导言

图 1:编译顺序
Lex 为词法分析器或扫描器生成C程序代码。它使正则表达式匹配输入的字符串并且把它们转换成对应的标记(tokens)。标记通常是简化处理的字符串的数值表示。图1说明了这一点。
当 Lex 发现了输入流中的特定标记,就会把它们输入一个特定的符号表中。这个符号表也会包 含其它的信息,例如数据类型(整数或实数)和变量在内存中的位置。所有标记的实例都代表符号表中的一个适当的索引值。
Yacc 为语法分析器或剖析器生成C程序代码。Yacc 使用特定的语法规则以便解释从 Lex 得到的标记并且生成一棵语法树。语法树把各种标记当作分级结构。例如,操作符的优先级和相互关系在语 法树中是很明显的。下一步,生成编译器原代码,对语法树进行一次深度优先历遍以便生成原代 码。有一些编译器直接生成机器码,更多的,例如上图所示,输出汇编程序。
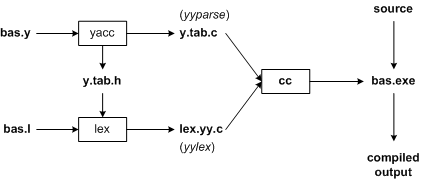
图2:用 Lex/Yacc 构建一个编译器
图2显示了 Lex 和 Yacc 使用的命名约定。我们首先要说明我们的目标是编写一个 BASIC 编译器。首先我们要指定 Lex 的所有的模式匹配规则(bas.l)和 Yacc 的全部语法规则(bas.y)。下面列 举了产生我们的编译器,bas.exe,的命令。
yacc -d bas.y # create y.tab.h, y.tab.c
lex bas.l # create lex.yy.c
cc lex.yy.c y.tab.c -obas.exe # compile/link
Yacc 读入 bas.y 中的语法描述而后生成一个剖析器,即 y.tab.c 中的函数 yyparse。bas.y 中包含的是一系列的标记声明。“d”选项使 Yacc 生成标记声明并且把它们保存在 y.tab.c 中。Lex 读入 bas.l 中的正则表达式的说明,包含文件 y.tab.h,然后生成词汇解释器,即文件 lex.yy.c 中的函数 yylex。
最终,这个解释器和剖析器被连接到一起,而组成一个可执行程序,bas.exe。我们从 main 函 数中调用 yyparse 来运行这个编译器。函数 yyparse 自动调用 yylex 以便获取每一个标志。
Lex
在第一阶段,编译器读入源代码然后把字符串转换成对应的标记。使用正则表达式,我们可以为 Lex 设计特定的表达式以便从输入代码中扫描和匹配字符串。在 Lex 上每一个字符串对应一个动 作。通常一个动作返回一个代表被匹配的字符串的标记给后面的剖析器使用。作为学习的开始,在此我们不返回标记而是简单的打印被匹配的字符串。我们要使用下面这个正则表达式扫描标识符。
letter(letter|digit)*这个表达式所匹配的字符串以一个简单字符串letter开头,后面跟随着零个或更多个letter或digit。这个 例子很好的显示了正则表达式中所允许的操作。
重复,用“*”表示
交替,用“|”表示
连接每一个正则表达式代表一个有限状态自动机 (FSA)。我们可以用状态和状态之间的转换来代表一个 FSA。其中包括一个开始状态以及一个或多个结束状态或接受状态。

图3 有限状态机
在图 3 中状态 0 是开始状态,而状态 2 是接受状态。当读入字符时,我们就进行状态转换。当读入 第一个字母时,程序转换到状态 1。如果后面读入的也是字母或数字,程序就继续保持在状态 1。 如果读入的字符不是字母或数字,程序就转换到状态 2,即接受状态。每一个 FSA 都表现为一个计算机程序。例如,我们这个 3 状态机器是比较容易实现的:
start: goto state0
state0: read c
if c = letter goto state1
goto state0
state1: read c
if c = letter goto state1
if c = digit goto state1
goto state2
state2: accept string这就是 lex 所使用的技术。lex 把正则表达式翻译成模拟 FSA 的一个计算机程序。通过搜索计算机 生成的状态表,很容易使用下一个输入字符和当前状态来判定下一个状态。 现在我们应该可以容易理解 lex 的一些使用限制了。例如 lex 不能用于识别像括号这样的外壳结 构。识别外壳结构需要使用一个混合堆栈。当我们遇到“(”时,就把它压入栈中。当遇到“)”时,我们就在栈的顶部匹配它,并且弹出栈。然而,lex 只有状态和状态转换能力。由于它没有堆 栈,它不适合用于剖析外壳结构。yacc 给 FSA 增加了一个堆栈,并且能够轻易处理像括号这样的 结构。重要的是对特定工作要使用合适的工具。lex 善长于模式匹配。yacc 适用于更具挑战性的工 作。
练习
| Pattern | Matches |
|---|---|
. |
any character except newline |
\. |
literal . |
\n |
newline |
\t |
tab |
^ |
beginning of line |
$ |
end of line |
表 1: 特殊字符
| Pattern | Matches |
|---|---|
? |
zero or one copy of the preceding expression |
* |
zero or more copies of the preceding expression |
+ |
one or more copies of the preceding expression |
a|b |
a or b (alternating) |
(ab)+ |
one or more copies of ab (grouping) |
abc |
abc |
abc* |
ab abc abcc abccc ... |
"abc*" |
literal abc* |
abc+ |
abc abcc abccc abcccc ... |
a(bc)+ |
abc abcbc abcbcbc ... |
a(bc)? |
a abc |
表 2: 操作符
| Pattern | Matches |
|---|---|
[abc] |
one of: a b c |
[a-z] |
any letter a through z |
[a\-z] |
one of: a - z |
[-az] |
one of: - a z |
[A-Za-z0-9]+ |
one or more alphanumeric characters |
[ \t\n]+ |
whitespace |
[^ab] |
anything except: a b |
[a^b] |
one of: a ^ b |
[a|b] |
one of: a | b |
表3 字符类
正则表达式通常用来进行模式匹配,一个字符类定义一个字符,而普通的操作符会失去它们的意义。字符类中支持的两个操作符是连字符(“-”)和取反(“^”)。当把连字号用于两个字符中间时,表示字符的范围。当把取反号用在开始位置时,表示对后面的表达式取 反。如果两个范式匹配相同的字符串,就会使用匹配长度最长的范式。如果两者匹配的长度相同, 就会选用第一个列出的范式。
... 定义 ...
