特意写一章关于IO流的知识,不为别的,是因为IO流实在太重要了
文件
文件对象
File 就是文件对象,我们电脑上的文件和文件夹都可以用这个File实例化
public class Test{
public static void main(String[] args){
// 获取绝对路径D盘的hello文件夹
File f1 = new File("D:/hello");
// 获取相对路径的hello.txt文件
File f2 = new File("hello.txt");
// 获取D盘的hello文件夹下hello.txt文件的实例
File f3 = new File(f1,"hello.txt");
// 输出三个文件或者文件夹的绝对路径
System.out.println(f1.getAbsolutePath());
System.out.println(f2.getAbsolutePath());
System.out.println(f3.getAbsolutePath());
}
}
上面代码注释讲的已经非常的详细了,用三种方式创建一个文件对象,怎么获取文件的绝对路径
文件常用方法
假设我们已经实例化了一个File对象f
- 判断是否存在 f.exists()
- 判断是否是文件夹 f.isDirectory()
- 判断是否是文件 f.isFile()
- 获取文件的长度 f.length()
- 文件最后修改的时间 f.lastModified()
- 设置文件最后修改时间 f.setLastModified(0) 这里的0代表的是时间戳 也就是1970.1.1 08:00:00
- 文件重命名 f.renameTo(“newName”)
- 以字符串数组的形式,返回当前文件夹下面的所有文件 f.list()
- 以文件数组的形式,返回当前文件夹下面的所有文件 f.listFiles()
- 以字符串形式返回所在文件夹 f.getParent()
- 以字符串形式返回获取所在文件夹 f.getParentFile()
- 创建一个文件夹 f.mkdir() 如果说f所在的父文件夹不存在就会抛出异常
- 创建一个文件夹 f.mkdirs() 如果说f所在的父文件夹不存在就会自动给你创建一个父文件夹
- 删除文件 f.delete()
- JVM结束的时候删除文件 f.deleteOnExit()
遍历C:\WINDOWS下面所有文件
public class Test{
public static void main(StringP[] args){
File f = new File("C:/WINDOWS");
File[] files;
int k=0;
long max = 0;
if(f.exists){
// 把文件夹下面的所有文件都取出来
files = f.listFiles();
// 遍历所有的文件取出体积最大的文件
for(int i=0;i<files.length();i++){
if(files[i].length()>max){
//如果比最大的文件还大就把他的下标记下来
k = i;
max = files[i].length();
}
}
}else{
System.out.println("文件夹不存在");
}
// 输出找到的最大的文件路径和它体积
System.out.println("最大文件路径: "+files[k]);
System.out.println("最大文件体积: "+files[k].length()+" 字节");
}
}
编码
编码是信息从一种形式或格式转换为另一种形式的过程
常见的编码
常见的编码方式有如下几种:
- ISO-8859-1 ASCII 数字和西欧字母
- GBK GB2312 BIG5 中文
- UNICODE (统一码,万国码)
看样子,我们的中文就是属于这个GBK这种编码了,也就是说中文只能用GBK编码来存储嘛?
