第一部分:Storm的集群模式简介:
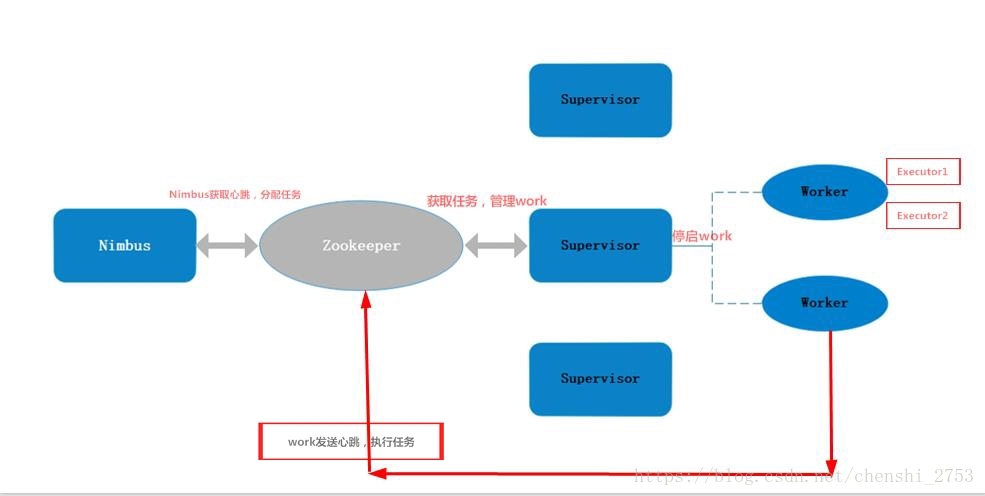
由Nimbus主节点发送
搭建过程介绍:
一、 单机版
环境准备:
Java 6+
Python 2.6.6+ // python -V 查看版本
搭建过程:
1.解压storm压缩包,在里面新建logs的文件。
2.通过查看help获取帮助执行。./bin/storm help
3.启动zk并设置日志输出:./bin/storm dev-zookeeper >> ./logs/dev-zookeeper.out 2>&1 &
解释:2表示错误信息 &1 输出到zookeeper.out 里。最后的& 表示,后台运行。并通过jps观察进程运行情况为先config_value,然后运行zookeeper。
4.启动numbus:./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &通过jps观察。
5.启动supervisor:./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &通过jps观察。
6.启动UI./bin/storm ui>> ./logs/ui.out 2>&1 &
7.任意,./bin/storm logviewer >> ./logs/logviewer.out 2>&1 &
9.查看其端口:ss -nal
8.通过web页面测试访问:node01:8080
9.生成的测试案例wordCount的jar上传到集群后,
./storm jar ~/testDemo/storm_wc.jar com.jw.storm.test.Test_cluster xxx
二、完全分布式(node02,node03,node04):
1.集群当中所有服务器,同步所有配置!(分发)
具体配置:修改 storm.zookeeper.servers:node02,node03,node04
以及 nimbus.host: “node02” storm.local.dir: “/tmp/storm”
最后配置supervisor的端口。
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
2.启动ZooKeeper集群
3.node2上启动Nimbus
启动:node02主节点上启动nimbus和ui。node03、node04上启动supervisor。
node02:
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
tail -f logs/nimbus.log
./bin/storm ui >> ./logs/ui.out 2>&1 &
tail -f logs/ui.log
node03:
节点node3和node4启动supervisor,按照配置,每启动一个supervisor就有了4个slots
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
tail -f logs/supervisor.log
(当然node2也可以启动supervisor)