%%
... 规则 ...
%%
... 子程序 ...lex 的输入文件分成三个段,段间用 %% 来分隔。上例很好的表明了这个意思。第一个例子是最短的可用 lex 文件如下:
%%输入字符将被一个字符一个字符直接输出。由于必须存在一个规则段,第一个 %% 总是要求存在 的。然而,如果我们不指定任何规则,默认动作就是匹配任意字符然后直接输出到输出文件。默认 的输入文件和输出文件分别是 stdin 和 stdout。下面是效果完全相同的例子,显式表达了默认代码:
%%
/* match everything except newline */
. ECHO;
/* match newline */
\n ECHO;
%%
int yywrap(void) {
return 1;
}
int main(void) {
yylex();
return 0;
}
上面规则段中指定了两个范式。每一个范式必须从第一列开始。紧跟后面的必须是空白区(空格, TAB 或换行),以及对应的任意动作。动作可以是单行的 C 代码,也可以是括在花括号中的多行 C 代码。任何不是从第一列开始的字符串都会被逐字拷贝进所生成的 C 文件中。我们可以利用这个特 殊行为在我们的 lex 文件中增加注释。在上例中有“.”和“\n”两个范式,对应的动作都是 ECHO。lex 预先字义了一些宏和变量。ECHO 就是一个用于直接输出范式所匹配的字符的宏。这也 是对任何未匹配字符的默认动作。通常 ECHO 是这样定义的:
#define ECHO fwrite(yytext, yyleng, 1, yyout)变量 yytext 是指向所匹配的字符串的指针(以 NULL 结尾),而 yyleng 是这个字符串的长度。变量yyout 是输出文件,默认状态下是 stdout。当 lex 读完输入文件之后就会调用函数 yywrap。如果返回 1 表示程序的工作已经完成了,否则返回 0。每一个 C 程序都要求一个 main 函数。在本例中我们只 是简单地调用 yylex,lex 扫描器的入口。有些 lex 实现的库中包含了 main 和 yywrap。这就是为什 么我们的第一个例子,最短的 lex 程序,能够正确运行。
| Name | Function |
|---|---|
int yylex(void) |
call to invoke lexer, returns token |
char *yytext |
pointer to matched string |
yyleng |
length of matched string |
yylval |
value associated with token |
int yywrap(void) |
wrapup, return 1 if done, 0 if not done |
FILE *yyout |
output file |
FILE *yyin |
input file |
INITIAL |
initial start condition |
BEGIN condition |
switch start condition |
ECHO |
write matched string |
表4 lex预定义的变量
下面是一个根本什么都不干的程序。所有输入字符都被匹配了,但是所有范式都没有定义对应的动作,所以没有任何输出。
%%
.
\n下面的例子在文件的每一行前面插入行号。有些 lex 实现预先定义和计算了 yylineno 变量。输入文 件是 yyin,默认指向 stdin。
%{
int yylineno;
%}
%%
^(.*)\n printf("%4d\t%s", ++yylineno, yytext);
%%
int main(int argc, char *argv[]) {
yyin = fopen(argv[1], "r");
yylex();
fclose(yyin);
}定义段由替换式(substitutions)、C 代码和开始状态构成(start states)。定义段中的 C 代码被简单地原样复制到生成的 C 文件的顶部,而且必须用 %{ 和 %} 括起来。替代式简化了正则表达式匹配规则。例如,我们可以定义数字和字母:
digit [0-9]
letter [A-Za-z]
%{
int count;
%}
%%
/* match identifier */
{letter}({letter}|{digit})* count++;
%%
int main(void) {
yylex();
printf("number of identifiers = %d\n", count);
return 0;
}
范式和对应的表达式必须用空白区分隔开。在规则段中,替代式要用花括号括起来(如 {letter}) 以便和其字面意思区分开来。每当匹配到规则段中的一个范式,与之相对应的 C 代码就会被运行。 下面是一个扫描器,用于计算一个文件中的字符数,单词数和行数(类似 Unix 中的 wc 程序):
%{
int nchar, nword, nline;
%}
%%
\n { nline++; nchar++; }
[^ \t\n]+ { nword++, nchar += yyleng; }
. { nchar++; }
%%
int main(void) {
yylex();
printf("%d\t%d\t%d\n", nchar, nword, nline);
return 0;
}YACC
yacc 的文法由一个使用 BNF 文法(BackusNaur form)的变量描述。BNF 文法规则最初由 John Backus 和 Peter Naur 发明,并且用于描述 Algol60 语言。BNF 能够用于表达上下文无关语言。现代 程序语言中的大多数结构可以用 BNF 文法来表达。例如,数值相乘和相加的文法是:
1 E -> E + E
2 E -> E * E
3 E -> id上面举了三个产生式(productions),代表三条规则(依次为 r1,r2,r3)。像 E(表达式)这样出现在产生式左边的结构叫 非终结符(nonterminal)。像 id(标识符)这样的结构叫终结符(terminal,由 lex 返回的标记),它们只出现在产生式右边。这段文法表示,一个表达式可以是两个表达式的和、乘积,或者是一个标识符。 我们可以用这种文法来构造下面的表达式:
E -> E * E (r2)
-> E * z (r3)
-> E + E * z (r1)
-> E + y * z (r3)
-> x + y * z (r3)每一步我们都扩展了一个语法结构,用对应的右式替换了左式。右面的数字表示应用了哪条规则。 为了剖析一个表达式,我们实际上需要进行倒序操作。不是从一个简单的非终结符开始和根据语法生成一个表达式,而是把一个表达式逐步简化成一个非终结符。这叫做“自底向上”或者“移进 归约”分析法,这需要一个堆栈来保存信息。下面就是用相反的顺序细述了和上例相同的语法:
1 . x + y * z shift
2 x . + y * z reduce(r3)
3 E . + y * z shift
4 E + . y * z shift
5 E + y . * z reduce(r3)
6 E + E . * z shift
7 E + E * . z shift
8 E + E * z . reduce(r3)
9 E + E * E . reduce(r2) emit multiply
10 E + E . reduce(r1) emit add
11 E . accept
