通信的目的是要把对方不知道的消息即时可靠地(有时还要秘密地)传送给对方。当信道中存在干扰,可能使发送的消息出错。数字通信中,通常使用纠错码技术来进行差错控制,这样可以提高数据传输的可靠性。
BCH码就是一种应用广泛的能纠正多重错误的分组码,具有极佳的纠错性能。本文对BCH码的原理进行深入分析,介绍BCH的编解码原理。重点介绍了BCH编码解码的计算方法以及BCH编码的性能分析。最后,本文采用MATLAB编写相应的BCH编解码代码进行仿真和误码率分析,并在Simulink中搭建BCH模块进行误码率统计分析。本文所作的研究成果具有一定的科研价值,为BCH的进一步研究或在硬件系统上的实现提供了良好的理论基础。
1.1 本课题研究背景
数字信号在传输系统中传输时,不可避免受到各种因素的干扰,使到达接收端的数字信号中混有噪声,从而引发错误判决,为了抗击干扰,必然要利用纠错码的差错控制技术。
纠错码的分类有以下几种:
·按照对信息序列处理方式的不同,分为分组码与卷积码两大类,在分组码中按照码的结构特点,又可分为循环码和非循环码。
·根据信息位与校验位之间的关系分为线性码与非线性码。
·按照适用的差错类型,分成纠随机差错码和纠突发差错码两种,也有介于中间的纠随机/突发差错码。
·按构码理论,有代数、几何、算术、组合码等。
除了上述分类外,有多少观察问题的角度,就有多少分类方法。比如,按每个码元的取值,可以分为二进制码与多进制码;按码字之间的关系,有循环码和非循环码之分;不同的分类方法只是从不同的角度抓住码的某一特性加以归类而己,并不能说明某个码的为全部特性。比如某线性码可能同时又是分组码,循环码,纠突发差错码,代数码,二进码。
1.2 线性分组码和循环码

线性分组码是分组码中最重要的一类码,用(n,k)表示,其中n表示码长,k表示信息位数目,n-k=r表示校验位数目,二进制(n,k)线性分组码可以定义为GF(2)域上的n维线性空间Vn中的一个k维子空间。
在线性分组码中有三个重要参数,分别为码率、码的汉明距离和汉明重量。码率R=k/n,它说明了分组码传输信息的有效性。码的汉明距离指两个码字对应位上码元不同的个数,简称距离。汉明重量指码字中非零码元的个数,简称重量。在(n,k)线性分组码中,将任两个码字距离的最小值称为最小距离d0。由于线性分组码是群码,由群码的封闭性可知,若码字C1,C2均是(n,k)码的码字,则C1+C2也必是该分组码的另一码字,可见(n,k)线性分组码的最小距离等于非零码字的最小重量。最小距离d。直接在理论上决定了该码的检错和纠错能力。
循环码是线性分组码中最重要的一个子类,它的代数结构比较清晰,编译码相对于其它码来讲简单且易于实现,因此循环码在差错控制系统中得到广泛的应用,BCH码就是循环码中很重要的一类码。
在GF(2)上的n维线性空间气中,若是的一个k维子空间,对任何,有,则是循环码。
由编码理论推导出的循环码纠错能力只是一个理论值,在现实中能否达到这个理论值还与所用的译码方法有关。一个好的译码方法,不仅应使纠错能力能够达到理论极限,而且应能高速度、低成本地实现,因为速度和成本有时会成为某种码能否实用的决定性因素。
译码电路通常要比编码电路复杂得多,因此我们说,理论的复杂性常体现在编码上,而工程的复杂性常体现在译码上。从对输入信号的量化程度,译码可分为硬判决译码(BSC信道)和软判决译码(DMC信道)。
软判决由于采用了大于2的量化级数,能更充分地利用接收信号包含的信息,与硬判决相比,在AWGN信道、10-2-10币误码率范围时可有2dB的编码增益,因此代表了译码的发展方向。从差错控制方式,译码可分为纠错和检错两种。纠错译码器总有输出,但有两种可能:一是收码的差错数量在纠错能力之内,译码器认定的正确真的是正确。二是差错数量超出纠错能力,译码器认定的正确其实是错的。由于难以判断差错数量是否超出纠错能力,纠错译码器不能保证输出数据完全可靠,所以纠错译码器常用于数字语音、图像、视频信号的前向纠错(FEC)中。
1.3 BCH编码的研究和应用
BCH码于1959年由霍昆格姆、1960年由博和雷-查德胡里三人分别提出,并以这三个发现者的名字命名。BCH码是迄今为止所发现的一类很好的线性纠错码类。它的纠错能力很强,特别在中等和短码长条件下,BCH码的性能接近理论上的最佳值,并且构造方便,编码简单。特别是它具有严密的代数结构,在代数编码理论中起着重要作用。BCH码是迄今为止研究得最为详尽、了解得最为透彻、取得成果最多的一类线性分组码。