全部启动完成后,启动其中一个节点的zookeeper的客户端(zkCli.sh)。通过ls /查看zk的目录。可发现有storm的目录。里面便是nimbus和zk之间的通讯存留的进程和心跳以及分配等信息。如下:
[zk: localhost:2181(CONNECTED) 5] ls /storm
[workerbeats, storms, supervisors, errors, assignments]
第二部分:Storm的并发机制简介:
Worker processes
Executors (threads)
Tasks
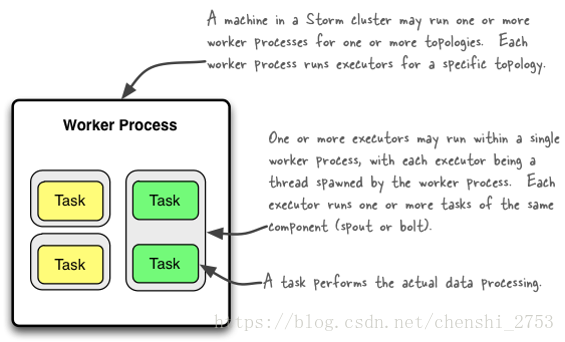
1、storm集群里,对于一个拓扑结构,一个节点可以运行一个或多个进程。每个进程可运行多个线程。
2、每个进程可运行一个或多个线程,每个线程里可运行多个任务(task)。
3、每个任务进行特定的数据处理。
总结来说即:
Worker – 进程
一个Topology拓扑会包含一个或多个Worker(每个Worker进程只能从属于一个特定的Topology)
这些Worker进程会并行跑在集群中不同的服务器上,即一个Topology拓扑其实是由并行运行在Storm集群中多台服务器上的进程所组成
Executor – 线程
Executor是由Worker进程中生成的一个线程
每个Worker进程中会运行拓扑当中的一个或多个Executor线程
一个Executor线程中可以执行一个或多个Task任务(默认每个Executor只执行一个Task任务),但是这些Task任务都是对应着同一个组件(Spout、Bolt)。
Task
实际执行数据处理的最小单元
每个task即为一个Spout或者一个Bolt
Task数量在整个Topology生命周期中保持不变,Executor数量可以变化或手动调整(默认情况下,Task数量和Executor是相同的,即每个Executor线程中默认运行一个Task任务)
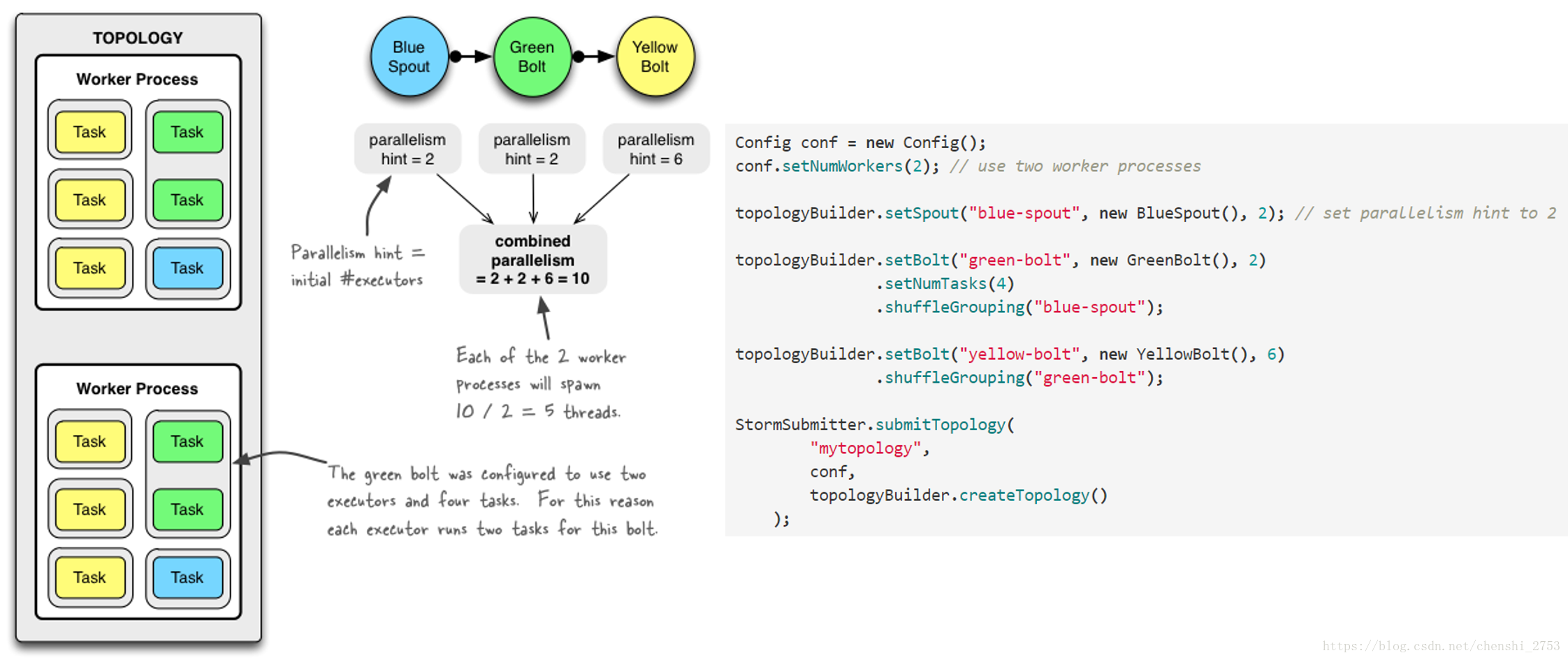
参数设置的说明:
设置Worker进程数
Config.setNumWorkers(int workers)
设置Executor线程数
TopologyBuilder.setSpout(String id, IRichSpout spout, Number parallelism_hint)
TopologyBuilder.setBolt(String id, IRichBolt bolt, Number parallelism_hint)
:其中, parallelism_hint即为executor线程数
设置Task数量
ComponentConfigurationDeclarer.setNumTasks(Number val)
例:
Config conf = new Config() ;
conf.setNumWorkers(2);
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.setSpout(“spout”, new MySpout(), 1);