点左面的结构在堆栈中,而点右面的是剩余的输入信息。我们以把标记移入堆栈开始。当堆栈顶部和右式要求的记号匹配时,我们就用左式取代所匹配的标记。概念上,匹配右式的标记被弹出堆栈,而左式被压入堆栈。我们把所匹配的标记认为是一个句柄,而我们所做的就是把句柄向左式归 约。这个过程一直持续到把所有输入都压入堆栈中,而最终堆栈中只剩下最初的非终结符。在第 1步中我们把 x 压入堆栈中。第 2 步对堆栈应用规则 r3,把 x 转换成 E。然后继续压入和归约,直到 堆栈中只剩下一个单独的非终结符,开始符号。在第 9 步中,我们应用规则 r2,执行乘法指令。同 样,在第 10 步中执行加法指令。这种情况下,乘法就比加法拥有了更高的优先级。 考虑一下,如果我们在第 6 步时不是继续压入,而是马上应用规则 r1 进行归约。这将导致加法比 乘法拥有更高的优先级。这叫做“移进 归约”冲突(shiftreduce conflict)。我们的语法模糊不 清,对一个表达式可以引用一条以上的适用规则。在这种情况下,操作符优先级就可以起作用了。 举另一个例子,可以想像在这样的规则中:
E -> E + E 是模糊不清的,因为我们既可以从左面又可以从右面递归。为了挽救这个危机,我们可以重写语法 规则,或者给 yacc 提供指示以明确操作符的优先顺序。后面的方法比较简单,我们将在练习段中 进行示范。
下面的语法存在“归约 归约”冲突 (reducereduce conflict)。当堆栈中存在 id 是,我们既可以归约 为 T,也可以归约为 E。
E -> T
E -> id
T -> id当存在冲突时,yacc 将执行默认动作。当存在“移进 归约”冲突时,yacc 将进行移进。当存在 “归约 归约”冲突时,yacc 将执行列出的第一条规则。对于任何冲突,它都会显示警告信息。只 有通过书写明确的语法规则,才能消灭警告信息。后面的章节中我们将会介绍一些消除模糊性的方 法。
练习1
... 定义 ...
%%
... 规则 ...
%%
... 子程序 ...yacc 的输入文件分成三段。“定义”段由一组标记声明和括在“%{”和“%}”之间的 C 代码组 成。BNF 语法定义放在“规则”段中,而用户子程序添加在“子程序”段中。 构造一个小型的加减法计算器可以最好的说明这个意思。我们要以检验 lex 和 yacc 之间的联系开始 我们的学习。下面是 yacc 输入文件的定义段:
%token INTEGER上面的定义声明了一个 INTEGER 标记。当我们运行 yacc 时,它会在 y.tab.c 中生成一个剖析器, 同时会产生一个包含文件 y.tab.h:
#ifndef YYSTYPE
#define YYSTYPE int
#endif
#define INTEGER 258
extern YYSTYPE yylval;lex 文件要包含这个头文件,并且使用其中对标记值的定义。为了获得标记,yacc 会调用 yylex。 yylex 的返回值类型是整型,可以用于返回标记(token)。而在变量 yylval 中保存着与返回的标记相对应的值。例如,
[0-9]+ {
yylval = atoi(yytext);
return INTEGER;
}将把整数的值保存在 yylval 中,同时向 yacc 返回标记 INTEGER。yylval 的类型由 YYSTYPE决定。由于它的默认类型是整型,所以在这个例子中程序运行正常。0-255 之间的标记值约定为字符值。例如,如果你有这样一条规则
[-+] return *yytext; /* return operator */减号和加号的字符值将会被返回。注意我们必须把减号放在第一位心避免出现范围指定错误。 由于 lex 还保留了像“文件结束”和“错误过程”这样的标记值,生成的标记值通常从 258 左右开 始。下面是为我们的计算器设计的完整的 lex 输入文件:
%{
#include "y.tab.h"
#include <stdlib.h>
void yyerror(char *);
%}
%%
[0-9]+ {
yylval = atoi(yytext);
return INTEGER;
}
[-+\n] return *yytext;
[ \t] ; /* skip whitespace */
. yyerror("invalid character");
%%
int yywrap(void) {
return 1;
}
yacc 在内部维护着两个堆栈:一个分析栈和一个内容栈。分析栈中保存着终结符和非终结符, 并且代表当前剖析状态。内容栈是一个 YYSTYPE 元素的数组,对于分析栈中的每一个元素都保存 着一个对应的值。例如,当 yylex 返回一个 INTEGER 标记时,yacc 把这个标记移入分析栈。同 时,相应的 yylval 值将会被移入内容栈中。分析栈和内容栈的内容总是同步的,因此从栈中找到对 应于一个标记的值是很容易实现的。下面是为我的计算器设计的 yacc 输入文件:
%{
#include <stdio.h>
int yylex(void);
void yyerror(char *);
%}
%token INTEGER
%%
program:
program expr '\n' { printf("%d\n", $2); }
|
;
expr:
INTEGER { $$ = $1; }
| expr '+' expr { $$ = $1 + $3; }
| expr '-' expr { $$ = $1 - $3; }
;
%%
void yyerror(char *s) {
fprintf(stderr, "%s\n", s);
}
int main(void) {
yyparse();
return 0;
}规则段的方法类似前面讨论过的 BNF 文法。产生式的左侧、或称为非终结符,从最左边开始,后面紧跟着一个冒号。后面跟着的是右式。与规则相应的动 作写在后面的花括号中。
通过利用左递归(一共有两种地柜:左递归和右递归),我们已经指定一个程序由 0 个或更多个表达式构成。每一个表达式由换行结 束。当探测到换行符时,程序就会打印出表达式的结果。当程序应用下面这个规则时
expr: expr '+' expr { $$ = $1 + $3; }在分析栈中我们其实用左式替代了右式。在本例中,我们弹出“expr '+' expr”然后压入 “expr”。我们通过弹出三个成员,压入一个成员缩小的堆栈。在我们的 C 代码中可以用通过相对 地址访问内容栈中的值,“$1”代表右式中的第一个成员,“$2”代表第二个,后面的以此类推。“$ $”表示缩小后的堆栈的顶部。在上面的动作中,把对应两个表达式的值相加,弹出内容栈中的三 个成员,然后把造得到的和压入堆栈中。这样,分析栈和内容栈中的内容依然是同步的。
当我们把 INTEGER 归约到 expr 时,数字值开始被输入内容栈中。当 NTEGER 被移分析栈中 之后,我们会就应用这条规则
expr: INTEGER { $$ = $1; }INTEGER 标记被弹出分析栈,然后压入一个 expr。对于内容栈,我们弹出整数值,然后又把 它压回去。也可以说,我们什么都没做。事实上,这就是默认动作,不需要专门指定。当遇到换行 符时,与 expr 相对应的值就会被打印出来。当遇到语法错误时,yacc 会调用用户提供的 yyerror 函 数。如果你需要修改对 yyerror 的调用界面,改变 yacc 包含的外壳文件以适应你的需求。你的 yacc 文件中的最后的函数是 main ... 万一你奇怪它在哪里的话。这个例子仍旧有二义性的语法。yacc 会 显示“移进 归约”警告,但是依然能够用默认的移进操作处理语法。
练习2
在本段中我们要扩展前一段中的计算器以便加入一些新功能。新特性包括算术操作乘法和除法。圆括号可以用于改变操作的优先顺序,并且可以在外部定义单字符变量的值。下面举例说明了 输入量和计算器的输出:
user: 3 * (4 + 5)
calc: 27
user: x = 3 * (4 + 5)
user: y = 5
user: x
calc: 27
user: y
calc: 5
user: x + 2*y
