2019年春节档有一部黑马电影《流浪地球》,我个人很喜欢。这部电影中有一个悲伤的情节,因为地震杭州被岩浆吞没了。网络上有人调侃,杭州没了,花呗还要还吗?大家也就是搞笑,没想到支付宝官方竟然也跑来凑热闹,告诉大家支付宝三地五中心备份,杭州没了,花呗依然要还。

杭州没了,花呗依然要还,这或许就是分布式模型的魅力。类似这样的模型很多,如著名的比特币分布式网络,面临世界各国政府的轮番制裁,依然稳定运行了十多年,无一秒宕机。回到我们的嵌入式系统,这样的分布式模型对我们会有哪些启发呢?
在真实世界中,大家还是喜欢集中模型,不仅简单,也符合我们的思维习惯。但习惯并不一定总是正确的,很多现实世界的困惑,让我们颇为头疼,如:
- 设备参数太多,解析耗时,导致初始化启动缓慢。
- 用户对开入开出数量的要求越来越多,但IO引脚受CPU限制。
- 计算量越来越大,CPU快爆了。
- 各板件连接不仅成本高,而且易出现接触问题。
- ……
现实世界的诸多困惑,能否从分布式那儿借鉴一定有价值的设计理念呢?
◇◇◇
随着需求的增加,各软件模块都需要相应的参数配置,这也导致了设备中参数文件越来越多。参数文件过多会导致解析耗时,flash组织困难,解析过程中可能需要占用大量珍贵的ram资源等,有没有更好的策略呢?

如果我们仔细思量,会发现参数文件解析这个过程仅在装置上电初始化时运行,那么是否可以将这部分功能分布到其他地方呢?
我在跨国公司做产品研发时,接触到了一个全新的概念——配置软件。在前面的文章中我已经多次提及,配置软件是解决基于平台化研发时各装置差异的一个重要着力点,会依据不同的设备生成相应的参数文件,如果能再往前进一步,将参数文件的解析过程分布到配置软件部分,将会带来意想不到的惊喜。

配置软件会带给我们很多惊喜:
- 参数文件过多,且每个文件大小不确定,会给flash组织增加很多困难。通过配置软件,可以将这些参数文件捏合起来,甚至将程序、现场配置,解析后参数等全部捏合在一起,不仅大幅度节省了flash资源,也方便现场工程维护和程序升级。
- 通过配置软件,可以将参数文件解析为CPU执行时需要的样子,这需要考虑cpu诸多硬件特性,如字节顺序、对齐等。此时,参数文件的解析过程会内化为指针映射过程,可以大幅度提升解析过程。现场工程维护时,我们的产品上电经常是一瞬而过,而其他友商的产品还在蜗牛爬,经常给用户很大的震撼。
- 参数文件中有很大一部分内容是只读信息,基于预解析的参数结构,只读信息可以直接映射到flash空间。这一策略可以大幅度节约ram资源,在工业嵌入式系统中,ram资源一般是紧缺资源。
- 在参数文件中会存在大量的索引类信息,特别是一些交叉索引信息。面对这类问题,要么在初始化时耗时多遍遍历计算索引,要么在执行过程中耗时查找,总之都不太友好。配置软件是一个台式机软件,可以多遍遍历,将所需要的各种索引信息提前计算出来,嵌入式程序部分会变得简单友好许多。
当然,配置软件的功能不仅仅如此。基于高复用严格平台化架构的产品研发体系,不仅参数文件多,还需要为诸多软件模块和专业人员生成多样性的接口,去弥合各领域产品的差异部分,让平台部分代码更具备高复用性。总之,配置软件是高复用严格平台化架构中不可缺少的一环。
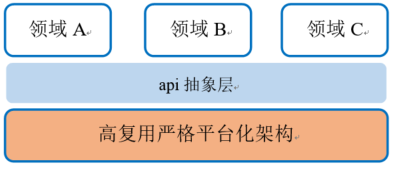
在跨国公司研发的那段时间,同架构师交流,他有一句话对我触动很深:配置软件的高度决定了程序架构的高度。可能配置软件对用户不可见吧,国内的研发团队不太喜欢去做这种出力不讨好的事情,最根本的原因是没有认识到配置软件的巨大好处。
当然,这也表明我们还有很大的成长和进步空间,让我们一起加油。
◇◇◇
为了应对各种恶劣的运行环境,很多工业嵌入式设备都有一个坚固的机箱,里面是一块块的插板,如下图所示:

随着用户的需求增加,对开入开出等外部接口要求越来越多,插板也越来越多,此时带来了一个尴尬的问题:连接问题。不管是采用母板还是各种连接线,随着接头数量的增加,成本都在快速上升,而可靠性在快速下降。
我以前维护过的某产品就频繁出现接触问题,工程人员经常需要随身携带几根排线,不仅服务成本非常高,还给用户带来很多麻烦。为了提升可靠性,我们换了一些比较好的接插件后,但价格又太贵,很多时候一个接插件都可以买好几个cpu了。
后来,我接触到一款地铁用直流继保设备,颇受触动,他们用can总线将各种接插件连接起来,仅用几根线,就可以连接很多块扩展板件,如下示意:

借鉴这种设计理念,我们项目组的后续产品也采用了基于CAN的分布式架构设计理念,如下图示意:

这种设计理念给硬件设计带来了很大遍历,因为都基于can接口,很多板件都具有高复用性。CAN只有两根线,外加电源,即使2~3倍冗余,也仅需要很普通的接线端子。
随着对分布式CAN总线的深入研究,我们甚至做到了液晶界面,以太网扩展等模块的分布。
液晶显示一般需要总线驱动,同时液晶安置在前面板上,距离主cpu比较远,这会带来两方面的困惑:
- 总线走线过长,设备可靠性下降比较明显,电磁兼容性能下降厉害。
- 总线会占用很多cpu的io口,会挤压其他模块。
液晶显示数据量又比较大,为了保证用户体验,反应速度还不能太慢,需要综合权衡基于can网的各种数据传输才能做到。我们在“GUI人机接口”章节会进一步阐述。
以太网需求是另外一个痛点。目前大多数主流cpu仅自带一个mac模块,但随着智能化的进展,很多工业嵌入式设备都需要很多路网口,如何扩展网口是另外一个痛点。通过can网,扩展一个支持mac的廉价cpu,成为一种可选方案。
can是一种多主带优先级的短帧,基于can网的分布式系统,有两个关键点:
- 多板之间的链路管理机制
- can网数据组织
在我们的系统中,链路管理策略如下:
- 主板和各扩展板之间没有数据通信时,需构建心跳报文以检测can通讯是否正常。为了充分复用,心跳报文可兼顾对时等功能。
- 主板定时(如5s)给各扩展板发送对时报文,如果发送成功,表明can硬件进行了ack确认,硬件工作正常。各扩展板应该在两次对时报文之间至少发送一帧数据,以表明软件正常运行,如没有其他高优先级数据可发送时,该帧数据可以是DI和AI的刷新数据,或者nop数据。
- 如果发送的是板件类型应答报文,则说明扩展板can模块发生了至少一次复位,做事件记录,并进行相应的数据处理(如复位相关板件的数据结构)。
- 主板刚上电时,需要和各扩展板进行第一次链路建立命令,各扩展板接收到后,发送“板件类型应答”报文,双方设置标志表明已建立好连接。
- 主板一般初始化时间比各扩展板长,在主板发送建立链路命令的时候,各扩展板应该已初始化完毕并在等待接收对时命令。初始化过程中如果存在扩展板异常时,需要超时判断,整个时间会比较长,建议在设备初始化完毕之后进行,以防止给用户装置上电时间过长的感觉,也即可认为链路建立不属于初始化模块(放入链路状态机)。
- 对时帧时间格式采用6字节unix时间格式,直接精度对时到ms,因can的一帧数据传输延时小于1ms(在512k波特率下),一般需求不需要额外的调整。
- can机制会自动重传和恢复,因此在软件层不在处理帧本身的重传,但关键类数据需通过应用帧进行确认,如soe和do等。
基于如上策略,主cpu和各扩展板之间完整连接过程如下:
- 主板初始化时刻发送连接命令,各扩展板收到后发送板类型,主板未收到时定时(如2s)重传。
- 主板定期(如5s)发送对时命令,各扩展板收到后发送状态数据(无状态数据时发送nop数据)。
- 如果主板在下一次发送对时命令时仍没有收到扩展板发送的对时命令,可认为扩展板异常,则改为发送连接命令。
- 主板有数据时会立即发送,而不管是否建立连接成功,以防止因处于连接过程而丢数据。
- 各扩展板在未建立连接前不允许发送数据,但接收到数据后需立即响应并处理,因主板可先于连接发送数据。
- 正常连接过程中,扩展板异常表现为发送定时命令时返回板类型,做事件记录,并进行相应处理。
- 正常连接过程中,主板异常,仅重新给扩展板发送连接命令,不影响扩展板正常运行。
can数据分为标准帧和扩展帧两种,简单需求标准帧格式足够,否则就需要扩展帧格式,扩展帧效率较低。针对我们的需求,综合权衡采用标准帧格式。
CAN帧中最关键的是ID组织,在我们的设计中,ID由几部分构成,包括帧类型(5bit),板编号(3bit),扩展(3bit,不同类型有不同的用途),CAN帧结构示意如下:
| ID | 内容 | 8BYTE |
|---|---|---|
| 00000 | 备用 | |
| 00001 | 备用 | |
| 00010 | 备用 | |
| 00011 | 备用 | |
| 00100 | SOE,最高优先级,因需用于保护 | soe信息 |
| 00101 | DO命令,因扩展板DO一般不用于出口,优先级适当降低。 | do状态 |
| 00110 | Soe数据确认 | |
| 00111 | Di状态 | DI状态 |
| 01000 | DO确认命令 | |
| 01001 | Ai裸数据,扩展位用于排序 | AI裸数据,WORD |
| 01010 | Ao裸数据,扩展位用于排序 | AO裸数据,WORD |
| 01011 | key数据 | key数据 |
| 01100 | led数据 | led状态 |
| 01101 | LCD数据传输完毕 | 地址x0,y0,x1,y1 |
| 01110 | lcd背光控制 | 背光状态 |
| 01111 | 备用 | |
| 10xxx | LCD数据,ID的其他信息用于表达LCD地址,2^(11-2)*8=4k>3200。 | lcd数据 |
| 11000 | 主板初始化建立连接报文 | 时间 |
| 11001 | 主板对时报文 | 时间 |
| 11010 | 板件类型应答报文 | 板类型,程序版本 |
| 11011 | Nop数据 | |
| 11100 | 备用 | |
| 11101 | 备用 | |
| 11110 | 备用 | |
| 11111 | 不允许使用,因can协议不允许全部为1的ID。 |
◇◇◇
随着需求的增加,老革命又碰到新问题了,CPU爆仓了,一些典型情况如下:
- 计算量越来越大,用户对性能的要求越来越高,单一CPU已经很难满足需求。
- 需求分化,有强实时和复杂通讯功能等多重要求,前者依赖强实时os,后者基于linux更好,但这两者基于不同的cpu。
- 某些特定的算法需要用到特定的芯片,如dsp等。
- 外围大量的数据预先计算缓存环节,如多通道高速长时间录波仪器(常用于监控分析设备运行工况)。
前面的一些分布式策略,仅分布出去一点枝枝叶叶,实现都相对简单。但面对cpu爆仓困局时,就要开始真正的分家了,也必然面对着各种撕裂般的阵痛。我个人感觉,布式架构设计的难点在于:整体程序拆分后的协调和同步。
我当初在跨国公司参与研发时,他们的分布式架构硬件体系如下:

