Python:多指标权重确定方法—熵值法
一、需准备的资料
1.一份excel的数据表格,列为指标(评价指标),行为城市(研究对象,也可以是年份,)
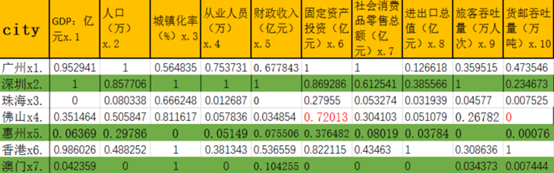
city GDP:亿元x.1 人口(万)x.2 城镇化率(%)x.3 从业人员(万)x.4 财政收入(亿元)x.5 固定资产投资(亿元)x.6 社会消费品零售总额(亿元)x.7 进出口总值(亿元)x.8 旅客吞吐量(万人次)x.9 货邮吞吐量(万吨)x.10
广州x1. 21503 1449 86 20 5947 5919 9402 9714 6583 233
深圳x2. 22438 1252 100 27 8624 5147 6016 28075 18142 115
珠海x3. 2564 176 89 1 314 1662 1128 3001 921 3
佛山x4. 9549 765 94 2 604 4265 3320 4358 4929 0.02
惠州x5. 3830 477 68 2 941 2234 1363 3419 959 0.4
香港x6. 22160 741 100 10 4772 4868 4461 71642 5665 493
澳门x7. 3406 65 100 0.76 1180 9 66256 736 716 3
2.数据表格保存在D:\5.python data的路径下,命名为szfqz.xls
二、最终获得的资料
1. 10个指标的权重
city GDP:亿元x.1 人口(万)x.2 城镇化率(%)x.3 从业人员(万)x.4 财政收入(亿元)x.5 固定资产投资(亿元)x.6 社会消费品零售总额(亿元)x.7 进出口总值(亿元)x.8 旅客吞吐量(万人次)x.9 货邮吞吐量(万吨)x.10
权重
2. 7个城市航空竞争力的排名
city 竞争力综合得分 排名
广州x1.
深圳x2.
珠海x3.
佛山x4.
惠州x5.
香港x6.
澳门x7.
三、计算步骤
1.数据标准化处理(归一化)

# 1、数据的归一化(可以最大最小归一,也可以标准化归一)
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from xlwt import *
from docx import Document
from docx.shared import Inches
plt.rcParams['font.sans-serif'] = ['microsoft YaHei'] # 显示中文微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False # 避免负号显示为方块
data = pd.read_excel('D:\\5.python data\\szfqz.xls') # 把指定位置的excel表格数据导入python形成一个dataframe表格数据
print(data) # 观察导入的数据表格,如这种类型格式的数据才能导入计算
del data[list(data)[0]] # 第一列是城市,不参加求均值、标准差、变异系数的过程,所以先删掉
print(data)
GYH = (data-data.min())/(data.max()-data.min()) # 即实现简单标准化归一
pd.set_option('display.max_columns', None) # display.max_columns代表所有列,None代表所有行
print(GYH) # 归一之后的表格
归一化后的表格
例如: 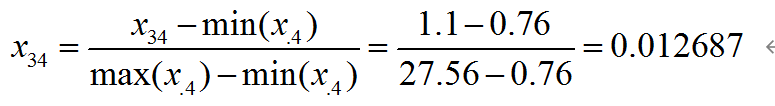
2.计算第i个城市第j项指标的比重:
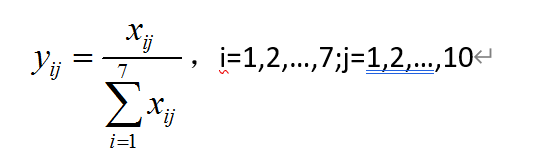
# 2.计算第i个城市第j项指标的比重
BZ = GYH/GYH.sum() # 归一化之后表格中的值除以这一列的和得到新的比重表格
SM2 = '下面是比重表格' # 写入excel中的字符串,根据需要来进行修改
excel = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n' + SM2 + '\n') # “a”代表追加写入模式,encoding...代表写入的时候正确显示中文,\n代表换行
BZ.to_csv("D:\\5.python data\\szfqz.csv", index=False, mode='a', encoding="utf_8_sig")
运算结果:
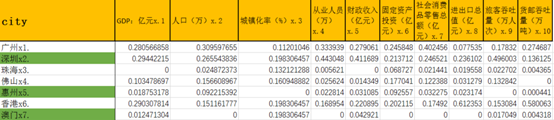
例如: 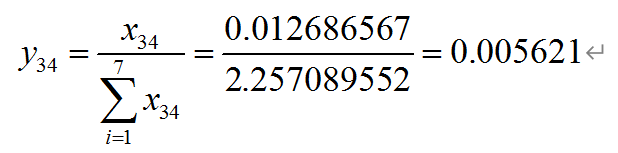
3.计算指标信息熵:
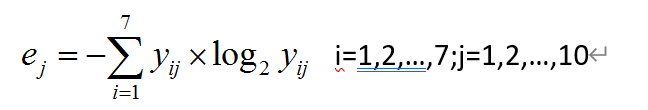
# 3. 计算指标信息熵
df3 = -BZ*BZ.apply(np.log2)
df3 = df3.sum()
print(df3)
结果:
GDP:亿元x.1 2.076935
人口(万)x.2 2.312275
城镇化率(%)x.3 2.552376
从业人员(万)x.4 1.784065
财政收入(亿元)x.5 1.960672
固定资产投资(亿元)x.6 2.465151
社会消费品零售总额(亿元)x.7 2.116074
进出口总值(亿元)x.8 1.604223
旅客吞吐量(万人次)x.9 1.970791
货邮吞吐量(万吨)x.10 1.432515
4.计算信息熵冗余度
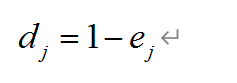
df4= 1-df3
print(df4)
结果:
GDP:亿元x.1 -1.076935
人口(万)x.2 -1.312275
城镇化率(%)x.3 -1.552376