calc: 37词汇解释器将返回VARIABLE和INTEGER标志。对于变量,yylval 指定一个到我们的符号表sym中的索引。对于这个程序,sym仅仅保存对应变量的值。当返回INTEGER标志时,yylval 保存扫描到的数值。这里是 lex 输入文件:
%{
#include <stdlib.h>
#include "y.tab.h"
void yyerror(char *);
%}
%%
/* variables */
[a-z] {
yylval = *yytext - 'a';
return VARIABLE;
}
/* integers */
[0-9]+ {
yylval = atoi(yytext);
return INTEGER;
}
/* operators */
[-+()=/*\n] { return *yytext; }
/* skip whitespace */
[ \t] ;
/* anything else is an error */
. yyerror("invalid character");
%%
int yywrap(void) {
return 1;
}接下来是 yacc 的输入文件。yacc 利用 INTEGER和 VARIABLE的标记在 y.tab.h中生成 #defines 以便在 lex 中使用。这跟在算术操作符定义之后。我们可以指定%left ,表示左结合,或者 用%right 表示右结合。最后列出的定义拥有最高的优先权。因此乘法和除法拥有比加法和减法更 高的优先权。所有这四个算术符都是左结合的。运用这个简单的技术,我们可以消除文法的歧义。
%token INTEGER VARIABLE
%left '+' '-'
%left '*' '/'
%{
void yyerror(char *);
int yylex(void);
int sym[26];
%}
%%
program:
program statement '\n'
|
;
statement:
expr { printf("%d\n", $1); }
| VARIABLE '=' expr { sym[$1] = $3; }
;
expr:
INTEGER
| VARIABLE { $$ = sym[$1]; }
| expr '+' expr { $$ = $1 + $3; }
| expr '-' expr { $$ = $1 - $3; }
| expr '*' expr { $$ = $1 * $3; }
| expr '/' expr { $$ = $1 / $3; }
| '(' expr ')' { $$ = $2; }
;
%%
void yyerror(char *s) {
fprintf(stderr, "%s\n", s);
}
int main(void) {
yyparse();
return 0;
}计算器
描述
这个版本的计算器的复杂度大大超过了前一个版本。主要改变包括像ifelse 和while这样的控制 结构。另外,在剖析过程中还构造了一个语法树。剖析完成之后,我们历遍语法树来生成输出。此 处提供了两个版本的树历遍程序:一个在历遍树的过程中执行树中的声明的解释器,以及一个为基于堆栈的计算机生成代码的编译器。 为了使我们的解释更加形象,这里有一个例程,
x = 0;
while (x < 3) {
print x;
x = x + 1;
}解释版本的输出数据:
0
1
2编译版本的输出数据:
push 0
pop x
L000:
push x
push 3
compLT
jz L001
push x
print
push x
push 1
add
pop x
jmp L000
L001:生成语法树的版本输出:
[=]
|
|----|
| |
id(X) c(0)
Graph 1:
while
|
|----------------|
| |
[<] [;]
| |
|----| |----------|
| | | |
id(X) c(3) print [=]
| |
| |-------|
| | |
id(X) id(X) [+]
|
|----|
| |
id(X) c(1)
包含文件中包括了对语法树和符号表的定义。符号表 sym 允许使用单个字符表示变量名。语法 树中的每个节点保存一个常量(conNodeType)、标识符(idNodeType)、或者一个带算子 (oprNodeType)的内部节点。所有这三种变量压缩在一个 union 结构中,而节点的具体类型跟据 其内部所拥有的结构来判断。
lex 输入文件中包含有返回 VARIABLE 和 INTEGER 标志的正则表达式。另外,也定义了像 EQ 和 NE 这样的双字符算子的标志。对于单字符算子,只需简单地返回其本身。
yacc 输入文件中定义了 YYSTYPE,yylval 的类型,定义如下
%union {
int iValue; /* integer value */
char sIndex; /* symbol table index */
nodeType *nPtr; /* node pointer */
};
这将导致在 y.tab.h 中生成如下代码:
typedef union {
int iValue; /* integer value */
char sIndex; /* symbol table index */
nodeType *nPtr; /* node pointer */
} YYSTYPE;
extern YYSTYPE yylval;在剖析器的内容栈中,常量、变量和节点都可以由 yylval 表示。
0 {
yylval.iValue = atoi(yytext);
return INTEGER;
}
[1-9][0-9]* {
yylval.iValue = atoi(yytext);
return INTEGER;
}
注意下面的定义:
%token <iValue> INTEGER
%type <nPtr> expr这把 expr 和 INTEGER 分别绑定到 union 结构 YYSTYPE 中的 nPtr 和 iValue 成员。这是必须的,只有这样 yacc 才能生成正确的代码。例如,这个规则:
expr: INTEGER { $$ = con($1); }可以生成下面的代码。注意,yyvsp[0] 表示内容栈的顶部,或者表示对应于 INTEGER 的值。
yylval.nPtr = con(yyvsp[0].iValue);一元算子的优先级比二元算子要高,如下所示:
%left GE LE EQ NE '>' '<'
%left '+' '-'
%left '*' '/'
%nonassoc UMINUS%nonassoc 意味着没有依赖关系。它经常在连接词中和 %prec 一起使用,用于指定一个规则的 优先级。因此,我们可以这样:
expr: '' expr %prec UMINUS { $$ = node(UMINUS, 1, $2); }表示这条规则的优先级和标志 UMINUS 相同。而且,如同上面所定义的,UMINUS 的优先级比其 它所有算子都高。类似的技术也用于消除 ifelse 结构中的二义性(请看 ifelse 二义性)。
语法树是从底向上构造的,当变量和整数减少时才分配叶节点。当遇到算子时,就需要分配一 个节点,并且把上一个分配的节点作为操作数记录在其中。
构造完语法树之后,调用函数 ex 对此语法树进行第一深度历遍。第一深度历遍按照原先节点 分配的顺序访问各节点。
这将导致各算子按照剖析期间的访问顺序被使用。此处含有三个版本的 ex 函数:一个解释版 本,一个编译版本,一个用于生成语法树的版本。
包含文件
typedef enum { typeCon, typeId, typeOpr } nodeEnum;
/* constants */
typedef struct {
int value; /* value of constant */