这个肯定是错的,UNICODE称为万国码,也就是全世界任何国家的字符都是可以储存的,只不过,他占用的空间是最大的,比入英文字母只需要1字节的空间,汉字需要3字节的空间,但是Unicode它不管你是英文字母还是汉字,都统一给你4个字节,这样的话是比较浪费空间的,所以就诞生了UTF-8这种基于Unicode减肥版本的编码方式。
UTF-8它可以对英文或者数字使用一个字节,对汉字使用三个字节,这样的话就避免了空间的浪费。
Java源代码中的汉字在执行之后,都会变成JVM中的字符,而这些中文字符采用的编码方式,都是Unicode
流
什么流?流就是一系列的数据。
当不同的介质之间有数据交互的时候,Java就是使用流来实现
比如读取文件的数据到程序中,站在程序的角度来看,就叫做输入流。
文件输入流
如何创建文件输入流,看以下代码:
public class Test{
public static void main(String[] args){
try{
File f = new File("D:/hello.txt");
// 通过这个文件输入流可以将硬盘上文件中的数据读取到java程序内存中来
FileInputStream fis = new FileInputStream(f);
}catch(IOException e){
e.printStackTrace();
}
}
}
字节流
字节输入流
InputStream是字节输入流,同时也是抽象类,只提供方法声明,不提供方法的具体实现。
FileInputStream是InputStream的子类,我们下面就用FileInputStream来实现读取文件的内容
public class Test{
public static void main(String[] args){
try{
// 准备一个文本文件,里面内容是AB
File f = new File("D:/test.txt");
// 创建文件输入流
FileInputStream fis = new FileInputStream(f);
// 创建一个字节数组,它的长度就是文件的长度
byte[] all = new byte[(int)f.length()];
// 以字节流的形式读取文件中的所有内容到字节数组
fis.read(all);
for(byte b : all){
System.out.println(b);
}
fis.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
结果是65和66 也就是A和B对应的ASCII码
字节输出流
OutputStream 是字节输出流,更InputStream也是一样的,抽象类。
所以我们用FileOutputStream为例往文件中写入数据
public class Test{
public static void main(String[] args){
try{
// 准备一个文本文件,里面内容是空的
File f = new File("D:/test.txt");
// 创建文件输出流
FileOutputStream fis = new FileOutputStream(f);
// 创建一个字节数组,里面写上A和B的ASCII码
byte[] data = {65,66};
// 以字节流的形式将data里的数据写入到输出流
fis.write(all);
fis.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
我们打开对应的文件,发现数据就已经写在里面了,但是输出流跟输入流有一个区别,就是输出流的时候不一定要求文件存在,当文件不存在的时候,会自动给我们创建一个新的文件,而输入流则会抛出异常
字符流
字符流:就是在字节流的基础上,加上编码,形成的数据流
字符流分为字符输入流Reader 和 字符输出流 Writer
他们常用的子类就是FileReader 和 FileWriter
字符输入流
在之前我们使用了字节输入流读取文件中的内容,读取的AB打印出来是65和66
现在我们来看一下使用字符输入流读取文件是什么样的结果
public class Test {
public static void main(String[] args) {
// 准备文件hello.txt其中的内容是AB
File f = new File("d:/hello.txt");
// 创建基于文件的Reader
try (FileReader fr = new FileReader(f)) {
// 创建字符数组,其长度就是文件的长度
char[] all = new char[(int) f.length()];
// 以字符流的形式读取文件所有内容
fr.read(all);
for (char b : all) {
// 打印出来是A B
System.out.println(b);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
字符输入流可以直接读取文件中的字符
字符输出流
我们可以直接将一串字符存储到文件中,代码如下:
public class Test{
public static void main(String[] args){
// 创建文件对象,文件内容是空的
File f = new File("D:/hello.txt");
// 要写入的字符串
String str = "hello";
char[] cs = str.toCharArray();
try(FileWrter fw = new FileWriter(f)){
fw.write(cs)
}catch(IOException e){
e.printStackTrace();
}
}
}
文件中的内容就会变称hello
中文读取
上面我们学习了字节流和字符流,那么我们分别用两种流来从文件中读取汉字内容。
用字节流读取中文内容
首先你得了解文本是以哪种编码方式进行保存的
使用字节流读取文本后,再使用对应的编码方式去识别这些文字
public class Test{
File f = new File("D:/hello.txt");
try(FileInputStream fis = new FileInputStream(f)){
byte[] all = new byte[(int) f.length()];
fis.read(all);
//将读到的字节进行编码输出
String str = new String(all,"GBK");
System.out.println(str);
}catch(IOException e){
e.printStackTrace();
}
}
用字符流读取中文内容
FileReader得到的字符,肯定是已经把字节根据某种编码方式识别成的字符。
FIleReader的编码方式可以用Charset.defaultCharset()获取,如果是中文的操作系统那么就是GBK
假设现在我们的文件是用UTF-8编码方式保存的,那么我们该如何使用字符流读取文字呢?