topologyBuilder.setBolt(“green-bolt”, new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping(“blue-spout);
两种调整方式:
1.命令行控制:
./bin/storm rebalance wc -e WCountbolt = 4
备:(完整版)storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
说明:将mytopology拓扑worker进程数量调整为5个“ blue-spout ” 所使用的线程数量调整为3个
“ yellow-bolt ”所使用的线程数量调整为10个
然后通过Storm UI界面查看调整后的线程分布情况。(注意总的线程数会比操作设置的总数多,其中有acker的监控的线程,具体数量根据设置的bolt数量来定)
2.直接通过Storm UI 的rebalance控制。
Storm 通信机制:
原始的方式为witter发明的ZMQ,后被Apache的Netty替。
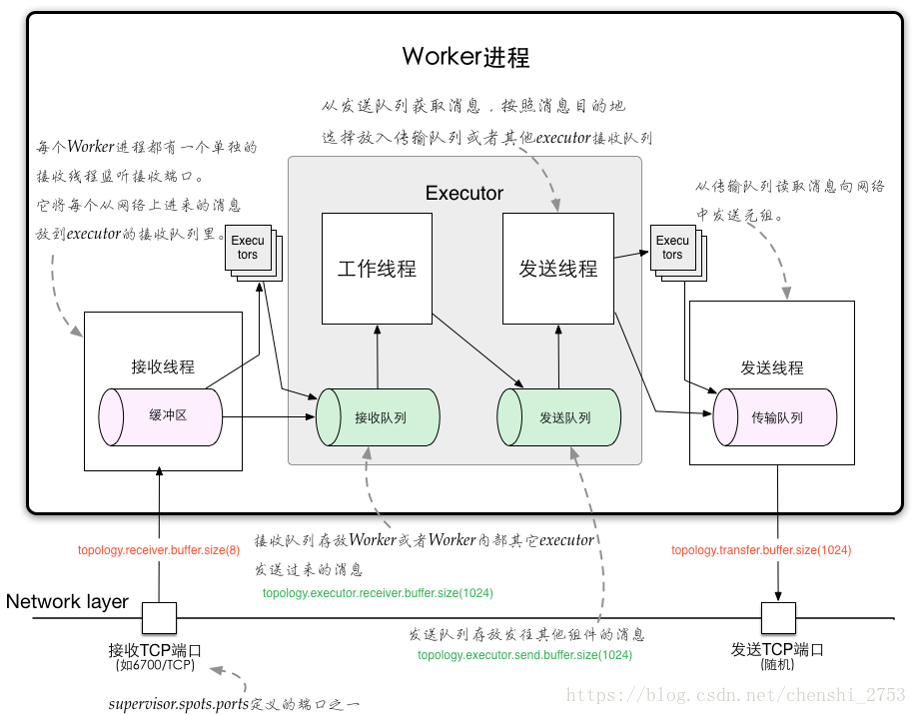
Worker进程间的数据通信
ZMQ
ZeroMQ 开源的消息传递框架,并不是一个MessageQueue
Netty
Netty是基于NIO的网络框架,更加高效。(之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。)
Worker内部的数据通信
Disruptor
实现了“队列”的功能。
可以理解为一种事件监听或者消息处理机制,即在队列当中一边由生产者放入消息数据,另一边消费者并行取出消息数据处理。
第三部分:Storm的容错机制简介:
首先明白一个问题,Nimbus为什么不做高可用?难道单节点没有单点故障的可能性吗?当然有的,Nimbus在整个集群中起到任务分配、资源调控、上传jar的作用,不想nameNode和dataNode之间密不可分的关系,NN上保存了元数据信息。而Nimbus把下面supervisor的信息放在了zookeeper里保存了。当Nimbus挂了,zookeeper和supervisor的关系并没有中断。分配完任务等完成没有其什么事儿了。虽然是主节点,但是任务比较轻,短时间来看对集群没大的影响。但是当其中有work挂了,zookeeper会通知Nimbus,其会分配其他的work去工作此work的任务。或者推送jar的时候NImbus挂了。但是没有它没不立刻影响这整个集群的运行。可手动启动。
其次,zookeeper的的单点问题,其可做成高可用。最后是supervisor的高可用,其是高可用的。当其中某个节点宕机了,跟zookeeper的心跳就会中断,然后zookeeper会通知Nimbus,Nimbus则通过zookeeper重新分配work任务到其他的supervisor上,当挂掉的supervisor活了以后,会记性自杀的方式,把之前在自己身上运行的work进行都杀掉。叫做自动销毁机制。防止重复操作。
最后是work的挂的问题,当work挂了,zookeeper会检查不到其心跳。首先会让supervisor尝试重启此work。如果失败zookeeper则分配此work的上的任务到其他的节点的supervisor来做。然后work也会有自动销毁的过程。
