记录一些可能会用到但又容易忘记的语法。
一、数据增删改
1、新增
(1)单条数据:INSERT INTO 表名 (列1, 列2, ...) VALUES (值1, 值2, ....);
(2)批量插入:INSERT INTO 表名 (列1, 列2, ...) VALUES (值1, 值2, ....), (值1, 值2, ....), (值1, 值2, ....);
(3)插入子查询:INSERT INTO 表名 (列1, 列2, ...) SELECT 值1, 值2 ... ;
2、修改
(1)单表:UPDATE 表名 SET 列1 = 新值1, 列2 = 新值2, ...... WHERE 筛选条件;
(2)多表级联修改:UPDATE 表1 别名 inner/left/right join 表2 别名 ON 连接条件 SET 列1 = 新值1, 列2 = 新值2...... WHERE 筛选条件;
3、删除
(1)单表:delete from 表名 【where 筛选条件】【limit 条目数】
(2)多表删除:delete 表1别名, 表2别名 from 表1 别名 inner/left/right join 表2 别名 ON 连接条件 WHERE 筛选条件;

4、删除表中全部数据
truncate table 表名;
(1)truncate删完自增长列值从1开始
(2)truncate不能回滚,delete可以回滚
二、SQL执行顺序
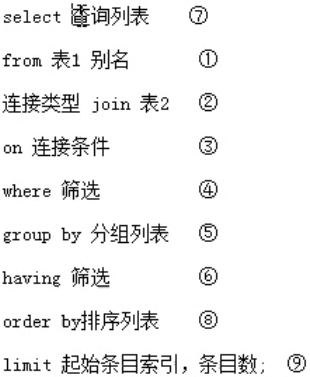
(1)order by,如按多个字段排序,先按第一个字段排序,排序相同的部分,再按第二个字段排序
(2)group by,select后能查询的表字段,必须要出现在group by表达式的后面,按多个字段分组,则多个字段一致的表示一组
(3)having,放group by后,对分组后的查询结果集再筛选一次
(4)limit,放查询语句最后,分页公式:要显示的页数page,每页条目数size
limit (page-1)*size, size
(5)MYISAM存储引擎下,count(*)效率高。INNODB存储引擎下,count(*)和count(1)效率差不多,一般都是用count(*)
三、连接
注意内连接与外连接的区别,内连接是两表的交集部分,外连接是主表全部数据,子表未匹配部分用null。
1、内连接:取两表交集
select * from 表1,表2 where 连接条件
或【inner】join on 连接条件
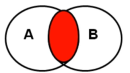
等值连接、非等值连接(筛选条件不是用=,而是用范围)、自连接(如取上级数据)
2、外连接:
(1)左外:left join,左为主表,展示主表所有数据,子表未匹配部分用null
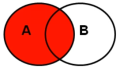
(2)右外:right join,右为主表
(3)全外:outer join
全外连接=内连接结果 + 表1中有但表2没有的 + 表2中有但表1没有的
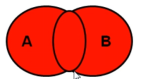
3、交叉连接:cross join,两表进行笛卡尔乘积

4、联合查询
union:查询结果来自多个表,且多个表没有直接的连接关系,但查询的信息一致,将多条查询语句的结果合并成一个结果
语法:
查询语句1 union
查询语句2 union ....
(1)要求多条查询语句的查询列数是一致的,且查询列的类型和顺序一致
(2)union关键字默认去重,union all会包含重复项

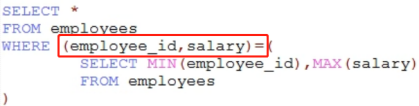
四、子查询
子查询先执行,主查询的条件用到了子查询的结果
1、可搭配分组函数放在select后(仅支持一行一列)

2、可放在from或exists后(多行多列),当虚拟表使用,需要起别名

3、可放where或having后,
一行一列的搭配分组函数 > < >= <= = <>
一列多行的搭配in
一行多列的有局限性,要求各字段使用的比较操作符是一样的,如都是用 = 、>、 <
五、常用函数
1、“+”:不用作字符串拼接,仅用做运算符,其他值+null还是null
2、CONCAT(value1, value2);
3、IFNULL(value, 0);
4、length(str),获取参数字节数,utf8中字母1个字节,汉字3个字节
5、substring(str, index, len) 截取str,从index开始,截取len长度,索引从1开始
6、instr(str, substr),返回子串第一次出现的下标,找不到返回0,索引从1开始
7、replace(str, from_str, to_str),把from_str全替换为to_str
8、replace into具备替换拥有唯一索引或者主键索引重复数据的能力,也就是如果使用replace into插入的数据的唯一索引或者主键索引与之前的数据有重复的情况,将会删除原先的数据,然后再进行添加。
REPLACE INTO users (id,name,age) VALUES(123, ‘chao’, 50);
9、数值型函数
ROUND(1.567),四舍五入
ROUND(1.567,2),保留2位小数
CEIL(X)、FLOOR(X),向上、向下取整
MOD(10,3),取余
RAND(),获取随机数,返回0-1间的小数
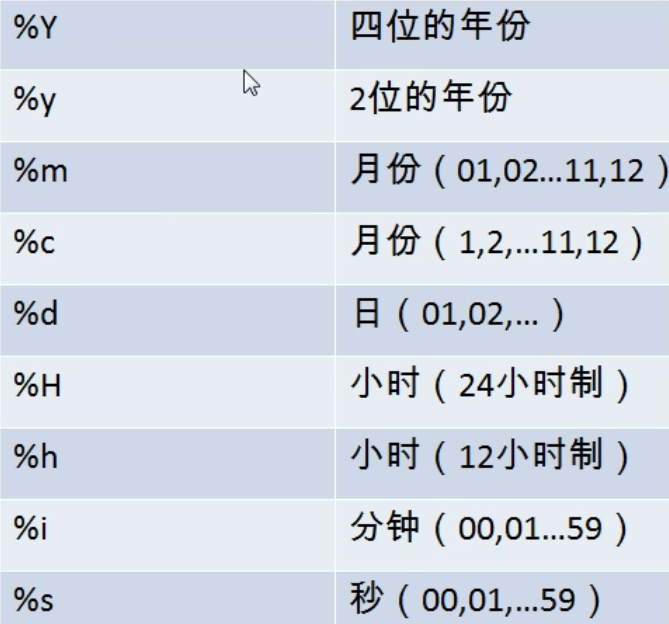
10、日期型转换
STR_TO_DATE(time, '%Y-%m-%d'),字符串转日期
DATE_FORMAT(time, '%Y-%m-%d'),日期转字符串
DATEDIFF(NOW(), '2018-9-1'),两个日期相差天数
11、加密
PASSWORD(str),返回字符的密码形式
MD5(str),返回字符串MD5加密形式
12、运算符:
(1)> < = != <> >= <=
(2)and or not
(3)"like"、"between and"、“in” 、“is null”
like结合通配符,默认不区分大小写;
% 任意多个字符,_ 占单个字符;
\ 转义符,也可以通过escape声明转义字符;
between and会包含零界值;
in不能结合通配符使用,效率和or差不多;
is null仅仅可判断null值,<=>既可判断null又可以判断普通数值;
13、流程控制函数
(1)IF(10<5, '大', ‘小’)
(2)case,两种方式
14、分组函数
sum、avg、max、min、count,这些都会忽略null值,可以和distinct搭配