答案就是使用InputStreamReader,这个是字节流到字符流的桥接器,它可以按照指定的字符集读取字节并将它们转换为字符。
public class TestStream {
public static void main(String[] args) throws UnsupportedEncodingException, FileNotFoundException {
File f = new File("D:/hello.txt");
System.out.println("默认编码方式:"+Charset.defaultCharset());
//FileReader得到的是字符,所以一定是已经把字节根据某种编码识别成了字符了
//而FileReader使用的编码方式是Charset.defaultCharset()的返回值,如果是中文的操作系统,就是GBK
try (FileReader fr = new FileReader(f)) {
char[] cs = new char[(int) f.length()];
fr.read(cs);
System.out.printf("FileReader会使用默认的编码方式%s,识别出来的字符是:%n",Charset.defaultCharset());
System.out.println(new String(cs));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//FileReader是不能手动设置编码方式的,为了使用其他的编码方式,只能使用InputStreamReader来代替
//并且使用new InputStreamReader(new FileInputStream(f),Charset.forName("UTF-8")); 这样的形式
try (InputStreamReader isr = new InputStreamReader(new FileInputStream(f),Charset.forName("UTF-8"))) {
char[] cs = new char[(int) f.length()];
isr.read(cs);
System.out.printf("InputStreamReader 指定编码方式UTF-8,识别出来的字符是:%n");
System.out.println(new String(cs));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
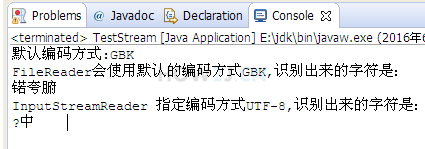
为什么中字的前面有一个?,如果你是用记事本另存为UTF-8的字符集编码的话,那么在第一个字节有一个标识,叫做BOM,用来标识这个文件是使用UTF-8编码的
缓存流
以介质是硬盘为例,字节流和字符流的弊端:
在每一次读写的时候,都会访问硬盘。 如果读写的频率比较高的时候,其性能表现不佳。
为了解决以上弊端,采用缓存流。
缓存流在读取的时候,会一次性读较多的数据到缓存中,以后每一次的读取,都是在缓存中访问,直到缓存中的数据读取完毕,再到硬盘中读取。
就好比吃饭,不用缓存就是每吃一口都到锅里去铲。用缓存就是先把饭盛到碗里,碗里的吃完了,再到锅里去铲
缓存流在写入数据的时候,会先把数据写入到缓存区,直到缓存区达到一定的量,才把这些数据,一起写入到硬盘中去。按照这种操作模式,就不会像字节流,字符流那样每写一个字节都访问硬盘,从而减少了IO操作
缓存字符输入流
BufferedReader可以一次性读取一行数据
public class Test{
public static void main(String[] args){
/**
准备一个文件,里面的内容是
hello
world
你好
*/
File f = new File("d:/hello.txt");
// 缓存字符输入流必须在一个存在的流的基础上创建
try(
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);
){
while(true){
// 一次读取一行
String line = br.readLine();
if(line == null){
break;
}
System.out.println(line);
}catch(IOException e){
e.printStackTrace();
}
}
}
}
缓存字符输出流
PrintWrite,可以一次写出一行数据
public class TestStream {
public static void main(String[] args) {
// 向文件lol2.txt中写入三行语句
File f = new File("d:/hello.txt");
try (
PrintWriter pw = new PrintWriter(f);
) {
pw.println("hello");
pw.println("world");
pw.println("你好");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
这里需要注意的是,缓存字符输入流的构造方法的参数是一个Reader,也就是一个字符流,而PrintWriter的构造参数可以是文件对象也可以是字节流或者字符流对象!
缓存字节输入流和输出流
分别是BufferedInputStream 和 BufferedOutputStream
下面代码演示的是通过缓存字节输入流和输出流实现文件的复制
public class Test{
public static void main(String[] args){
File file = new File("E:/我的文档/临时文件/视屏文件.ts");
File file1 = new File("E:/我的文档/临时文件/视屏文件(副本).ts");
try (
FileInputStream fis = new FileInputStream(f);
FileOutputStream fos = new FileOutputStream(f1);
BufferedInputStream bis = new BufferedInputStream(fis);
BufferedOutputStream bos = new BufferedOutputStream(fos);
){
byte[] bytes = new byte[1024];
int len;
while(true){
len = bis.read(bytes);
if(len == -1){
break;
}
bos.write(bytes,0,len);
}
}catch (IOException e){
e.printStackTrace();
}
}
}
}