1、易并行聚合算法
有些聚合分析的算法,是很容易就可以并行的,比如说max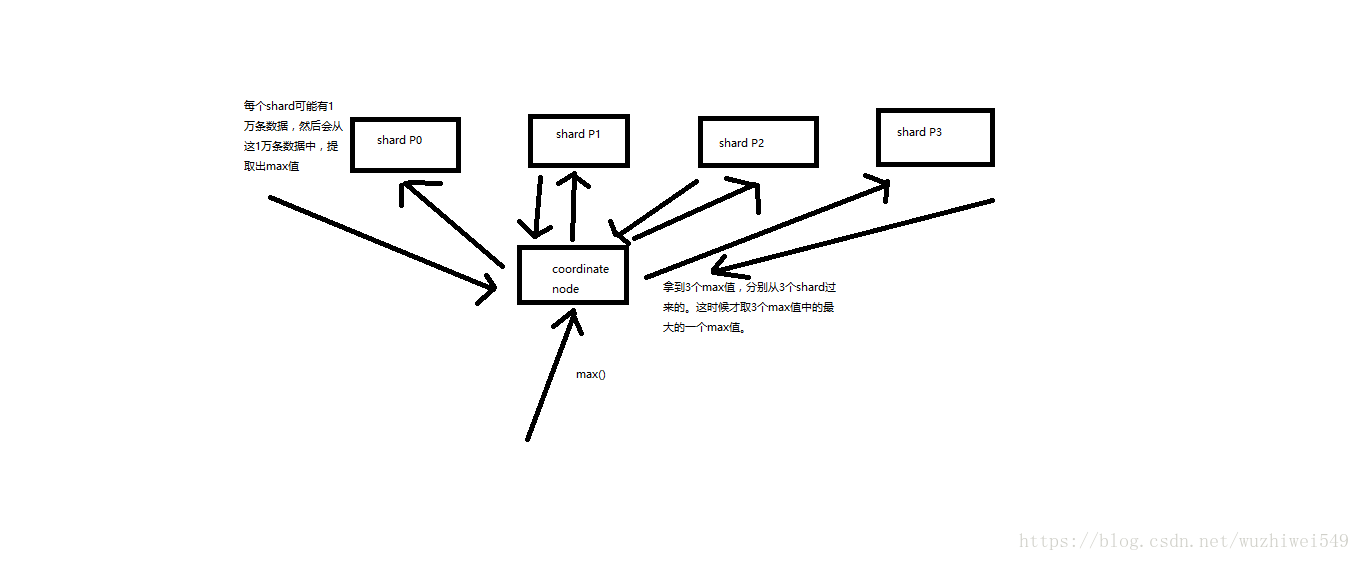
有些聚合分析的算法,是 不好并行的,比如说,count(distinct),并不是说,在每个node上,直接就出一些distinct value,就可以的,因为数据可能会很多
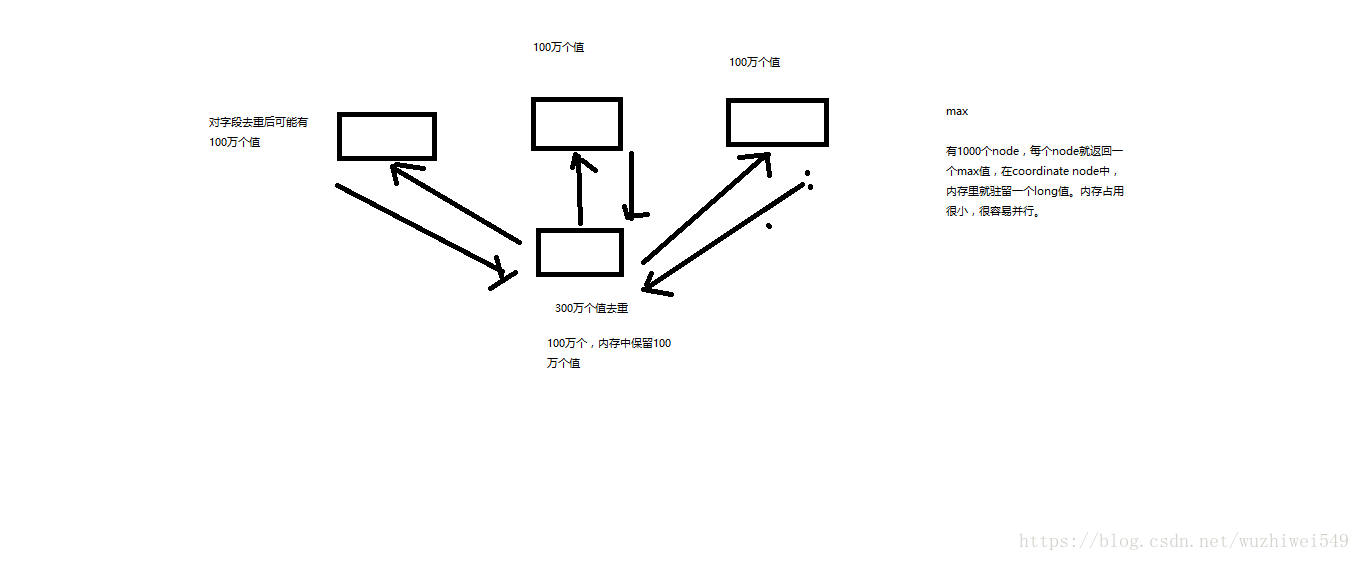
es会采取近似聚合的方式,就是采用在每个node上进行近估计的方式,得到最终的结论,cuont(distcint),100万,1050万/95万 --> 5%左右的错误率
近似估计后的结果,不完全准确,但是速度会很快,一般会达到完全精准的算法的性能的数十倍
聚合相关操作请参考《 Elasticsearch 之(6)kibana嵌套聚合,下钻分析,聚合分析》
2、三角选择原则
精准+实时+大数据 --> 选择2个(1)精准+实时: 没有大数据,数据量很小,那么一般就是单击跑,随便你则么玩儿就可以
(2)精准+大数据:hadoop,批处理,非实时,可以处理海量数据,保证精准,可能会跑几个小时
(3)大数据+实时:es,不精准,近似估计,可能会有百分之几的错误率
3、近似聚合算法
如果采取近似估计的算法:延时在100ms左右,0.5%错误如果采取100%精准的算法:延时一般在5s~几十s,甚至几十分钟,几小时, 0%错误