HBase能提供实时计算服务主要原因是由其架构和底层的数据结构决定的,其采用LSM-Tree(Log-Structured Merge-Tree) + HTable(region分区) + Cache的架构方式保证HBase的查询速度。
一、LSM-tree原理
LSM-tree起源于1996 年的一篇论文《The Log-Structured Merge-Tree (LSM-Tree)》,现在在 NoSQL 系统里非常常见,基本已经成为必选方案了,本文介绍一下 LSM-tree 的主要思想。
LSM-tree 是专门为 key-value 存储系统设计的,key-value 类型的存储系统最主要的就两个个功能,put(k,v):写入一个(k,v),get(k):给定一个 k 查找 v。LSM-tree 最大的特点就是写入速度快,主要利用了磁盘的顺序写,pk掉了需要随机写入的 B-tree。
下图是 LSM-tree 的组成部分,是一个多层结构。首先是内存的 C0 层,保存了所有最近写入的 (k,v),这个内存结构是有序的,并且可以随时原地更新,同时支持随时查询。剩下的 C1 到 Ck 层都在磁盘上,每一层都是一个在 key 上有序的结构。

写入流程:一个 put(k,v) 操作来了,首先追加到写前日志(Write Ahead Log,也就是真正写入之前记录的日志)中,接下来加到 C0 层。当 C0 层的数据达到一定大小,就把 C0 层 和 C1 层合并,类似归并排序,这个过程就是Compaction(合并)。合并出来的新的 new-C1 会顺序写磁盘,替换掉原来的 old-C1。当 C1 层达到一定大小,会继续和下层合并。合并之后所有旧文件都可以删掉,留下新的。
注意数据的写入可能重复,新版本需要覆盖老版本。什么叫新版本,我先写(a=1),再写(a=233),233 就是新版本了。假如 a 老版本已经到 Ck 层了,这时候 C0 层来了个新版本,这个时候不会去管底下的文件有没有老版本,老版本的清理是在合并的时候做的。
写入过程基本只用到了内存结构,Compaction 可以后台异步完成,不阻塞写入。
查询流程:在写入流程中可以看到,最新的数据在 C0 层,最老的数据在 Ck 层,所以查询也是先查 C0 层,如果没有要查的 k,再查 C1,逐层查。
一次查询可能需要多次单点查询,稍微慢一些。所以 LSM-tree 主要针对的场景是写密集、少量查询的场景。
LSM-tree 被用在各种键值数据库中,如 LevelDB,RocksDB,还有分布式行式存储数据库 Cassandra 也用了 LSM-tree 的存储架构。
二、HBase中LSM-Tree的使用
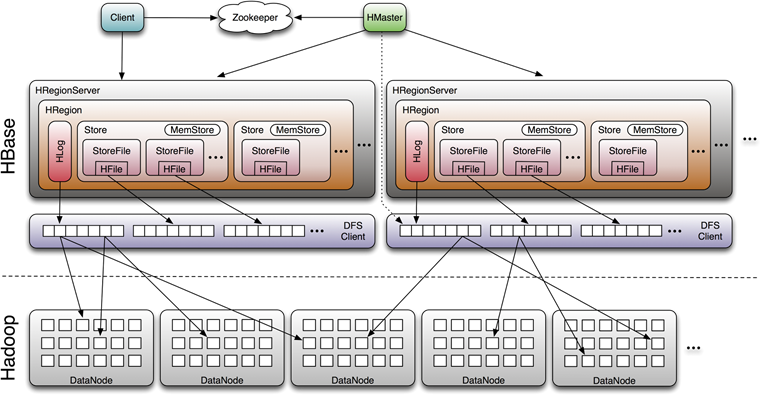
1、HBase写入流程
数据会先写到内存中,为了防止内存数据丢失,写内存的同时需要持久化到磁盘,对应了HBase的MemStore和HLog;
MemStore中的数据达到一定的阈值之后,需要将数据刷写到磁盘,即生成HFile(也是一颗小的B+树)文件;
hbase中的minor(少量HFile小文件合并)major(一个region的所有HFile文件合并)执行compact操作,同时删除无效数据(过期及删除的数据),多棵小树在这个时机合并成大树,来增强读性能。
2、HBase针对LSM-Tree进行的优化
Bloom-filter:就是个带随机概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定数据的。于是就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里啦。效率得到了提升,但付出的是空间代价。
compact:小树合并为大树:因为小树性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了。