String转换为char数组
String psw
char[] pswCharArrays = psw.toCharArray();
char数组转换为字符串
new String(pswCharArrays)
三元运算符
String result = (i % 2 == 0)? i+"是偶数": i+"是奇数";
左移算法实现num*2的n次方计算
num << n
异或算法实现两个整型变量的互换,且不借助第三变量
a = a ^ b;
b = b ^ a;
a = a ^ b;
判断是否闰年
(year % 4 == 0) && (year % 100 != 0) || (year % 400 ==0)
switch case break default用法
二维数组嵌套,99乘法表
for (int i1 = 1; i1 <= 9; i1++) {
for (int j = 1; j <= i1; j++) {
System.out.print(i1+"*"+j + "="+ i1*j + "\t");
}
System.out.println();
}
过滤String左右两边的空格
ss.trim();
将字符串转为字符数组,并判断字符char是否为数字
for (int i1 = 0; i1 < ss.length(); i1++) {
char charss = ss.charAt(i1);
if (!Character.isDigit(charss)&&charss != ' '){
System.out.println("输入包含非数字内容");
}
}
将字符串切片为字符串数组,字符串数组转化为int数组

String[] numss = ss.split(" {1,}"); //split("正则表达式")
int[] numArray = new int[]{numss.length};
for (int i1 = 0; i1 < numArray.length; i1++) {
numArray[i1] = Integer.valueOf(numss[i1]);
}
二维数组xy互换
for (int i1 = 0; i1 < arr.length; i1++) {
for (int i2 = 0; i2 < arr[i1].length; i2++) {
arr2[i1][i2] = arr[i2][i1];
}
}
打印二维数组
for (int i1 = 0; i1 < arr.length; i1++) {
for (int i2 = 0; i2 < arr.length; i2++) {
System.out.print(arr[i1][i2]+" ");
}
System.out.println();
}
一维数组排序,从小到大 冒泡法
int temp;
for (int i1 = 1; i1 < arr.length; i1++) {
if (arr[i1-1] > arr[i1]){
temp = arr[i1-1];
arr[i1-1] = arr[i1];
arr[i1] = temp;
}
}
使用sort方法对数值型数组进行排序
Arrays.sort(intArrays);
关于初始值:
引用变量使用前需要初始化,否则空指针异常;局部变量使用之前必须初始化,否则报错。
单例模式
递归算法
构造方法:用来实现成员变量的初始化操作
- 构造方法的名称与类名相同
- 没有返回值,并不是返回void
- 与new一起使用
- 使用this调用其他构造方法,用super调用超类构造方法
在构造方法中加计数器,实现统计的功能
public static int Counter;
public Person(String name,int age){
this.name = name;
this.age = age;
Counter++;
}
public static int getCounter(){
return Counter;
}
随机获取某范围的数值
new Random().nextInt(10)
重写equals()方法
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Person person = (Person) o;
return (age == person.age) && name.equals(person.name);
}
重写hascode():实际编程中需要重写
一种简单的计算哈希码的方式是将重写equals()方法时使用到的成员变量,乘以不同的指数然后求和,以此作为新的哈希码。
@Override
public int hashCode() {
return name.hashCode() * 7 + new Integer(age).hashCode() * 13;
}
关于hascode()与equals()比较对象创建的两个实例:
hascode()不完全靠谱,equals()全面且复杂,效率比较低。
hascode()不相等,equals()肯定不相等
equals()相等,hascode()肯定相等
所以可以用短路法&&:hascode()结果&&equals()结果
关于逻辑短路&& 、& 、|| 、|
A&&B:只要A是false,则不去执行B,结果为false
A||B:只要A是true,则不去执行B,结果为true
A&B:不管A如何,A、B都会执行
A|B:不管A如何,A、B都会执行
重写toString方法,使用字符串输出对象
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
Person person2 = new Person("夏傲",12);
System.out.println(person2);
引用对象使用=,相当于修改引用,而非堆内的对象
Person person1 = new Person("夏傲",12);
Person person1 = person2;
person1指向person2的堆对象,此时使用set方法,修改对象内容,person1与person2的输出字符串相同,是修改后的值。
将数字格式化为货币字符串
NumberFormat format = NumberFormat.getCurrencyInstance(Locale.CHINA);