} conNodeType;
/* identifiers */
typedef struct {
int i; /* subscript to sym array */
} idNodeType;
/* operators */
typedef struct {
int oper; /* operator */
int nops; /* number of operands */
struct nodeTypeTag *op[1]; /* operands, extended at runtime */
} oprNodeType;
typedef struct nodeTypeTag {
nodeEnum type; /* type of node */
union {
conNodeType con; /* constants */
idNodeType id; /* identifiers */
oprNodeType opr; /* operators */
};
} nodeType;
extern int sym[26];Lex 输入文件
%{
#include <stdlib.h>
#include "calc3.h"
#include "y.tab.h"
void yyerror(char *);
%}
%%
[a-z] {
yylval.sIndex = *yytext - 'a';
return VARIABLE;
}
0 {
yylval.iValue = atoi(yytext);
return INTEGER;
}
[1-9][0-9]* {
yylval.iValue = atoi(yytext);
return INTEGER;
}
[-()<>=+*/;{}.] {
return *yytext;
}
">=" return GE;
"<=" return LE;
"==" return EQ;
"!=" return NE;
"while" return WHILE;
"if" return IF;
"else" return ELSE;
"print" return PRINT;
[ \t\n]+ ; /* ignore whitespace */
. yyerror("Unknown character");
%%
int yywrap(void) {
return 1;
}Yacc 输入文件
%{
#include <stdio.h>
#include <stdlib.h>
#include <stdarg.h>
#include "calc3.h"
/* prototypes */
nodeType *opr(int oper, int nops, ...);
nodeType *id(int i);
nodeType *con(int value);
void freeNode(nodeType *p);
int ex(nodeType *p);
int yylex(void);
void yyerror(char *s);
int sym[26]; /* symbol table */
%}
%union {
int iValue; /* integer value */
char sIndex; /* symbol table index */
nodeType *nPtr; /* node pointer */
};
%token <iValue> INTEGER
%token <sIndex> VARIABLE
%token WHILE IF PRINT
%nonassoc IFX
%nonassoc ELSE
%left GE LE EQ NE '>' '<'
%left '+' '-'
%left '*' '/'
%nonassoc UMINUS
%type <nPtr> stmt expr stmt_list
%%
program:
function { exit(0); }
;
function:
function stmt { ex($2); freeNode($2); }
| /* NULL */
;
stmt:
';' { $$ = opr(';', 2, NULL, NULL); }
| expr ';' { $$ = $1; }
| PRINT expr ';' { $$ = opr(PRINT, 1, $2); }
| VARIABLE '=' expr ';' { $$ = opr('=', 2, id($1), $3); }
| WHILE '(' expr ')' stmt { $$ = opr(WHILE, 2, $3, $5); }
| IF '(' expr ')' stmt %prec IFX { $$ = opr(IF, 2, $3, $5); }
| IF '(' expr ')' stmt ELSE stmt { $$ = opr(IF, 3, $3, $5, $7); }
| '{' stmt_list '}' { $$ = $2; }
;
stmt_list:
stmt { $$ = $1; }
| stmt_list stmt { $$ = opr(';', 2, $1, $2); }
;
expr:
INTEGER { $$ = con($1); }
| VARIABLE { $$ = id($1); }
| '-' expr %prec UMINUS { $$ = opr(UMINUS, 1, $2); }
| expr '+' expr { $$ = opr('+', 2, $1, $3); }
| expr '-' expr { $$ = opr('-', 2, $1, $3); }
| expr '*' expr { $$ = opr('*', 2, $1, $3); }
| expr '/' expr { $$ = opr('/', 2, $1, $3); }
| expr '<' expr { $$ = opr('<', 2, $1, $3); }
| expr '>' expr { $$ = opr('>', 2, $1, $3); }
| expr GE expr { $$ = opr(GE, 2, $1, $3); }
| expr LE expr { $$ = opr(LE, 2, $1, $3); }
| expr NE expr { $$ = opr(NE, 2, $1, $3); }
| expr EQ expr { $$ = opr(EQ, 2, $1, $3); }
| '(' expr ')' { $$ = $2; }
;
%%
nodeType *con(int value) {
nodeType *p;
/* allocate node */
if ((p = malloc(sizeof(nodeType))) == NULL)
yyerror("out of memory");
/* copy information */
p->type = typeCon;
p->con.value = value;
return p;
}
nodeType *id(int i) {
nodeType *p;
/* allocate node */
if ((p = malloc(sizeof(nodeType))) == NULL)
yyerror("out of memory");
/* copy information */
p->type = typeId;
p->id.i = i;
return p;
}
nodeType *opr(int oper, int nops, ...) {
va_list ap;
nodeType *p;
int i;
/* allocate node, extending op array */
if ((p = malloc(sizeof(nodeType) + (nops-1) * sizeof(nodeType *))) == NULL)
