1.数据集的准备
在用paddleocr训练自定义的数据集时,我们需要使用自己标注的数据,paddle提供的标注文件格式为:

其中json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 points 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 transcription 表示当前文本框的文字。
所以楼主采用了labelme标注软件来进行标注。
标注的结果如下:
{
"version": "4.5.6",
"flags": {
},
"shapes": [
{
"label": "200MM",
"points": [
[
332.1428571428571,
402.33516483516485
],
[
347.3901098901099,
428.7087912087912
],
[
428.15934065934067,
370.3296703296703
],
[
412.08791208791206,
348.489010989011
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {
}
},
{
"label": "CHROME",
"points": [
[
606.6852367688023,
190.80779944289694
],
[
618.6629526462395,
209.4707520891365
],
[
694.1888619854722,
154.23728813559322
],
[
681.5980629539952,
138.25665859564165
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {
}
},
{
"label": "VANADIUM",
"points": [
[
613.3600194244167,
213.90430776909224
],
[
625.0569476082005,
230.5239179954442
],
[
716.0234576810753,
162.81471939136827
],
[
704.8854431532303,
146.34982835020605
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {
}
}
],
"imagePath": "..\\images\\new_pic_0.png",
"imageData": "图片的数据太大,这里就删除了"
"imageHeight": 718,
"imageWidth": 860
}
2.将json文件转为txt文件
import json
import os
def transfrom_dict_to_str(target_dict):
# 根据字典重新组织数据
list_target = []
list_data = target_dict['shapes']
for item in list_data:
dict02 = {
}
# 把label 转化为transcription
dict02['transcription'] = item['label']
list03 = item['points']
list04 = []
for j in list03:
list04.append([int(j[0]), int(j[1])])
dict02['points'] = list04
list_target.append(dict02)
target_str = str(list_target)
# 将字符中的"符号提前进行转义
# target_str = target_str.replace("\"", "\\"")
# 将字符中的'符号转为"
target_str = target_str.replace("'", "\"")
# print(target_str)
return target_str
if __name__ == "__main__":
# json文件的文件夹
src = r"D:\chrome_download\pic\label"
f = open('demo.txt', 'a', encoding='utf-8')
for dirpath, dirnames, filenames in os.walk(src):
for filename in filenames:
fd = open(os.path.join(src, filename))
data = fd.read()
dict01 = json.loads(data)
target_str = transfrom_dict_to_str(dict01)
image_path = dict01['imagePath']
f.write('icdar_c4_train_imgs/'+image_path.split('\\')[-1]+'\t')
f.write(target_str+'\n')
f.close()
转换后的结果:

转换成功,大功告成,然后我们就可以用我们的标注格式文件进行相应的ocr训练了
后记:如果标记的字符中本来就有"这个字符,这里我们需要自己手动转义一下
例如: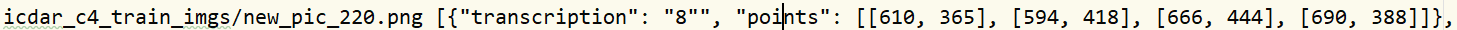
这里的8"需要我们手动添加为8\",否则paddle会分辨不出两个"到底是什么意思。
因为楼主标记的图片中只有一处需要修改,因此,就没有更改原来的脚本。当然如果你遇到大量修改的地方,可以在将字符中的’符号转为"的位置提前把"进行转义。