System.out.println(format.format(12));
String类格式化当前日期
Date today = new Date();
System.out.println(String.format(Locale.CHINA, "%tb", today));
String 大小写
System.out.println(("AAdhgd").toUpperCase());
System.out.println(("AAdhgd").toLowerCase());
字符串转char字符数组
char[] sarrays = s.toCharArray();
for (char sarray : sarrays) {
System.out.println(sarray);
}
字符串是引用类型,比较需用equals
long类型转字符串
String timeStamp = String.valueOf(System.currentTimeMillis());
System.out.println(Integer.valueOf("123"));
System.out.println(Integer.parseInt("123")); // *
System.out.println(String.valueOf(123));
字符串排序
- compareTo、compareToIgnoreCase,比较结果为正数,则String对象在参数字符串之后;比较结果为负数,String对象在参数字符串之前;比较结果为0,相同
- compareTo区分大小写、compareToIgnoreCase不区分大小写
- 上面写法可以配合冒泡排序法实现对字符串的排序
System.out.println("English".compareTo("Chinese"));
System.out.println("English".compareToIgnoreCase("Chinese"));
System.out.println("ABC".compareTo("abc"));
System.out.println("ABC".compareToIgnoreCase("abc"));
字符串转uniCode编码字符串
public static void convert(String str)
{
str = (str == null ? "" : str);
String tmp;
StringBuffer sb = new StringBuffer(1000);
char c;
int i, j;
sb.setLength(0);
for (i = 0; i < str.length(); i++)
{
c = str.charAt(i);
sb.append("\\u");
j = (c >>>8); //取出高8位
tmp = Integer.toHexString(j);
if (tmp.length() == 1)
sb.append("0");
sb.append(tmp);
j = (c & 0xFF); //取出低8位
tmp = Integer.toHexString(j);
if (tmp.length() == 1)
sb.append("0");
sb.append(tmp);
}
System.out.println(new String(sb));
}
字符串的前缀判断
if (!s.startsWith("xy")){
System.out.println("对不起,您必须输入以xy开头的内容");
}
字符串的后缀判断
endsWith(".txt")
判断字符串是不是数字
if (!isNumber(s)){
System.out.println("您输入的不是数字,请重新输入");
}
字符串匹配+正则表达式:matches()
if (!s.matches("^15[0-9]{9}|13[0-9]{9}|18[0-9]{9}$")){
System.out.println("您输入的手机号码错误,请重新输入");
}
输入字符串,转换成int类型,再转换成二进制、八进制、十六进制,注意判空、是否是数字
if (s.equals("")){
System.out.println("内容不能为空哦");
}else if (!isNumber(s)){
System.out.println("您需要输入整数哦");
}else {
int i = Integer.parseInt(s);
System.out.println(Integer.toBinaryString(i));
System.out.println(Integer.toOctalString(i));
System.out.println(Integer.toHexString(i));
}
判断输入字符串的某个字符是否是字母
public static void charIsLetter(String s){
char[] c = s.toCharArray();
for (char c1 : c) {
if (!Character.isLetter(c1)){
System.out.println("您输入的字符串中含有非字母的字符,请重新输入");
break;
}
}
}
判断某个字符是否是汉字
char[] c = s.toCharArray();
int accout = 0;
for (char c1 : c) {
if (Pattern.matches("^[\u4E00-\u9FA5]{0,}$",String.valueOf(c1))){
accout++;
}
}
System.out.println("一共输入了" + accout + "个汉字");
字符串替换
System.out.println(s.replace(" ", ""));
字符串截取
System.out.println(s.substring(1, 7));
字符构建器,过滤空格
public static void builderString(String s){
StringBuilder stringBuilder = new StringBuilder();
char[] c = s.toCharArray();
for (char c1 : c) {
if (c1==' '){
continue;
}