2个重要的API方法:
消息的完成性(ack标志信息完成成功,fail标志信息完成失败)
介绍:从Spout中发出的Tuple,以及基于他所产生Tuple(例如上个例子当中Spout发出的句子,以及句子当中单词的tuple等)
由这些消息就构成了一棵tuple树
当这棵tuple树发送完成,并且树当中每一条消息都被正确处理,就表明spout发送消息被“完整处理”,即消息的完整性。
对ack理解:
Acker – 消息完整性的实现机制
Storm的拓扑当中特殊的一些任务
负责跟踪每个Spout发出的Tuple的DAG(有向无环图)
备:需要提供messageId来追踪是否成功执行。
消息的保障机制,成功则调用ack方法,失败则调用fail方法。
第四部分:Storm的通信机制简介:
DRPC:分布式远程调用
其是通过一个 DRPC 服务端(DRPC server)来实现分布式 RPC 功能的。
客户端请求,DRPC服务接受请求,然后将请求发送给storm,由其计算完成的结果不是直接发给客户端的,而是通过DRPC服务来发送的。
DRPC设计目的:
为了是的大数据的结算实现快速返回客户端。
为了充分利用Storm的计算能力实现高密度的并行实时计算。
(Storm接收若干个数据流输入,数据在Topology当中运行完成,然后通过DRPC将结果进行输出。)
图解如下:
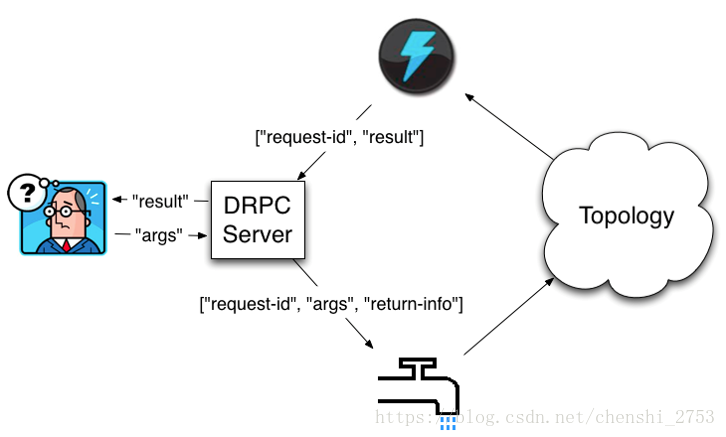
这里的requestId是表示多个客户端同时请求时候,能准确无误返回。
上方的闪电图标为resultBolt。
Storm的运行模式:
1.本地模式
TopologyBuilder builder = new TopologyBuilder();
LocalDRPC drpc = new LocalDRPC();
DRPCSpout spout = new DRPCSpout("exclamation", drpc);
builder.setSpout("drpc", spout);
builder.setBolt("exclaim", new ExclamationBolt(), 3).shuffleGrouping("drpc");
builder.setBolt("return", new ReturnResults(), 3).shuffleGrouping("exclaim");
LocalCluster cluster = new LocalCluster();
Config conf = new Config();
cluster.submitTopology("exclaim", conf, builder.createTopology());
System.err.println(drpc.execute("exclamation", "aaa"));
System.err.println(drpc.execute("exclamation", "bbb"));2.集群模式(远程模式)
修改配置文件conf/storm.yaml
drpc.servers:
- “node1“
启动DRPC Server
bin/storm drpc &
通过StormSubmitter.submitTopology提交拓扑