yyerror("out of memory");
/* copy information */
p->type = typeOpr;
p->opr.oper = oper;
p->opr.nops = nops;
va_start(ap, nops);
for (i = 0; i < nops; i++)
p->opr.op[i] = va_arg(ap, nodeType*);
va_end(ap);
return p;
}
void freeNode(nodeType *p) {
int i;
if (!p) return;
if (p->type == typeOpr) {
for (i = 0; i < p->opr.nops; i++)
freeNode(p->opr.op[i]);
}
free (p);
}
void yyerror(char *s) {
fprintf(stdout, "%s\n", s);
}
int main(void) {
yyparse();
return 0;
}解释器版本
#include <stdio.h>
#include "calc3.h"
#include "y.tab.h"
int ex(nodeType *p) {
if (!p) return 0;
switch(p->type) {
case typeCon: return p->con.value;
case typeId: return sym[p->id.i];
case typeOpr:
switch(p->opr.oper) {
case WHILE: while(ex(p->opr.op[0])) ex(p->opr.op[1]); return 0;
case IF: if (ex(p->opr.op[0]))
ex(p->opr.op[1]);
else if (p->opr.nops > 2)
ex(p->opr.op[2]);
return 0;
case PRINT: printf("%d\n", ex(p->opr.op[0])); return 0;
case ';': ex(p->opr.op[0]); return ex(p->opr.op[1]);
case '=': return sym[p->opr.op[0]->id.i] = ex(p->opr.op[1]);
case UMINUS: return -ex(p->opr.op[0]);
case '+': return ex(p->opr.op[0]) + ex(p->opr.op[1]);
case '-': return ex(p->opr.op[0]) - ex(p->opr.op[1]);
case '*': return ex(p->opr.op[0]) * ex(p->opr.op[1]);
case '/': return ex(p->opr.op[0]) / ex(p->opr.op[1]);
case '<': return ex(p->opr.op[0]) < ex(p->opr.op[1]);
case '>': return ex(p->opr.op[0]) > ex(p->opr.op[1]);
case GE: return ex(p->opr.op[0]) >= ex(p->opr.op[1]);
case LE: return ex(p->opr.op[0]) <= ex(p->opr.op[1]);
case NE: return ex(p->opr.op[0]) != ex(p->opr.op[1]);
case EQ: return ex(p->opr.op[0]) == ex(p->opr.op[1]);
}
}
return 0;
}编译器版本
#include <stdio.h>
#include "calc3.h"
#include "y.tab.h"
static int lbl;
int ex(nodeType *p) {
int lbl1, lbl2;
if (!p) return 0;
switch(p->type) {
case typeCon:
printf("\tpush\t%d\n", p->con.value);
break;
case typeId:
printf("\tpush\t%c\n", p->id.i + 'a');
break;
case typeOpr:
switch(p->opr.oper) {
case WHILE:
printf("L%03d:\n", lbl1 = lbl++);
ex(p->opr.op[0]);
printf("\tjz\tL%03d\n", lbl2 = lbl++);
ex(p->opr.op[1]);
printf("\tjmp\tL%03d\n", lbl1);
printf("L%03d:\n", lbl2);
break;
case IF:
ex(p->opr.op[0]);
if (p->opr.nops > 2) {
/* if else */
printf("\tjz\tL%03d\n", lbl1 = lbl++);
ex(p->opr.op[1]);
printf("\tjmp\tL%03d\n", lbl2 = lbl++);
printf("L%03d:\n", lbl1);
ex(p->opr.op[2]);
printf("L%03d:\n", lbl2);
} else {
/* if */
printf("\tjz\tL%03d\n", lbl1 = lbl++);
ex(p->opr.op[1]);
printf("L%03d:\n", lbl1);
}
break;
case PRINT:
ex(p->opr.op[0]);
printf("\tprint\n");
break;
case '=':
ex(p->opr.op[1]);
printf("\tpop\t%c\n", p->opr.op[0]->id.i + 'a');
break;
case UMINUS:
ex(p->opr.op[0]);
printf("\tneg\n");
break;
default:
ex(p->opr.op[0]);
ex(p->opr.op[1]);
switch(p->opr.oper) {
case '+': printf("\tadd\n"); break;
case '-': printf("\tsub\n"); break;
case '*': printf("\tmul\n"); break;
case '/': printf("\tdiv\n"); break;
case '<': printf("\tcompLT\n"); break;
case '>': printf("\tcompGT\n"); break;
case GE: printf("\tcompGE\n"); break;
case LE: printf("\tcompLE\n"); break;
case NE: printf("\tcompNE\n"); break;
case EQ: printf("\tcompEQ\n"); break;
}
}
}
return 0;
}AST抽象语法树版本
/* source code courtesy of Frank Thomas Braun */
/* Generation of the graph of the syntax tree */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include "calc3.h"
#include "y.tab.h"
int del = 1; /* distance of graph columns */