1960年彼得逊从理论上解决了二进制BCH码的译码算法,奠定了BCH码译码的理论基础。稍后,格林斯坦和齐勒尔把它推广到多进制。1966年伯利坎普利用迭代算法译BCH码,从而大大加快了译码速度,从实际上解决了BCH码的译码问题。由于BCH码性能优良,结构简单,编译码设备也不太复杂,使得它在实际使用中受到工程技术人员的欢迎,是目前用得最广泛的码类之一。
在英国模拟移动通信系统中,基站采用了具有纠正2位随机错误能力的BCH(40,28)码,移动台采用了可纠正2位随机错误的BCH(48,36)码;在我国无线寻呼系统中,采用了BCH(31,21)码加一位奇偶校验位作为FEC方式;在视频编码协议H.261、H.263中采用了BCH(511,493)码进行视频纠错。
第三章 BCH码理论简介
3.1 BCH码简介
BCH码是循环码的一个重要子类,它具有纠多个错误的能力,BCH码有严密的代数理论,是目前研究最透彻的一类码。它的生成多项式与最小码距之间有密切的关系,人们可以根据所要求的纠错能力t很容易构造出BCH码,它们的译码器也容易实现,是线性分组码中应用最普遍的一类码。
3.1.1伽罗华域
编码原理中最基本、最重要的域是二元伽罗华域GF(2)及二元扩域GF(2m)。有限正数集合F={0,1,2,3,…,q-1}(q是素数)在模q加、模q乘运算下构成一个q阶有限域,又称伽罗华(Galois)域,记为GF(q)。当q=2时,就是二元域GF(2)。
在有限域中定义的运算满足闭合性,即有限域GF(q)上任意两个元素A、B对运算⊙满足:A⊙B∈GF(q)。
如果p是素数,m是正整数,GF(2m)的最小子域是GF(p),p称为GF(2m)的特征,在特征为2的伽罗华域中,任一域元素B有-B=B。
设B为GF(q)上的任一元素,则B=Bq。
每个伽罗华域GF(q)至少包含有一个本原元素α,且GF(q)上除零以外的其它任意域元素均可表示为本原元素的乘幂。
任一有限域均可由一本原多项式来构成,有限域的任一多项式对本原多项式求模,可得到一个次数低于本原多项式次数的多项式,即有限域的元素。
·加法运算
域元素的加法运算,即根据域元素表格,转换成对应的m-1次多项式系数(m重矢量)。两个域元素相加等效于两个m-1次多项式的同次项系数模2相加,即异或运算。
·乘法运算
乘法有三种实现途径:
第一就是把域元素对应的多项式系数直接移位,比如a×b,只要找到b对应的幂次,假设是x,将a左移x次,每次左移之前判断移位前的值高位是否为1,如果是1,移位后与本原多项式除高次幂后的多项式相加;
第二种方法就是从b的高位开始,如果b7=1,将a左移7次,如果b6=1,将前面左移结果再左移6次。
第三种方法是直接把域元素的指数相加求模2m-1。这里采用第三种方法。
·求模运算
因为2^m-1转换成二进制数永远是全1,所以根据这个特点,可以用下面的方法求模。把二进制形式的数从低位起每m比特分割,高位不满m比特用0补齐。然后高位段每出现一个1,就把高位减去1,然后把低位加1,这样循环操作直到高位段变成全0。




3.3 BCH译码理论介绍
BCH码的译码可以分为时域译码和频域译码两种。
频域译码是把码字看作一个时域数字序列,对其进行有限域的离散傅氏变换(DFT)将它变换到频域,然后利用其频域特点译码。这样通过对频域伴随式的运算解出指示差错位置的关键方程,再通过离散傅氏反变化还原成时域的纠错信号。
时域译码是把码字看作时间轴上的信号序列,利用码的代数结构进行译码。由于取有限域离散傅氏变换增加了复杂度,频域译码的实现一般较时域译码复杂,因此采用快速傅氏变换(FFT)的频域译码只在某些特殊情况下对特定码长(比如n等于2的幂次)的译码优于时域译码,而在一般情况下应用最广泛的是时域译码。其中BCH译码器的基本结构如下所示:
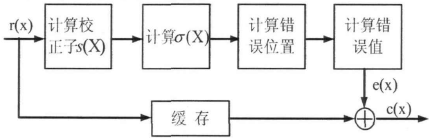
图3-1 BCH译码器基本结构框图
通常,我们在MATLAB中设计算法分三个步骤:
·STEP1:由接收到的R(x)计算出伴随式S;
·STEP2:由伴随式得出错误图样E(x);
·STEP3:由R(x)-E(x)得到估值码字c(x)。
5.2 BCH编码的系统仿真
我们根据前面的理论分析,编写MATLAB代码。这里,我们根据要求,进行(511,493)(4095,4035)两种参数的BCH编码,其MATLAB编码函数如下所示:
function code=bchencoder(data,genpoly,n,k);
bb=zeros(1,n-k);
for i=k:-1:1
feedback = xor(data(i), bb(n-k));
if feedback~=0
for j=n-k:-1:2
if genpoly(n-k-j+2)~=0
bb(j)=xor(bb(j-1),feedback);
else
bb(j)=bb(j-1);
end
end
bb(1)=feedback;
else
for j=n-k:-1:2
bb(j)=bb(j-1);
end
bb(1)=feedback;
end
end
code=[bb,data];
我们在顶层对其进行调用,调用过程如下代码:
for j=1:nwords
encoded_data((j-1)*n+1:(j-1)*n+n)=bchencoder(message((j-1)*k+1:(j-1)*k+k),genpoly,n,k);
end
输入信息为:
………… 1 1 0 1 1 0 0 1 1 1 …………………………
通过BCH编码之后,得到BCH编码信息:
………… 1 1 0 0 0 1 0 0 1 0 …………………………
5.3 BCH译码的系统仿真
本系统译码我们将采用应用十分普遍的‘钱搜索’法进行译码,前面我们已经简单的介绍了该算法, 其MATLAB代码实现过程如下所示:
lambda_v = zero;
accu_tb=gf(ones(1, t+1), m);
for i=1:n,
lambda_v=lambda*accu_tb';
accu_tb = accu_tb.*inverse_tb;
if(lambda_v==zero)
error(1,n-i+1)=1;
else
error(1,n-i+1)=0;
end
end
found = find(error(1,:)~=0);
for i=1:length(found)
location=found(i);
if location <= k;
rec_data(n-location+1)=rec_data(n-location+1)+one;
end
end
decoded_data((j-1)*k+1:(j-1)*k+k)=rec_data(n-k+1:n);
我们将编码之后得到的信号输入BCH译码部分,输出结果:
………… 1 1 0 1 1 0 0 1 1 1 …………………………
5.2.4 不同参数的BCH编解码性能分析
本章我们将重点对几种不同参数的BCH码进行了仿真。系统信噪比的分析我们主要采用:‘semilogy’进行仿真。我们分别对(511,493)(4095,4035)进行仿真,然后不改变n,k两个参数,改变其纠错能力进行仿真,从而判断BCH编解码的性能。

图5-1 n=511,k=493,t=11条件下信噪比

图5-2 n=4095,k=4035,t=11条件下信噪比

图5-3 BCH编码和不编码的性能对比(绿色为未通过编码)
从仿真结果可以看出,对于纠错能力相同的BCH码,码字长度短的相对码字长度长的性能好,且平均仿真一个码字所耗费的时间少。分析原因,是因为在相同的信道条件下,每个码元出现错误的概率是相同的,对于码字长度长的BCH码,平均每个码字中出现错误的码元个数多,所以对于纠错能力相同的BCH码,码字长度长的性能差。
以上我们详细介绍了MATLAB的BCH编解码和信噪比分析,下面我们将在Siumlink中进行BCH实际仿真,在本系统,我们将基于BPSK进行仿真分析。
不加BCH的BPSK系统如下所示:

图5-4 BPSK仿真系统
其仿真结果如下所示:
加入BCH编解码,其系统如下所示:

图5-5 BCH仿真系统
其仿真结果如下所示:

由上图可见,加上BCH编解码后,新能得到大大改善。
·编码和译码
clc;
clear;
close all;
m=9;%输入参数6
k=493;%输入参数4
snr=1;
n=2^m-1;
period=1000;
nwords = ceil(1000/k);
[genpoly,t] = bchgenpoly(n,k);
simplified = 1;
alpha = gf(2, m);
zero = gf(0, m);
one = gf(1, m);
message=randint(1,nwords*k);
