上一章中,我们学习了前向传播和反向传播,想必大家都学会了,这一章我们学习多个样本的梯度下降。
如果没有看上一章,可以去看一下,传送门:一文掌握深度学习(六)——彻底搞懂前向/反向传播
在之前的章节中,我们都是基于单个样本来学习的,但是实际工作中,我们会处理十万或者百万个样本,这个时候我们需要怎么做呢?
在回答这个问题之前,我们先回顾下我们之前学习的知识:
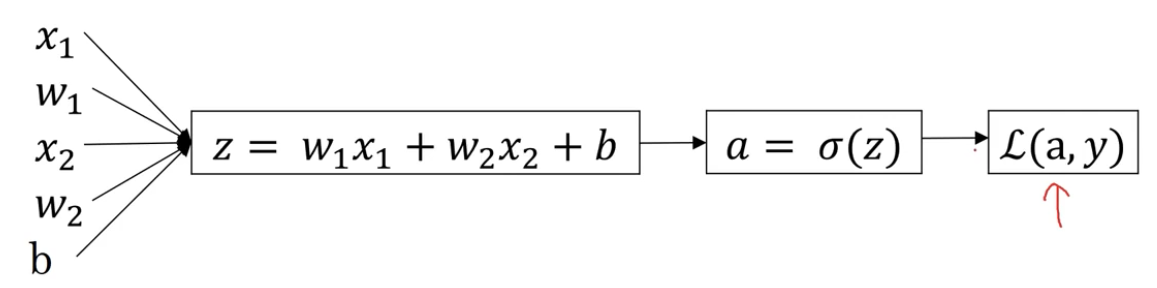
我们假设每个样本为,而且样本有两个特征值,分别为
和
,那么对于单个样本来说就有:
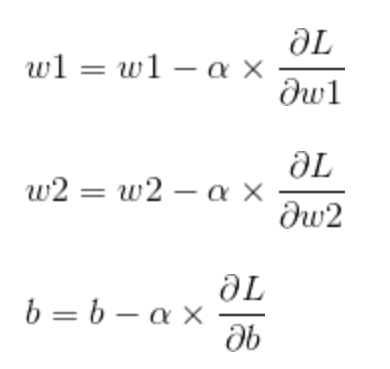
变量说明:代表第
个样本,
和
代表第
个样本有两个特征值,
代表权重,
代表偏置。
以上就是单个样本的公式,多个样本梯度下降说白了就是把每一个样本的梯度加起来,求平均值然后进行更新,我们只需要用循环就可以轻松的解决问题:

通过上图可以看出,我们只需一个for循环就可以完成多个样本的的梯度下降,但是在实际操作中,我们还是尽可能的避免使用循环,下一章我们讲解可以去掉循环的方法:向量。
以上就是本文的全部内容,获取深度学习资料以及课程,扫描下方公众号,回复“资料”两字即可获取,祝您学习愉快。