int eps = 3; /* distance of graph lines */
/* interface for drawing (can be replaced by "real" graphic using GD or other) */
void graphInit (void);
void graphFinish();
void graphBox (char *s, int *w, int *h);
void graphDrawBox (char *s, int c, int l);
void graphDrawArrow (int c1, int l1, int c2, int l2);
/* recursive drawing of the syntax tree */
void exNode (nodeType *p, int c, int l, int *ce, int *cm);
/*****************************************************************************/
/* main entry point of the manipulation of the syntax tree */
int ex (nodeType *p) {
int rte, rtm;
graphInit ();
exNode (p, 0, 0, &rte, &rtm);
graphFinish();
return 0;
}
/*c----cm---ce----> drawing of leaf-nodes
l leaf-info
*/
/*c---------------cm--------------ce----> drawing of non-leaf-nodes
l node-info
* |
* ------------- ...----
* | | |
* v v v
* child1 child2 ... child-n
* che che che
*cs cs cs cs
*
*/
void exNode
( nodeType *p,
int c, int l, /* start column and line of node */
int *ce, int *cm /* resulting end column and mid of node */
)
{
int w, h; /* node width and height */
char *s; /* node text */
int cbar; /* "real" start column of node (centred above subnodes) */
int k; /* child number */
int che, chm; /* end column and mid of children */
int cs; /* start column of children */
char word[20]; /* extended node text */
if (!p) return;
strcpy (word, "???"); /* should never appear */
s = word;
switch(p->type) {
case typeCon: sprintf (word, "c(%d)", p->con.value); break;
case typeId: sprintf (word, "id(%c)", p->id.i + 'A'); break;
case typeOpr:
switch(p->opr.oper){
case WHILE: s = "while"; break;
case IF: s = "if"; break;
case PRINT: s = "print"; break;
case ';': s = "[;]"; break;
case '=': s = "[=]"; break;
case UMINUS: s = "[_]"; break;
case '+': s = "[+]"; break;
case '-': s = "[-]"; break;
case '*': s = "[*]"; break;
case '/': s = "[/]"; break;
case '<': s = "[<]"; break;
case '>': s = "[>]"; break;
case GE: s = "[>=]"; break;
case LE: s = "[<=]"; break;
case NE: s = "[!=]"; break;
case EQ: s = "[==]"; break;
}
break;
}
/* construct node text box */
graphBox (s, &w, &h);
cbar = c;
*ce = c + w;
*cm = c + w / 2;
/* node is leaf */
if (p->type == typeCon || p->type == typeId || p->opr.nops == 0) {
graphDrawBox (s, cbar, l);
return;
}
/* node has children */
cs = c;
for (k = 0; k < p->opr.nops; k++) {
exNode (p->opr.op[k], cs, l+h+eps, &che, &chm);
cs = che;
}
/* total node width */
if (w < che - c) {
cbar += (che - c - w) / 2;
*ce = che;
*cm = (c + che) / 2;
}
/* draw node */
graphDrawBox (s, cbar, l);
/* draw arrows (not optimal: children are drawn a second time) */
cs = c;
for (k = 0; k < p->opr.nops; k++) {
exNode (p->opr.op[k], cs, l+h+eps, &che, &chm);
graphDrawArrow (*cm, l+h, chm, l+h+eps-1);
cs = che;
}
}
/* interface for drawing */
#define lmax 200
#define cmax 200
char graph[lmax][cmax]; /* array for ASCII-Graphic */
int graphNumber = 0;
void graphTest (int l, int c)
{ int ok;
ok = 1;
if (l < 0) ok = 0;
if (l >= lmax) ok = 0;
if (c < 0) ok = 0;
if (c >= cmax) ok = 0;
if (ok) return;
printf ("\n+++error: l=%d, c=%d not in drawing rectangle 0, 0 ... %d, %d",
l, c, lmax, cmax);
exit(1);
}
void graphInit (void) {
int i, j;
for (i = 0; i < lmax; i++) {
for (j = 0; j < cmax; j++) {
graph[i][j] = ' ';
}
}
}
void graphFinish() {
int i, j;
for (i = 0; i < lmax; i++) {
for (j = cmax-1; j > 0 && graph[i][j] == ' '; j--);
graph[i][cmax-1] = 0;
if (j < cmax-1) graph[i][j+1] = 0;