message1=gf(message);
decoded_data=gf(zeros(1,nwords*k));
alpha_tb=gf(zeros(1, 2*t), m);
for i=1:2*t,
alpha_tb(i)=alpha^(2*t-i+1);
end;
%BCH编码
for j=1:nwords
encoded_data((j-1)*n+1:(j-1)*n+n)=bchencoder(message((j-1)*k+1:(j-1)*k+k),genpoly,n,k);%由高位到低位
end
%添加噪声
sigma=sqrt(1/(10^(snr/10))/2);
datalength=length(encoded_data);
snum=ceil(datalength/period);
for(i=1:snum-1)
data2((i-1)*period+1:(i-1)*period+period)=encoded_data((i-1)*period+1:(i-1)*period+period)+sigma*randn(1,period);
end
data2((snum-1)*period+1:datalength)=encoded_data((snum-1)*period+1:datalength)+sigma*randn(1,length(encoded_data((snum-1)*period+1:datalength)));
rec_data2=zeros(1,nwords*n);
for i=1:nwords*n
if abs(encoded_data(i)-data2(i))>0.5
rec_data2(i)=xor(encoded_data(i),1);
else
rec_data2(i)=encoded_data(i);
end
end
rec_data2=gf(rec_data2,m);
%BCH译码
for j=1:nwords
rec_data=rec_data2((j-1)*n+1:(j-1)*n+n);
syndrome=gf(zeros(1, 2*t), m);
for i=1:n,
syndrome=syndrome.*alpha_tb+rec_data(n-i+1);
end;
lambda = gf([1, zeros(1, t)], m);
lambda0= lambda;
b=gf([0, 1, zeros(1, t)], m);
b2 = gf([0, 0, 1, zeros(1, t)], m);
k1=0;
gamma = one;
delta = zero;
syndrome_array = gf(zeros(1, t+1), m);
if(simplified == 1)
for r=1:t,
r1 = 2*t-2*r+2;
r2 = min(r1+t, 2*t);
num = r2-r1+1;
syndrome_array(1: num) = syndrome(r1:r2);
delta = syndrome_array*lambda';
lambda0 = lambda;
lambda = gamma*lambda-delta*b2(2:t+2);
if((delta~= zero) && (k1>=0))
b2(3)=zero;
b2(4:3+t) = lambda0(1:t);
gamma = delta;
k1 = -k1;
else
b2(3:3+t) = b2(1:t+1);
gamma = gamma;
k1=k1+2;
end
joke=1;
end
else
for r=1:2*t,
r1 = 2*t-r+1;
r2 = min(r1+t, 2*t);
num = r2-r1+1;
syndrome_array(1:num) = syndrome(r1:r2);
delta = syndrome_array*lambda';
lambda0 = lambda;
lambda = gamma*lambda-delta*b(1:t+1);
if((delta ~= zero) && (k1>=0))
b(2:2+t)=lambda0;
gamma = delta;
k1=-k1-1;
else
b(2:2+t) = b(1:t+1);
gamma = gamma;
k1=k1+1;
end
joke=1;