stringBuilder.append(String.valueOf(c1));
}
System.out.println(stringBuilder.toString());
}
比较Double对象大小
public static void douCompare(Double num1,Double num2){
switch (num1.compareTo(num2)){
case -1:
System.out.println("num1<num2");
break;
case 0:
System.out.println("num1=num2");
break;
case 1:
System.out.println("num1>num2");
break;
}
}
ArrayList集合,添加移除元素打印
List<String> arrayList = new ArrayList<String>();
public boolean listAdd(String s){
if (s.isEmpty()){
return false;
} else{
arrayList.add(s);
return true;
}
}
public boolean listRemove(int i){
if (i <= 0 || i >= arrayList.size()){
return false;
} else if (!arrayList.contains(arrayList.get(i))){
return false;
}else{
arrayList.remove(i);
return true;
}
}
public boolean listRemove(String s){
if (s.isEmpty()){
return false;
} else if (!arrayList.contains(s)){
return false;
}else {
arrayList.remove(s);
return true;
}
}
public void listPrint(){
for (String s1 : arrayList) {
System.out.println(s1);
}
}
抽象类与接口:
接口是一组规则的集合,实现接口的类比较实现其规则。比如数据库表单的增删改查方法。
抽象类用于代码的复用,接口用于实现多态性。
当有2个或多个类有相似之处,可以将其抽离出来做基类,不同之处提取共同特点做抽象方法。子类继承该基类,并实现该抽象方法。抽象类不可以被实例化。
多态的demo:
满足多态的条件:
1.有继承关系【子类继承父类】
2.子类要重写父类的方法【静态方法、非静态方法】
3.父类引用执行子类对象【堆内存中开辟了子类的对象,并把栈内存中的父类的引用指向子类对象】
多态成员访问的特点:
成员变量:编译父类、运行父类
成员方法:编译父类,运行子类
静态方法:编译父类,运行子类
多态的弊端:多态后不能使用子类特有的成员属性和子类特有的成员方法。
多态是对方法的多态,不是属性的多态。
统计字符串每个字符出现的次数,并根据出现的次数排序
1.将字符串转换成字符数组
2.创建HashMap<Character,Integer>,将字符与字符个数以key,value的形式塞入map
3.创建List<HashMap<Character,Integer>>,塞入map数据
4.实现Conparator接口,创建比较器
5.对list进行sort排序
小字符串在大字符串中出现的次数
三种方法:
方法一:String的replace(“替换前的字符串”,“替换后的字符串”),将小字符串删除,利用大字符串删除前后的长度差/小字符串长度得出
方法二:理解String的indexOf()方法,indexOf(String)表示:从索引0开始检索,有匹配的对象,返回匹配项最左侧的索引值。返回-1代表检索一遍没有匹配项。
indexOf(String,index),从特定的索引值开始检索
subString(beginIndex):从beginIndex开始截断,取右侧的String值;配合indexOf(String)使用。
英文句子倒序输出
单词不用倒序,单词与单词之间倒序
思路:String切片成String数组,放入切片的结果;数组倒序输出;打印数组成英文句子。
一维数组反转
for (int i1 = 0; i1 < intArray.length/2; i1++) {
temp = intArray[intArray.length -1-i1];
intArray[intArray.length -1-i1] = intArray[i1];
intArray[i1] = temp;
}
String内存分析:引用类型的变量
https://blog.csdn.net/qq_33267676/article/details/78132330
1.String是final类,不可被继承,不可变,其成员方法也都是被final修饰,所以所有针对字符串的操作,都是在新创建的对象上改变的,原字符串不变;String字符串的本质是字符数组;
总结:String对象一旦被创建就是固定不变的了,对String对象的任何改变都不影响到原对象,相关的任何change操作都会生成新的对象。
2.字符串常量池:使用字符串常量池的目的是JVM为了提高性能和减少内存的开销
做法:每次创建字符串常量,会先检查字符串常量池,存在,直接返回常量池的实例引用,不存在,实例化字符串并且将其放入常量池。
比如:String s1 = “qqq”;String s2 = “qqq”
但new关键字,一定会去创建对象。与上面要区分开
String s3 = s1+s2;其中: s1+s2,引用变量相加,创建了新对象,指向堆,所以这边的s3!=“qqqqqq”
但:如果s1和s2被final修饰,作用相当于两个字面常量的连接
但 String s4 = “a”+1,如果连接的值是字面常量,在编译器,字符串常量就已经确定了,所以s4 = “a1”
常量池种类:静态常量池(*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类、方法的信息,占用class文件绝大部分空间)、运行时常量池(jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池)
字符串池的优缺点?