从业人员(万)x.4 -0.784065
财政收入(亿元)x.5 -0.960672
固定资产投资(亿元)x.6 -1.465151
社会消费品零售总额(亿元)x.7 -1.116074
进出口总值(亿元)x.8 -0.604223
旅客吞吐量(万人次)x.9 -0.970791
货邮吞吐量(万吨)x.10 -0.432515
5.计算指标权重
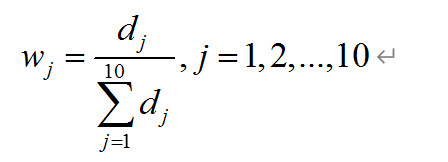
wj = df4/df4.sum()
print('\n 指标权重表格 \n', wj)
plt.bar(wj, color='G')
# dataframe排序:根据某一列的值,对权重数据画条形图
wj1 = wj.sort_values() # 根据值的大小进行排序
# df.sort_index(inplace=True) # 根据索引值排序,inplace如果手动设定为 True,那么原数组就可以被替换。
wj1.plot.barh()
plot.show()
# 把指标权重表格导入到CSV中
SM3 = '下面是指标的权重表格' # 写入CSV中的字符串,根据需要来进行修改
CSV3 = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n\n' + SM3 + '\n') # “a”代表追加写入模式,encoding...代表写入的时候正确显示中文,\n代表换行
BZ.to_csv("D:\\5.python data\\szfqz.csv", index=False, mode='a', encoding="utf_8_sig")
SM4 = '根据熵值法计算的权重数据,城市航空竞争力影响各因素中权重分别为XX指标占XX%,XX指标占X%,XX指标占X%,XX指标占X%,XX指标占X%。故我们在进行提升城市航空竞争力决策时,更多是考虑XX指标、XX指标等重要因素。这是从权重角度考虑的' # 写入CSV中的字符串,根据需要来进行修改
CSV4 = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n\n' + SM4 + '\n')
权重表格:
GDP:亿元x.1 0.104810
人口(万)x.2 0.127714
城镇化率(%)x.3 0.151082
从业人员(万)x.4 0.076307
财政收入(亿元)x.5 0.093495
固定资产投资(亿元)x.6 0.142593
社会消费品零售总额(亿元)x.7 0.108620
进出口总值(亿元)x.8 0.058805
旅客吞吐量(万人次)x.9 0.094480
货邮吞吐量(万吨)x.10 0.042094

6.计算指标评价得分:
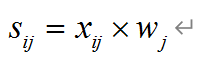
BZ_mat = np.mat(BZ) # 因为涉及到两个dataframe的值相乘,需要先转化为矩阵,首先把权重转化为矩阵
wj_mat = np.mat(wj) # 把指标权重化为矩阵形式
sij = BZ_mat*wj_mat.T # BZ_mat是一个7X10的矩阵,wj_mat是一个1X10的矩阵,所以要转置
sij = pd.DataFrame(sij) # 把相乘后的矩阵结果转化为dataframe
print('\n 各个城市的综合评分 \n', sij)
# 把综合评分数据导入CSV中
SM5 = '下面是城市的综合评分' # 写入CSV中的字符串,根据需要来进行修改
CSV5 = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n\n' + SM5 + '\n') # “a”代表追加写入模式,encoding...代表写入的时候正确显示中文,\n代表换行
sij.to_csv("D:\\5.python data\\szfqz.csv", index=False, mode='a', encoding="utf_8_sig")
[[0.24918247]
[0.29075881]
[0.03917411]
[0.11138891]
[0.03647488]
[0.23594778]
[0.03707304]]
最后附上所有代码
# -*- encoding=utf-8 -*-
# ==================================
# 参考下面四篇文章
# https://www.jianshu.com/p/468e2af86d59
# https://www.jb51.net/article/188971.htm
# https://blog.csdn.net/u013617144/article/details/79533868
# https://www.jianshu.com/p/3e08e6f6e244
# =====================================================
# 1、数据的归一化(可以最大最小归一,也可以标准化归一)
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = ['microsoft YaHei'] # 显示中文微软雅黑字体
plt.rcParams['axes.unicode_minus'] = False # 避免负号显示为方块
data = pd.read_excel('D:\\5.python data\\szfqz.xls') # 把指定位置的excel表格数据导入python形成一个dataframe表格数据
print('\n 原始数据 \n', data) # 观察导入的数据表格,如这种类型格式的数据才能导入计算
# 原始数据导入CSV中
SM0 = '原始数据表格:' # 把原始数据data显示在结果CSV中