整个硬件设计最多支持四个cpu(支持1、2、4三种组合),各cpu之间是通过双端口ram连接的。程序架构方面,因为经过多年迭代,程序已经被切分成了无数的可复用模块,可以通过配置软件将模块分布到各cpu。在这个过程中,配置软件会自动生成各cpu之间的数据接口参数表,然后由底层基础分布式模块负责这些接口数据的协调和同步。
虽然因工作分工原因,我没法了解其底层的工作细节,但这种分布机制依然让我震撼。从上层软件的角度看,都不需要去关心程序是在几个cpu上执行的。
最基础的分布式策略就是在各CPU之间构建规约,这也是我自己负责的产品中最初采用的策略。在实践过程中,发现这种策略有诸多弊端,如:
- 规约内容一般是固定的,内容排序一般难以动态调节,很难适应应用层的频繁动态变化。
- 规约中字节顺序和对齐机制等必须预先约定,但不同类型cpu之间规约通讯时,至少有一端需要进行字节转换,不仅程序实现复杂,执行效率也很低;
- 如果cpu比较多,内部需要好几个规约支撑,规约过多会导致整个程序体系结构被割裂。
- ……
后来,我们开始尝试基于消息机制的分布式系统,其示意图如下:

可以将基于消息的分布式架构认为是规约机制的一种提升优化,底层的各种分布式模块提炼了各种通讯例程,借助配置软件,可以动态传递各种数据类型。
此时,各应用模块面对的是分布的数据结构,直接拿来就可以使用,不再需要关心底层硬件和通讯的诸多细节。配置软件在该过程起的作用有点类似网络表示层的用途。
而且,基于消息机制,可以统一应用层的动态程序结构。每个应用模块都是一系列消息响应函数,不需要去关心这个消息来自于本cpu,还是其他cpu,这样的应用模块很容易分布到多个cpu上运行。在“动态执行架构”一节会进一步阐述。
借助基于消息的分布式架构,不仅装置主体的功能可以很容易的分布到多个板件上,也有助于重构整个系统的多个软件模块。如维护软件原先为了对设备进行维护,需要构建一个维护规约。有了分布式架构后,连维护规约也可以省略了。
◇◇◇
分布式系统架构已经属于比较高级的软件策略了,可能受集中式系统的惯性影响,刚开始会感觉不舒服,但一旦你能够迈过去,你将获取新生。
——————————————
我是小马儿,一个渴望良知与灵魂的嵌入式软件工程师,欢迎您的陪伴与同行,如感兴趣可加个人微信号nzn_xiaomaer交流,需备注“异维”二字。