字符串池的优点就是避免了相同内容的字符串的创建,节省了内存,省去了创建相同字符串的时间,同时提升了性能;另一方面,字符串池的缺点就是牺牲了JVM在常量池中遍历对象所需要的时间,不过其时间成本相比而言比较低。
3.引用变量与对象
4.equals与==:equals是否指向同一个对象,String重写equals方法,比较是否指向同一个对象,且指向的字符串对象所存储的字符串是否相等;
5.String、StringBuffer、StringBuilder
当字符串相加操作或者改动较少的情况下,建议使用 String str="hello"这种形式;
当字符串相加操作较多的情况下,建议使用StringBuilder,如果采用了多线程,则使用StringBuffer
6.String str = new String(“abc”)创建了多少个对象?
代码执行过程中创建了一个String对象,运行时,在常量池创建了一个"abc"对象。这边合理的回答应该是创建了一个对象,涉及到了两个对象。
常用的集合有哪些,如何遍历map(手写),map有什么特性
集合有哪些?https://blog.csdn.net/zhanyufeng888/article/details/82498054
Set、List、Map
(1)Set
- 属于单列集合,不允许包含重复元素
- 判断元素是否重复的标砖为对象的equals方法,存在时返回false,不存在返回true
- 元素的排序规则,由相应的实现类决定,分为无序、元素大小排序、写入顺序排序
- 初始化大小,扩容参考HashMap
(2)List - List集合属于单列、有序的、允许元素重复、可以为null的集合
- List接口的实现类主要有三种:ArrayList、LinkedList、Vector
(3)Map - 双列key-value键值对集合,key不允许重复,是否允许为null,根据实现类而定,value随意
遍历map?
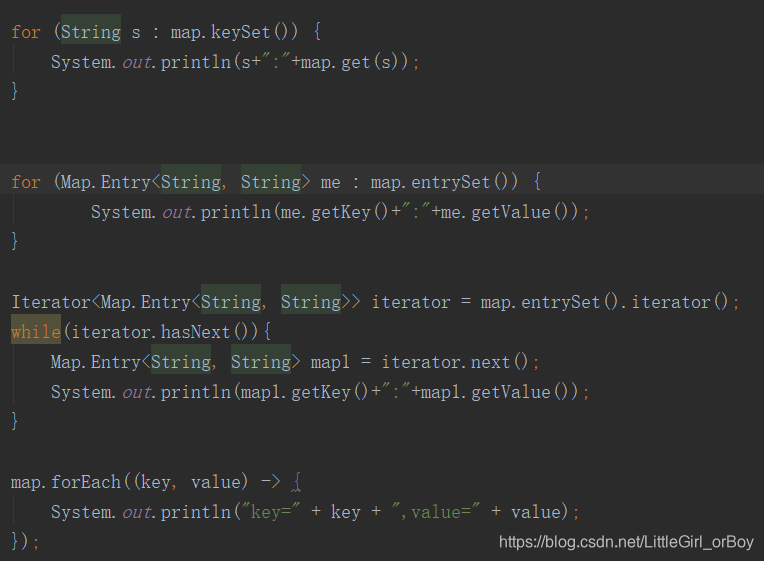
map特性?
- 添加元素 put(key,value)
- 删除元素 clear()删除所有的键值对、remove(key)根据键删除键值对元素,并且返回值
- 判断功能containsKey(key)、contains(value)、isEmpty()判断集合是否为空
- 获取元素功能Set<Map.Entry<k,v>> entrySet() 、get(key)、Set keySet()、Collection values()
- Map集合遍历
ArrayList与LinkedList各自特点,为什么会有所不同?