CSV0 = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n\n' + SM0 + '\n')
data.to_csv("D:\\5.python data\\szfqz.csv", index=False, mode='a', encoding="utf_8_sig")
# 原始数据的预处理
del data[list(data)[0]] # 第一列是城市,不参加求均值、标准差、变异系数的过程,所以先删掉
print('\n 原始数据去掉第一列城市后的数据 \n', data)
GYH = (data-data.min())/(data.max()-data.min()) # 即实现简单标准化归一
pd.set_option('display.max_columns', None) # display.max_columns代表显示所有列,None代表显示所有行
print('\n 简单归一化形成的dataframe \n', GYH) # 归一之后的表格
# 把归一化之后的数据导入到CSV表格中
SM1 = '下面是简单归一化之后的表格:' # 在CSV中对归一化后数据的简单说明
CSV1 = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n\n' + SM1+'\n')
GYH.to_csv("D:\\5.python data\\szfqz.csv", index=False, mode='a', encoding="utf_8_sig")
# BZGYH = (data-data.mean())/(data.std()) # data.mean()是平均值、data.std()是标准差
# 2.计算第i个城市第j项指标的比重
BZ = GYH/GYH.sum() # 归一化之后表格中的值除以这一列的和得到新的比重表格
# 把比重表格导入到CSV中
# SM2 = '下面是比重表格' # 写入CSV中的字符串,根据需要来进行修改
# CSV2 = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n\n' + SM2 + '\n') # “a”代表追加写入模式,encoding...代表写入的时候正确显示中文,\n代表换行
# BZ.to_csv("D:\\5.python data\\szfqz.csv", index=False, mode='a', encoding="utf_8_sig")
# 3. 计算指标信息熵
df3 = -BZ*BZ.apply(np.log2) #比重表格中的每个值乘以它以2为底的对数,并取负值,形成一个新的dataframe表格
df3 = df3.sum() # 每个指标代表的列求和
# print('这是每个指标的信息熵+\n', df3)
# 4.计算信息熵冗余度
df4= 1-df3
# print(df4)
# 5.计算指标权重
wj = df4/df4.sum()
print('\n 指标权重表格 \n', wj)
plt.bar(wj, color='G')
# dataframe排序:根据某一列的值
wj1 = wj.sort_values() # 根据值的大小进行排序
# df.sort_index(inplace=True) # 根据索引值排序,inplace如果手动设定为 True,那么原数组就可以被替换。
wj1.plot.barh()
plt.show()
# 把指标权重表格导入到CSV中
SM3 = '下面是指标的权重表格' # 写入CSV中的字符串,根据需要来进行修改
CSV3 = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n\n' + SM3 + '\n') # “a”代表追加写入模式,encoding...代表写入的时候正确显示中文,\n代表换行
BZ.to_csv("D:\\5.python data\\szfqz.csv", index=False, mode='a', encoding="utf_8_sig")
SM4 = '根据熵值法计算的权重数据,城市航空竞争力影响各因素中权重分别为XX指标占XX%,XX指标占X%,XX指标占X%,XX指标占X%,XX指标占X%。故我们在进行提升城市航空竞争力决策时,更多是考虑XX指标、XX指标等重要因素。这是从权重角度考虑的' # 写入CSV中的字符串,根据需要来进行修改
CSV4 = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n\n' + SM4 + '\n')
# 6.计算城市评价得分
BZ_mat = np.mat(BZ) # 因为涉及到两个dataframe的值相乘,需要先转化为矩阵,首先把权重转化为矩阵
wj_mat = np.mat(wj) # 把指标权重化为矩阵形式
sij = BZ_mat*wj_mat.T # BZ_mat是一个7X10的矩阵,wj_mat是一个1X10的矩阵,所以要转置
sij = pd.DataFrame(sij) # 把相乘后的矩阵结果转化为dataframe
print('\n 各个城市的综合评分 \n', sij)
# 把综合评分数据导入CSV中
SM5 = '下面是城市的综合评分' # 写入CSV中的字符串,根据需要来进行修改
CSV5 = open("D:\\5.python data\\szfqz.csv", "a", encoding="utf_8_sig").write('\n\n' + SM5 + '\n') # “a”代表追加写入模式,encoding...代表写入的时候正确显示中文,\n代表换行
sij.to_csv("D:\\5.python data\\szfqz.csv", index=False, mode='a', encoding="utf_8_sig")