单个变量的单步操作实现可见性和原子性的呢?

别着急,接着来,我们一起看下JMM是如何保证的。
volatile的内存语义及实现
volatile写的内存语义:
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存。
volatile读的内存语义:
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量
说白了,其实就是禁用CPU缓存。
例如,我们声明一个 volatile 变量 volatile int x = 0,它表达的是:告诉编译器,对这个变量的读写,不能使用 CPU 缓存,必须从内存中读取或者写入。
上一篇文章我们学到了重排序分为编译器重排序和处理器重排序。为了实现volatile内存语义,JMM会分别限制这两种类型的重排序类型。
下面这个表格就是JMM针对编译器制定的volatile重排序规则表:
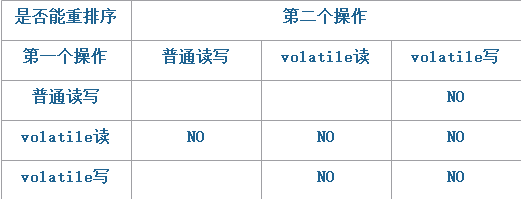
举例来说,第三行最后一个单元格的意思是:在程序中,当第一个操作为普通变量的读或写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的后面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。
作为Java程序员,我们只要知道内存屏障它可以保证在任意处理器平台,任意的程序中都能得到正确的volatile内存语义即可,具体的处理器实现细节能力有限就不往下说了,感兴趣的可以自行去更进一步哈。
扩展:JSR-133为什么要增强volatile的内存语义
说明这个问题之前我们先看一段代码:
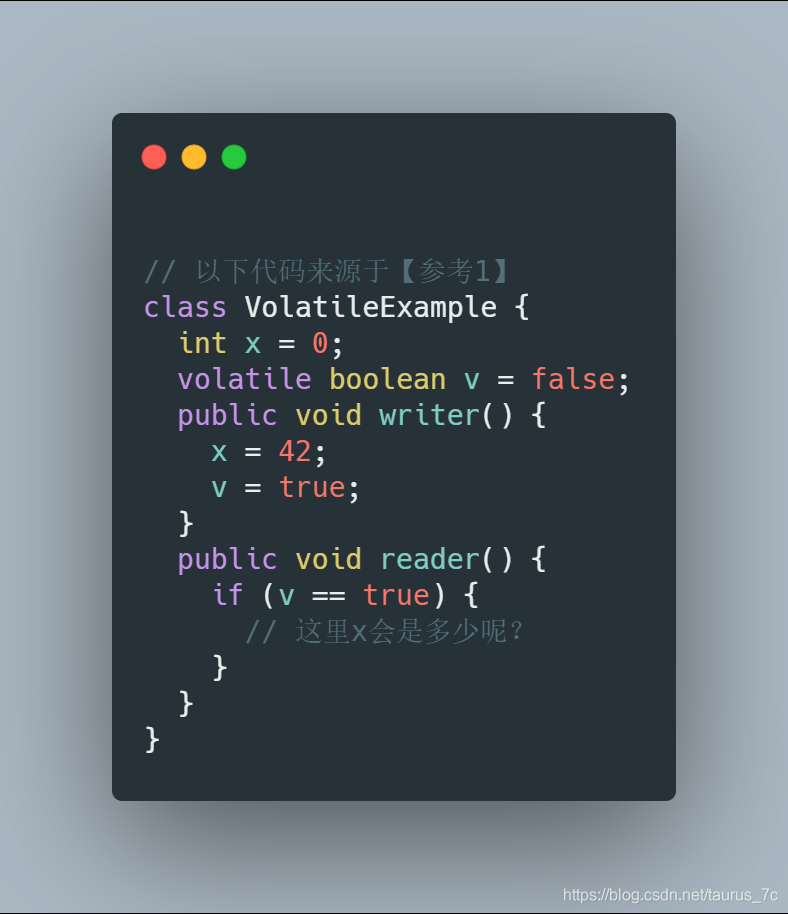
例如下面的示例代码,假设线程 A 执行 writer() 方法,按照 volatile 语义,会把变量 “v=true” 写入内存;假设线程 B 执行 reader() 方法,同样按照 volatile 语义,线程 B 会从内存中读取变量 v,如果线程 B 看到 “v == true” 时,那么线程 B 看到的变量 x 是多少呢?
直觉上看,应该是 42,那实际应该是多少呢?这个要看 Java 的版本,如果在低于 1.5 版本上运行,x 可能是 42,也有可能是 0;如果在 1.5 以上的版本上运行,x 就是等于 42。
分析一下:在JSR-133之前的旧Java内存模型中,虽然不允许volatile变量之间重排序,但允许volatile变量与普通变量重排序。
也就是说在旧的内存模型中,线程A在执行 1. x=42 2. v=true 时,由于1和2之间没有数据依赖关系,所以可能被重排序,所以可能导致在线程B执行到v==true后,x可能并没有执行,就看到x值为0;
因此,在旧的内存模型中,volatile的写-读没有锁的释放-获取所具有的内存语义。为了提供一种比锁更轻量级的线程之间通信的机制,JSR-133专家组决定增强volatile的内存语义。怎么增强的呢?
从编译器重排序规则和处理器内存屏障插入策略来看,只要volatile变量与普通变量之间的重排序可能会破坏volatile的内存语义,这种重排序就会被编译器重排序规则和处理器内存屏障插入策略禁止。
而从我们程序员理解的视角来看就是一项 Happens-Before 规则。 如何理解具体的Happens-Before规则,后续的Java并发编程系列文章会娓娓道来,敬请期待。

精彩文章推荐:
最近面试 字节、BAT,整理一份面试资料《Java 面试 BAT 通关手册》,覆盖了 Java 核心技术、JVM、Java 并发、SSM、微服务、数据库、数据结构等等。获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上