ArrayList 查询快,增删慢【这样说其实是有错误的,准确的应该是“随机”】
LinkedList 查询慢,增删快【这样说其实是有错误的,准确的应该是“随机”】
ArrayList :基于动态数组接口,随机查询快,随机增删相较于LinkedList慢
LinkedList:双向链表结构,随机增删快,随机查询慢
LinkedList是链表结构,何为链表?就是元素之间的所有关系是通过引用关联的,比如说一节车厢,你只能知道当前车厢的上一节车厢是什么,当前车厢的下一节车厢是什么,这样,它在查询的时候,只能一个一个的遍历查询,所以他的查询效率很低,如果我们想删除一节车厢怎么办呢?就相当于自行车的链子,有一节坏了,我们是不是直接把坏的那节仍掉,然后让目标节的上一节指向目标节的下一节,增加同样,假如有abc三节车厢,你想在b后面增加车厢,那么只需要让目标车厢的上一节指向b,让目标车厢的下一节指向c,别的元素不动,所以它的增删在理论上比较快!
ArrayList是数组结构,何为数组?就是有相同特性的一组数据的箱子,比如说我有一个能容下10个苹果的箱子,我现在只放了5个苹果,那么放第6个是不是直接放进去就行了?呢我要放11个呢?这个箱子是不是放不下了?所以我是不是需要换个大点的箱子?这就是数组的扩容!同样,我们一般放箱子里面的东西是不是按照顺序放的?假如说是按abcd的顺序放的,我突然想添加一个e,这个e要放到c的后面,你是不是需要把d先拿出来,再把e放进去,再把d放进去?假如说c后面有10000个呢?你是不是要把这10000个都拿出来,把e放进去,再放这10000个?效率是不是很低了?所以,理论上它的增删比较慢!但是前面也说了,我们箱子里面放东西,都是按照顺序放的,所以我知道其中一个"地址",是不是就知道所有元素的地址?所以它的查询在理论上比较快!
HashSet与TreeSet区别
HashSet 实现类 线程不同步 继承了AbstractSet类,实现了Set、Cloneable、Serializable接口
TreeSet 实现类 线程不同步 继承AbstractSet,实现了NavigableSet(继承SortedSet)、Cloneable、Serializable接口
Set中元素不重复,无序(也就是元素输入的顺序,不是输出的顺序)
HashSet:内部的数据结构是哈希表,线程不安全。
保证集合中元素是唯一的方法,是通过对象的hashCode和equals方法来完成对象唯一性的判断。
TreeSet 的底层实现是采用红-黑树的数据结构,采用这种结构可以从Set中获取有序的序列,但是前提条件是:元素必须实现Comparable接口,该接口中只用一个方法,就是compareTo()方法。当往Set中插入一个新的元素的时候,首先会遍历Set中已经存在的元素,并调用compareTo()方法,根据返回的结果,决定插入位置。进而也就保证了元素的顺序。
compareTo方法
接口Comparable,定义了一个compareTo(Object obj)方法,该方法返回一个整数值。当一个对象调用该方法与另一个对象进行比较时,例如obj1.compareTo(obj2),如果该方法返回0,则表示两个对象相等,如果该方法返回一个正整数,则表明obj1大于obj2;如果该方法返回一个负整数,则表明obj1小于obj2。
一些实现了Comparable接口的常用类:
BigDecimal类、BigInteger以及所有的数值型对应的包装类:按他们对应的数值大小进行比较
Character:按照字符的UNICODE值进行比较
Boolean:true对应的包装类实例大于false对应的包装类实例
String:按照字符的UNICODE值进行比较
Date\Time:后面的时间、日期比前面的时间、日期大
HashMap与TreeMap的区别与相同点
1.HashMap与TreeMap都继承AbstractMap,但HashMap实现了Map接口,TreeMap实现了NavigableMap接口,NavigableMap是SortedMap的一种,实现了对Map中key的排序,所以TreeMap是排序的,HashMap不是
2.Null值的区别,HashMap允许一个null key和多个null value,TreeMap不允许null key,允许多个null value
3.性能区别:HashMap的底层是Array,所以在添加、查找、删除等方法上速度快,TreeMap的底层是一个Tree结构,所以速度比较慢。
HashMap因为要保存一个Array,所以会造成空间的浪费,而TreeMap只保存要保持的节点,所以占用空间小
HashMap如果出现hash冲突的话,效率会变差,java 8 中进行TreeNode转换,效率有很大提升
TreeMap在添加和删除节点的时候会进行重排序,会对性能有所影响。