if (graph[i][j] == ' ') graph[i][j] = 0;
}
for (i = lmax-1; i > 0 && graph[i][0] == 0; i--);
printf ("\n\nGraph %d:\n", graphNumber++);
for (j = 0; j <= i; j++) printf ("\n%s", graph[j]);
printf("\n");
}
void graphBox (char *s, int *w, int *h) {
*w = strlen (s) + del;
*h = 1;
}
void graphDrawBox (char *s, int c, int l) {
int i;
graphTest (l, c+strlen(s)-1+del);
for (i = 0; i < strlen (s); i++) {
graph[l][c+i+del] = s[i];
}
}
void graphDrawArrow (int c1, int l1, int c2, int l2) {
int m;
graphTest (l1, c1);
graphTest (l2, c2);
m = (l1 + l2) / 2;
while (l1 != m) { graph[l1][c1] = '|'; if (l1 < l2) l1++; else l1--; }
while (c1 != c2) { graph[l1][c1] = '-'; if (c1 < c2) c1++; else c1--; }
while (l1 != l2) { graph[l1][c1] = '|'; if (l1 < l2) l1++; else l1--; }
graph[l1][c1] = '|';
}高级yylval: union
YACC的yylval类型是取决于YYSTYPE。如果yylval是个联合体,它即可以处理字符串,也可以是整数,但不是同时处理这两种。我们可以通过定义YYSTYPE为联合体。不过YACC有一个更简单的方法:使用%union语句。
%union {
int number;
char *string;
}
%token <number> STATE
%token <number> NUMBER
%token <string> WORD
定义了我们的联合体,它仅包含数字和字体串,然后使用一个扩展的%token语法,告诉YACC应该取联合体的哪一个部分。
我们不再直接获取yylval的值,而是添加一个后缀指示想取得哪个部分的值。
%{
#include <stdio.h>
#include <string.h>
#include "y.tab.h"
%}
%%
[0−9]+ yylval.number=atoi(yytext); return NUMBER;
[a-z][a−z0−9]+ yylval.string=yytext; return WORD;
%%不过在YACC语法中,我们无须这样做,因为YACC为我们做了神奇的这些, 由于上面的%token定义,YACC自动从联合体中挑选string成员。
heater_select:
TOKHEATER WORD {
printf("Selected heater '%s'\n", $2);
heater = $2;
}
; 需要注意的是,一般来时,yyvsp[0]相当于$1, yyvsp[1]相当于$2,但是,在当yylval为union的时候,$1相当于yysvp[0]的某个类型的值,这个类型是Yacc推断出来的类型。例如,上例中的$2相当于yyvsp[1].string。因此,使用%union的时候的尤其注意这个问题。我们知道,在C语言中,Union在bit级别上是低位对齐(所有成员都从低地址开始存放的)的,因此,有些时候这可能会导致某些错误。
Inter X86 CPU是小端(Little-endian)模式, 例如,0x12345678在内存中的排列情况为:
内存地址 存放内容
0x4000 0x78
0x4001 0x56
0x4002 0x34
0x4003 0x12因此,在使用Yacc时,对于由于类型判断错误而导致的union的值错误的情形要非常谨慎。
有歧义的文法
通常文法是有歧义的,比如:四则运算”34+5“,应该如何分组操作符?这个表达式的意思是(34)+5,还是3*(4+5)?当yacc遇到歧义的文法时,会报错”shift/reduce”冲突或者”reduce/reduce”冲突。
遇到”shift/reduce”冲突是因为yacc在遇到一个词法单元时,不知道应该执行规约动作还是执行词法单元移动。
出现”shift/reduce”冲突时,yacc可以根据规则的优先级和结合性进行处理,具体规则:
- 如果当前的词法单元的优先级高于解析栈中规则,那么执行shift动作。
- 如果当前的词法单元的优先级低于解析栈中规则,那么将栈中的规则进行规约。
- 在当前的词法单元和解析栈中规则的优先级相同的情况下,如果规则是左结合性,那么执行规约动作,否则执行shift。
- 如果没有提供优先级和结合性,那么默认执行shift动作。
StackOverflow上有一个问题是一个很好的处理”shift/reduce conflicts”的例子:Shift/reduce conflicts in bison
“reduce/reduce”冲突就是解析栈中可以应用多个规则进行规约,这种冲突的解决就是选择第一个出现的规则进行规约。一般出现这种冲突主要是因为不同的规则集合可以产生相同的词法单元序列。
通过%nonassoc指定操作符不具备结合性。nonassoc, 意味着没有依赖关系。它经常在连接词中和 %prec一起使用,用于指定一个规则的优先级。
以If-Else的冲突为例,当有两个IF一个ELSE时,该ELSE和哪个IF匹配是一个问题。有两中匹配方法:与第一个匹配和与第二匹配。现代程序语言都让ELSE与最近的IF匹配,这也是yacc的缺省行为。虽然yacc行为正确,但为避免警告,可以给IF-ELSE语句比IF语句更高的优先级:
%nonassoc IFX
%nonassoc ELSE
stmt:
IF expr stmt %prec IFX
| IF expr stmt ELSE stmt一个关于’%prec’的解释:
It declares that that construct has the same precedence as the ‘.’ operator, which will have been specified earlier.
Yacc源程序的风格
- 终端符名全部用大写字母,非终端符全部用小写字母;
- 把语法规则和语义动作放在不同的行;
-
把左部相同的规则写在一起,左部只写一次,而后面所有规则都写在竖线“ ”之后; - 把分号“;”放在规则最后,独占一行;
- 用制表符来对齐规则和动作。
YACC中的递归分为两类:左递归和右递归。大部分时候你应该使用左递归,就像这样:
commands: /*empty*/
|
commands command它的意思是,一个命令集要么是空,要么它包含更多的命令集以及后面跟着一个命令。YACC的工作方式意味着它可以轻松的砍掉单独的命令块(从前面)并逐步归约它们。
一个采用右递归的例子:
commands: /*empty*/
|
command commands但这样代价太高了。如果使用%start规则,需要YACC将所有的命令放在栈上,消耗很多的内存。因此尽可能使用左递归解析长语句,比如解析整个文件。有时则无可避免的使用右递归,如果语句不是太长,不需要想尽一切方法使用左递归。
参考
http://sighingnow.github.io/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86/bnf.html