end
end
inverse_tb = gf(zeros(1, t+1), m);
for i=1:t+1,
inverse_tb(i) = alpha^(-i+1);
end;
%钱搜索法
lambda_v = zero;
accu_tb=gf(ones(1, t+1), m);
for i=1:n,
lambda_v=lambda*accu_tb';
accu_tb = accu_tb.*inverse_tb;
if(lambda_v==zero)
error(1,n-i+1)=1;
else
error(1,n-i+1)=0;
end
end
found = find(error(1,:)~=0);
for i=1:length(found)
location=found(i);
if location <= k;
rec_data(n-location+1)=rec_data(n-location+1)+one;
end
end
decoded_data((j-1)*k+1:(j-1)*k+k)=rec_data(n-k+1:n);
end
·信噪比仿真
clc;
clear all;
close all;
%参数设置%(511,493)(4095.4035)
givenSNR=0.5:0.5:9.5; %]
% N=511;
% K=493;
N=4095;
K=4035;
T=11;
times=length(givenSNR);
%计算几个值
r=K/N;
Eb_N0=10.^(givenSNR./10);
sigma=(1./(2*r.*Eb_N0).^0.5);
message=randint(times,K,[0,1]);
msg=gf(message);
BCHcode_gf=bchenc(msg,N,K);
%BCH编码
BCHcode_double=-1*ones(times,N);
for code_i=1:times
for code_j=1:N
if BCHcode_gf(code_i,code_j)==1
BCHcode_double(code_i,code_j)=1;
end
end
end
%添加噪声
for noise_i=1:length(sigma)
BCH_receive(:,:,noise_i)=BCHcode_double+sigma(noise_i)*randn(times,N);
end
for noise_i=1:length(sigma)
for hard_i=1:times
for hard_j=1:N
if BCH_receive(hard_i,hard_j,noise_i)>0
hard_coded(hard_i,hard_j,noise_i)=1;
end
end
end
end
%BCH解码
BCHdecode=gf(zeros(times,K,length(sigma)));
for noise_i=1:length(sigma)
hard_BCH=hard_coded(:,:,noise_i);
[BCHdecode_i,error_num]=bchdec(gf(hard_BCH),N, K);
BCHdecode(:,:,noise_i)=BCHdecode_i;
end
BCHdecode_double=zeros(times,K);
for noise_i=1:length(sigma)
for gf_to_double_i=1:times
for gf_to_double_j=1:K
if BCHdecode(gf_to_double_i,gf_to_double_j,noise_i)==1
BCHdecode_double(gf_to_double_i,gf_to_double_j,noise_i)=1;
end
end
end
end
for noise_i=1:length(sigma)
error_BCHcoded_num(noise_i)=sum(sum((abs(BCHdecode_double(:,:,noise_i)-message))));
end
coded_error_rate=error_BCHcoded_num/times/K
semilogy(givenSNR,coded_error_rate,'-*');
ylabel('BER');
xlabel('Eb/N0');
grid on;