待到秋来九月八,我花开尽百花杀
rand()和srand()
众所周知,我们在C语言中想要得到一个随机数的时候需要用到srand()和rand()两个函数,而他们分别又是什么呢?
rand()是随机产生一个随机数。如果在后面使用“%”还可以限制随机上限,并且还可以使用数学方法限制区间(例如: rand() % (end - start + 1) + start)。
但是使用rand()产生随机数,就需要设置随机因子,srand()函数就是用来设置随机发生因子的,一般为了我们在使用中每次用rand()产生的随机数保证大概率的不相同性,我们使用time()函数取得计算机当前的时间用来当作因子,这样就能提高rand()函数的随机性了。
rand()取随机数真的随机吗?
严格的来说我们使用计算机产生完全的随机数是很难实现的,计算机是一个严格遵守逻辑的机器,并不能完全像现实生活中抛硬币一样不能精准预知落下的是哪一面。
rand()函数其实使用了一定算法使用设置的随机因子产生随机数。
例如:
使用如下代码设置随机因子不变,为1,运行两次。
#include<stdio.h>
int main()
{
srand(1);
printf("%d\n", rand());
system("pause");
return 0;
}

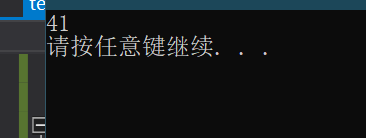
我们可以看到两次运行结果是相同的,这也证实了上述rand()是一个用随机因子通过一系列算法得到的不太随机的“随机数”,这也是为什么我们一般要取用计算机当前时间作为随机因子的原因。
使用时间做随机因子后:
#include<stdio.h>
int main()
{
srand((unsigned int)time(NULL));
printf("%d\n", rand());
system("pause");
return 0;
}
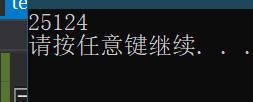
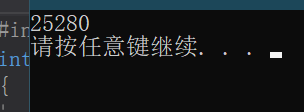
我们可以看到发生了一点变化,由于时间也是1秒1秒的增加,所以变化并不大,也说明了rand()算法对随机因子的两次使用跨度也不大。
rand()函数怎么产生随机数的呢?
作为初学者我们不能准确知道开发者是如何设计的算法,但我们可以知道rand()一定是一个数学算式的实现。
举个例子:
假如我们要取srand(2)作为随机因子,那么
rand(srand)=2+2 * 2 /(2 * 2-1)=3.333333…取后三位小数为第一个随机数
再用333作为下一个随机因子调用
rand(333)=333+333 * 333/(333*333-21)=334.0000189…取后三位小数为第二个随机数再用189作为下一个随机因子调用
…直到取得第n个随机数
当然计算机里不是这么简单就得到随机数的,其函数比上所列的要复杂,但原理是一样的。
Java和C随机数的不同
Java中也有取随机数的方法,通常是
(Math.random() * (end - start + 1) + start)
而从上我们知道C中随机数为:
(rand() % (end - start + 1) + start)
从此我们发现C语言和Java在取随机数上不同的。
C语言取得随机数为整数,因此需要使用%,限制随机数取得的上限。
Java取得随机数为double类型小数,范围在 (0,1]之间,限制随机数的上限只能用 * 。